Prologika Newsletter Winter 2015
Power BI and You
 I’m excited to announce the availability of my latest (7th) book – Applied Microsoft Power BI! Currently, this is the only book on Power BI. The book page has more information about the book, including the front matter (with foreword by Jen Underwood), source code, and a sample chapter (Chapter 1 “Introduction to Power BI”). You can order the paper copy on Amazon, and soon on other popular retail channels. I predict that 2016 will be the year of Power BI and I hope that this book will help you to take the most out of it and bring your data to life! And if you’re looking for instructor-led training on Power BI and Microsoft BI, please check our training classes.
I’m excited to announce the availability of my latest (7th) book – Applied Microsoft Power BI! Currently, this is the only book on Power BI. The book page has more information about the book, including the front matter (with foreword by Jen Underwood), source code, and a sample chapter (Chapter 1 “Introduction to Power BI”). You can order the paper copy on Amazon, and soon on other popular retail channels. I predict that 2016 will be the year of Power BI and I hope that this book will help you to take the most out of it and bring your data to life! And if you’re looking for instructor-led training on Power BI and Microsoft BI, please check our training classes.
Let’s face it. Without supporting data, you are just another person with an opinion. But data is useless if you can’t derive knowledge from it. And this is where Power BI can help you. While writing the book and helping customers use Power BI, I’m astonished by its breath of features and the development momentum Microsoft has put behind it. The Power BI cloud service gets major features every week, while Power BI Desktop is updated every month! Although this makes it hard for people like me who are writing books, it’s a great value proposition for you.
Not to mention that Power BI has the best business model: most of it it’s free! Power BI Desktop and Power BI Mobile are free. Power BI Service is free and has a Power BI Pro subscription option that you could pay for, following a freemium model. Cost was the biggest hindrance of Power BI, and it’s now been turned around completely. You can’t beat free! In this newsletter, I’ll revisit how Power BI can benefit different users in your organization.

Power BI for Business Users
To clarify the term, a business user is someone in your organization who is mostly interested in consuming BI artifacts, such as reports and dashboards. Business users can utilize Power BI to connect to popular cloud services, such as Salesforce, Marketo, Google Analytics, Dynamics CRM, and many more. With a few clicks, a business user can use content packs to connect to cloud data and gain insights from predefined reports and dashboards, and create custom reports. Other cloud-hosted providers build profitable businesses around SaaS cloud BI but Power BI does it for free!
With a few clicks, business users can analyze data from files and cubes without having to create data models. And they can also view Power BI dashboards and reports on mobile devices so they are always informed while they are on the go. Again, all of this for free!
Power BI for Data Analysts
A data analyst or BI analyst is a power user who has the skills and desire to create self-service data models. Leveraging the Microsoft’s prior investment in Power Pivot, Power View, and Power Query, Power BI lets business analysts import data form virtually everywhere and create sophisticated self-service models whose features are on a par with professional models and cubes. And now that we have a native support for many-to-many relationships, there shouldn’t be a requirement you can’t meet with Power BI.
As a data analyst you have a choice about your toolset because you can create models in both Excel or in Power BI Desktop. While other vendors charge hefty licensing fees for desktop modeling tools, Power BI Desktop is free and it gets updates every month! Think of Power BI Desktop as the unification of Power Pivot, Power Query, and Power View. Previously available as Excel add-ins, these tools now blend into a single flow. No more guessing which add-in to use and where to find it! Because many data analysts use R to data analysis and statistics, Power BI recently added support for R scripts and visualizing data using the R plotting capabilities.
Power BI for Pros
BI pros and IT pros have much to gain from Power BI. An IT pro can establish a trustworthy environment that promotes sharing of BI artifacts. To do so, IT can set up Power BI workspaces that allow authorized users to see the same BI content. If IT needs to distribute BI artifacts to a wider audience, such as the entire organization, she can create an organizational content pack and publish it to the Power BI Content Gallery. Then her coworkers can search, discover, and use the content pack. And IT can set up an organizational gateway to centralize and grant access to on-premises data.
The scenario that BI pros will probably be most excited about is hybrid BI solutions, where the report definitions (not data) is hosted in Power BI but corporate data remains in relational databases and cubes. This is a scenario that Prologika is planning for a cloud-averse Fortune 10 company in order to empower their users with mobile reports and dashboards. But that’s not all! BI pros can also implement predictive and real-time solutions that integrate with Power BI, and book has the details.
Power BI for Developers
Power BI has plenty to offer to developers as well because it’s built on an open and extensible architecture that embraces popular protocols and standards, such as REST, JSON, and oAuth. For years, Microsoft didn’t have a good solution for embedding interactive reports in custom apps. Power BI enables this scenario by allowing developers to embed dashboard tiles and interactive reports. Soon it will also support custom authentication.
Microsoft has also published the required “custom visuals” interfaces to allow developers to implement and publish custom visuals using any of the JavaScript-based visualization frameworks, such as D3.js, WebGL, Canvas, or SVG. Do you need visualizations that Power BI doesn’t support to display data more effectively? With some coding wizardry, you can implement your own, such as the Sparkline visual that I published to the Power BI visuals gallery!
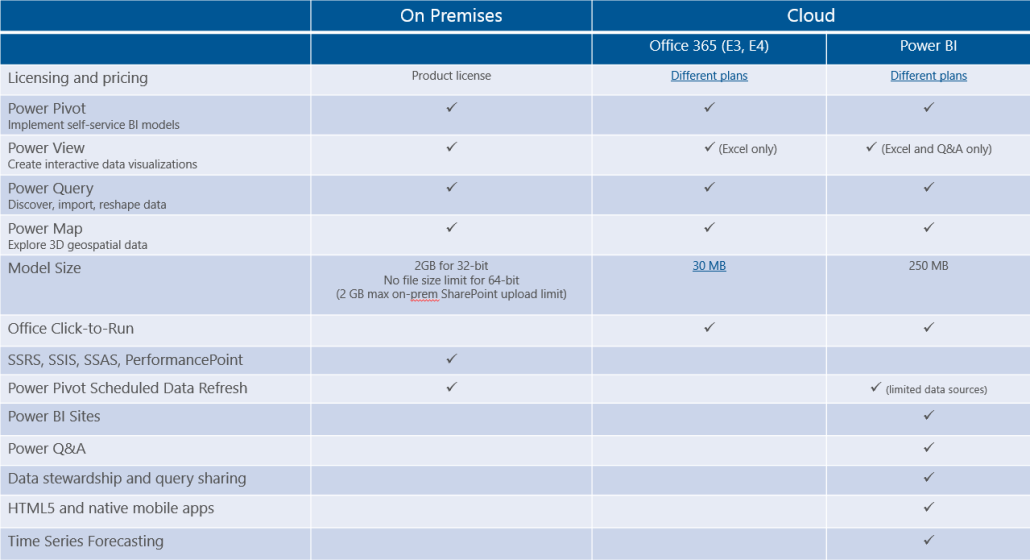
In summary, no matter what data visualization or data analytics requirements you have, Power BI should be at the forefront and you ought to evaluate its breath of features. Remember that Power BI is a part of a holistic vision that Microsoft has for delivering cloud and on-premises data analytics. When planning your on-premises BI solutions, consider the Microsoft public reporting roadmap. Keep in mind that you can use both Power BI (cloud-based data analytics) and the SQL Server box product on-premises to implement synergetic solutions that bring your data to life!
As you’d probably agree, the BI landscape is fast-moving and it might be overwhelming. If you need any help with planning and implementing your next-generation BI solution, don’t hesitate to contact me. As a Microsoft Gold Partner and premier BI firm, you can trust us to help you plan and implement your data analytics projects, and rest assured that you’ll get the best service.
Regards,
Teo Lachev
President and Owner
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
EVENTS & RESOURCES
 Prologika: “Applied Microsoft Power BI Service” book by Teo Lachev
Prologika: “Applied Microsoft Power BI Service” book by Teo Lachev
SQL Saturday BI: “What’s New for BI in SQL Server 2016” presentation by Teo Lachev and “Introduction to R” presentation by Neal Waterstreet on 1/9/2016
Atlanta BI Group: Power BI presentation by Patrick LeBlanc on 1/25/2016
 Before we get to the subject of this newsletter, I’m happy to announce the availability of my latest class –
Before we get to the subject of this newsletter, I’m happy to announce the availability of my latest class – 
 A while back I met with a client that was considering overhauling their BI. They asked me if the traditional data warehousing still makes sense or should they consider a logical data warehouse, Big Data, or some other “modern variant”. This newsletter discusses where data warehousing is going and explains how different data architectures complement instead of compete with each other.
A while back I met with a client that was considering overhauling their BI. They asked me if the traditional data warehousing still makes sense or should they consider a logical data warehouse, Big Data, or some other “modern variant”. This newsletter discusses where data warehousing is going and explains how different data architectures complement instead of compete with each other.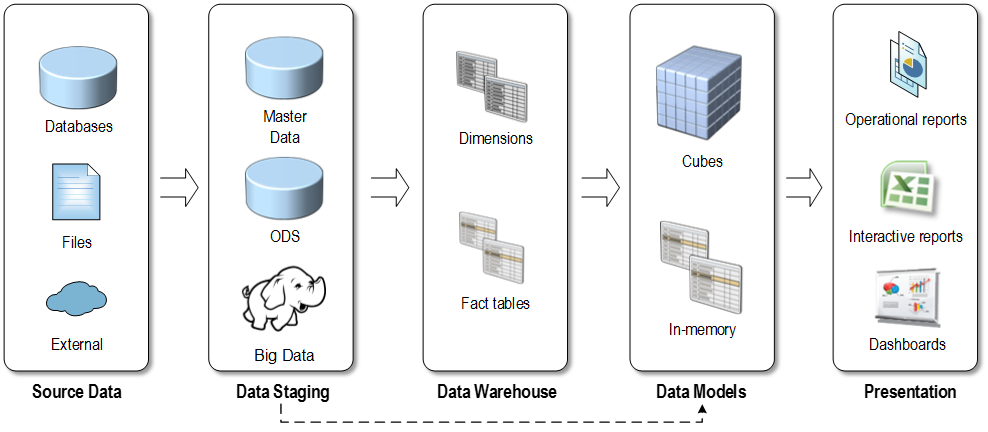
 After an appetizer of embedded Power View reports , Microsoft proceeded to the main course that is a true Christmas gift – a
After an appetizer of embedded Power View reports , Microsoft proceeded to the main course that is a true Christmas gift – a 
 As I’m enjoying my vacation in tropical Cancun, Mexico, I hope you’ve been enjoying the holidays and planning your BI initiatives in 2014. Speaking of planning, you may have heard that Microsoft is working hard on next release of SQL Server, version 2014, which is expected in the first half of next year. Naturally, you may wonder what’s new in the forthcoming release in the BI arena. If so, keep on reading.
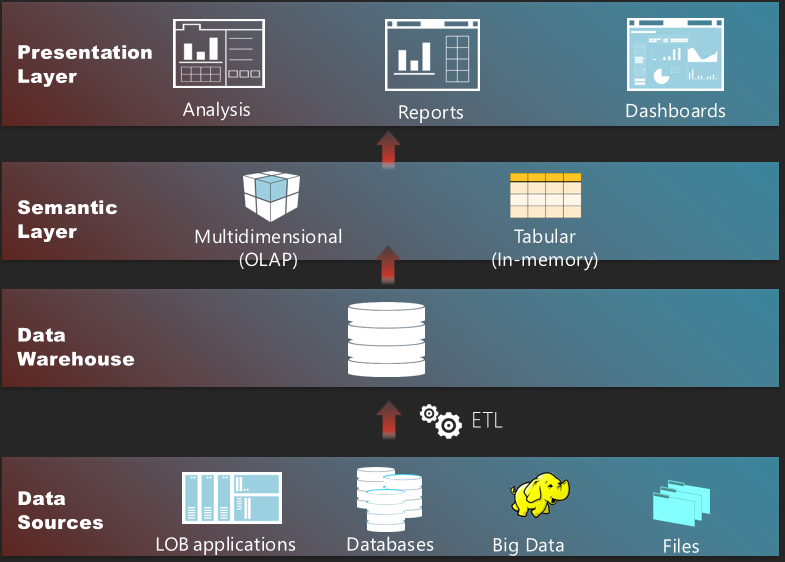
As I’m enjoying my vacation in tropical Cancun, Mexico, I hope you’ve been enjoying the holidays and planning your BI initiatives in 2014. Speaking of planning, you may have heard that Microsoft is working hard on next release of SQL Server, version 2014, which is expected in the first half of next year. Naturally, you may wonder what’s new in the forthcoming release in the BI arena. If so, keep on reading. I hope you had a great summer. The chances are that your organization has a centralized data repository, such as ODS or a data warehouse, but you might not use it to the fullest. Do you want a single version of truth? Of course, you do. Do you want to empower your business users to create their own reports and offload reporting effort from IT? I bet this is one of your top requirements. A semantic layer could help you achieve these objectives and much more… In this newsletter, I’ll discuss the importance of having a semantic layer that bridges users and data.
I hope you had a great summer. The chances are that your organization has a centralized data repository, such as ODS or a data warehouse, but you might not use it to the fullest. Do you want a single version of truth? Of course, you do. Do you want to empower your business users to create their own reports and offload reporting effort from IT? I bet this is one of your top requirements. A semantic layer could help you achieve these objectives and much more… In this newsletter, I’ll discuss the importance of having a semantic layer that bridges users and data.