Notes on Fabric F2 Performance: Warehouse ETL
As inspired by Amir Netz‘s encouragement to partners to test the Fabric F2 capacity performance, I got on a quest to test what it would do to ETL loads for Fabric Warehouse. I must admit that I was skeptical that a quarter of a core would take a warehouse off the ground, but as usual, life proved me wrong and “wrong” is a big understatement of what happened.
After provisioning a Fabric F2 capacity and a warehouse, I settled on the Retail Data Model for World Wide Importers sample star schema dataset consisting of five dimension tables and one fact table. In terms of performance, I was mostly interested in how long it would take for the ADF copy activity to insert all the data (50 million rows) in the fact table. Granted, it’s a limited test but enough to rule out the technology for real-life projects. Then, I compared the performance against Azure SQL Database Serverless running on up to 2 cores and provisioned by the free trial offer that Microsoft has on Azure. To exclude impact on data transfer between regions, both technologies were provisioned on East US 2 data region, which is the region where my Power BI tenant is hosted on.
Much to my surprise, it took less than two minutes to load all 50 million rows in F2, whereas it took 1 hour to load to load 27 million rows to Azure SQL Database before the maximum 30 GB disk space was exhausted! I couldn’t believe it so I ran the test three times to confirm. Surely, bursting helps a lot! Now, throughput would be a different story, but as far as the warehouse is concerned, it doesn’t matter because in most cases, data will be imported in a Power BI semantic model and the warehouse will be out of the picture. As a next step, I plan to test the report throughput to see what concurrent report load would saturate the F2 capacity.
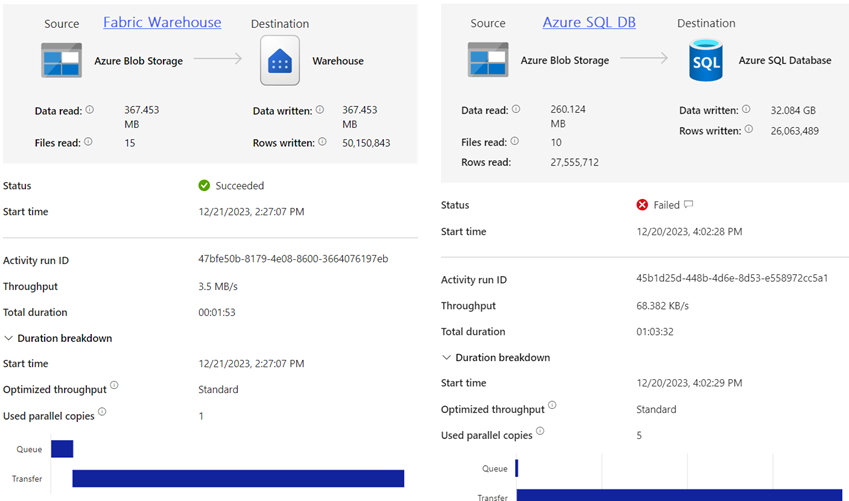
In conclusion, the Fabric lowest capacity F2 ($262.80 monthly cost) could be a viable option for smaller organizations willing to make their foray in the Fabric world. On the downside, we must leave Fabric to marinate for a few months and add needed features, including surrogate keys and MERGE for Warehouse and on-prem connectivity for Azure Data Factory, in order to be in consideration for real-life projects. More tests are needed to gauge the F2 report throughput.
UPDATE 12/24/2023 I was curious how much loading the same dataset from a CSV file would impact performance. It took much longer: 18 minutes. The most significant factor was that loading from CVS requires staging to a data lake although this appears redundant because the CVS file was in a lakehouse in the same Power BI workspace. ADF spent a total of 18 minutes in the two-staged copy (ten minutes to stage the data and eight minutes to load the fact table from the staged copy). Therefore, Parquet outperformed significantly CVS, probably because the Microsoft-provided Parquet file was compressed.


