Fabric Lakehouse: The Good, The Bad, and the Ugly
“Hey, I got this lake house, you should see it
It’s only down the road a couple miles
I bet you’d feel like you’re in Texas
I bet you’ll wanna stay a while”
Brad Cox
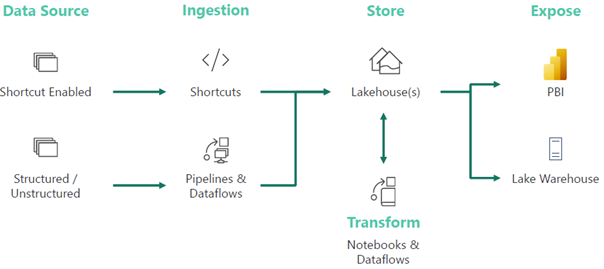
Continuing our Fabric purview, Lakehouse is now on the menu. Let’s start with a definition. According to Databricks which are credited with this term, a data lakehouse is “a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.” Further, their whitepaper “argues that the data warehouse architecture as we know it today will wither in the coming years and be replaced by a new architectural pattern, the Lakehouse, which will (i) be based on open direct-access data formats…” In other words, give us all of your data in a delta lake format, embrace our engine, and you can ditch the “legacy” relational databases for data warehousing and OLAP.
The Microsoft’s Lakehouse definition is less ambitious and exclusive. “Microsoft Fabric Lakehouse is a data architecture platform for storing, managing, and analyzing structured and unstructured data in a single location. It is a flexible and scalable solution that allows organizations to handle large volumes of data using a variety of tools and frameworks to process and analyze that data. It integrates with other data management and analytics tools to provide a comprehensive solution for data engineering and analytics”. In other words, a lakehouse is whatever you want it to be if you want something better than a data lake.
The Good
I like the Microsoft lakehouse definition better. Nobody forces me to adopt an architectural pattern that probably won’t stand the test of time anyway.
If I must deal with files, I can put them in the lakehouse unmanaged area. The unmanaged area is represented by the Files virtual view. This area somehow escapes the long-standing Power BI limitation that workspaces can’t have subfolders and therefore allows you to organize the files in any folder structure. And if I want to adopt the delta lake format, I can put my data in the lakehouse managed area, which is represented by the Tables virtual view.

Further, the Fabric lakehouse automatically discovers and registers delta lake tables created in the managed area. So, you can use a Power Query dataflow or ADF Copy Activity to write some data in a delta lake format and Fabric will register the table for you in the Spark metastore with the necessary metadata such as column names, formats, compression and more (you don’t have use Spark to register the table). Currently, the automatic discovery and registration is supported only for data written in the delta lake format.
You get two analytical engines for the price of one to query the delta tables in the managed area. Like Synapse Serverless, the SQL endpoint lets users and tools query the delta tables using SQL. And the brand new DirectLake mode in Analysis Services (more on this in a future post) lets you create Power BI datasets and reports that connect directly to the delta tables with blazing speed so you don’t have to import to get better performance.
Finally, I love the ability to shortcut lakehouse tables to the Data Warehouse engine and avoid data movement. By contrast, previously you had to spin more ETL to move data from Synapse serverless endpoint to the Synapse dedicated pools.
The Bad
As the most lake-like engine, Fabric lakehouse shares the same limitations as the Fabric OneLake which I discussed in a previous post.
Going quickly through the list, the managed area (Tables) can’t be organized in subfolders. If you try to paint outside the “canvas”, the delta tables will end up in an Unidentified folder and they won’t be automatically registered. Hopefully, this is a preview limitation since I don’t see you can implement a medallion file organization if that’s your thing. Further, while you can create delta tables from files in the unmanaged area, the tables are not automatically synchronized with changes to the original files. Automatic delta table synchronization could be very useful that I hope will make its way to the roadmap.
The Microsoft API wrapper that sits on top of OneLake is married to the Power BI security model. You can’t overwrite or augment the security permissions, such as by granting ACL permissions directly to the lakehouse folders. Even Shared Access Signature is not allowed. Storage account key is not an option too as you don’t have access to the storage account. So, to get around such limitations, you’d have to create storage accounts outside Fabric, which defeats the OneLake vision.
It’s unclear how Fabric would address DevOps, such as Development and Production environments. Currently, a best practice is to separate all services so more than likely Microsoft will enhance Power BI pipelines to handle all Fabric content.
The Ugly
Given that both the lakehouse and data warehouse (new Synapse) have embraced delta lake storage, it’s redundant and confusing to have two engines.
The documentation goes in length to explain the differences but why the separation? Based on what I’ve learned, the main reason is related to ADLS limitations to support important SQL features, including transactions that span multiple tables, lack of full T-SQL support (no updates, limited reads) and performance issues with trickle transactions. Hopefully, one day these issues will be resolved and the lakehouse and data warehouse will merge to give us the most flexibility. If you know SQL, you’d use SQL and if you prefer notebooks, you can use the Spark-supported languages to manipulate the same data.



