The Analysis Services server parses the cube script on deploy and complains in case of missing dimension members. You can use the IsError() function to handle missing members, such as Iif(IsError([Account].[Accrual Basis].&[30/360]), null, ([Account].[Accrual Basis].&[30/360]). However, sometimes you might want to ignore the default missing member behavior. For example, an ISV deploying a cube to different customers might prefer to ignore missing members if there are many member references in the cube. In this case, you can see the ScriptErrorHandlingMode cube-level property to IgnoreAll. The unfortunate side effect of doing so is that any scope assignment that references a missing member will be invalidated. For example, suppose you have the following scope assignment:
This assignment changes the cube space for all accounts with Open and Pending status. But what happens if the [Account].[Status].&[Pending] member doesn’t exist? The scope assignment simply doesn’t work. Since in this case, a set is used to specify the account status, you cannot use IsError(). One workaround is to use the Filter() function as follows:
Scope
(
Filter([Account].[Account].[Account].Members, [Account].[Account].Properties(“Status”) = “Open” OR [Account].[Account].Properties(“Status”) = “Pending”)
);
this = … ;
End Scope;
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2010-04-29 01:59:012016-02-17 05:42:58Scope Assignments and Missing Members
I have to admit that I am a performance buff. In a previous blog, I mentioned that the Xperf utility can help you gain additional understanding about the Analysis Services performance. Akshai Mirchandani from the SSAS team was kind enough to share his performance testing experience and recommended this utility. It turns out he was right – it is a real gem! Just after writing that blog, an opportunity presented itself. A business user complained that drilling down a member in an Excel PivotTable report takes about 20 seconds on a virtual test server. This inspired me to take XPerf for a spin. In this case, the database was relatively small but the user has requested two parent-child dimensions on the report with some 3,500 and 300 members each. As you probably know, parent-child dimensions are slow by nature. To make things worst both dimensions had many-to-many relationships. The SQL Profiler would show that almost the entire time was spent reading data from partitions. However, I was interested to find out how much time was spent in actual I/O vs. aggregating data to make specific performance recommendations. The findings were interesting. Here are the steps I followed to test the performance using XPerf on the virtual server running Windows Server 2008:
I downloaded the Microsoft Windows SDK for Windows 7. Although it’s for Windows 7, it can run on Windows Server OS as well. When I ran the web install, I selected the Win32 Development Tools option only to reduce the size of the download.
Once installed, I ran Install Windows Performance Tool Kit (x64) found in the Microsoft Windows SDK v7.0 -> Tools program group and accepted the default options.
I ran the command prompt with elevated privileges (Run As Administrator) and started a trace with the default configuration. C:\Program Files\Debugging Tools for Windows (x64)>xperf -on DiagEasy
In Excel, I drilled down to expand a member of one of the parent-child dimensions that was particularly slow.
Once Excel was done executing the query, I stopped the trace and saved the results in a file mytrace.etl. C:\Program Files\Debugging Tools for Windows (x64)>xperf -d mytrace.etl
Double-clicked the mytrace.etl file which was saved in the C:\Program Files\Microsoft Windows Performance Toolkit folder to open in the Windows Performance Analyzer. This is where the fun starts!
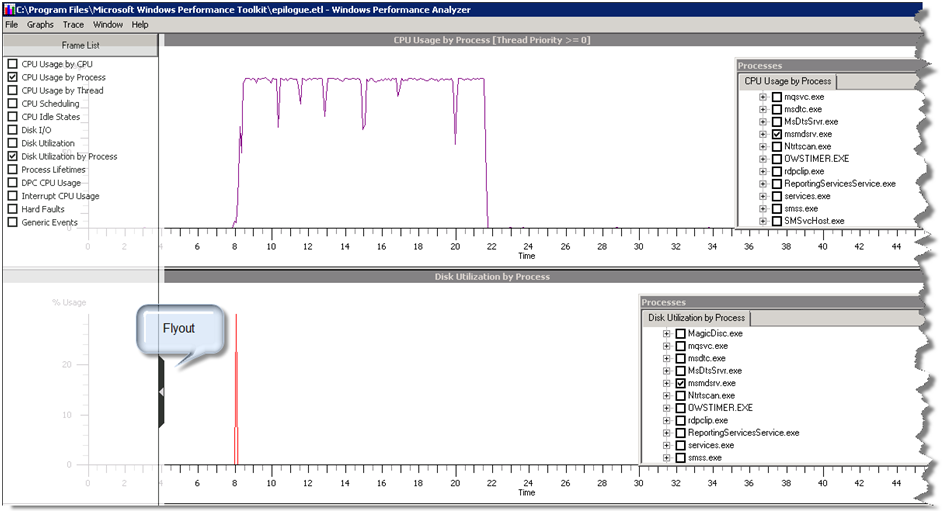
Since I was interested in disk utilization and CPU usage, I clicked on the Flyout glyph and checked these options to have two graphs only.
On each graph, I expanded the Processes panel and left only msmdsrv.exe checked to filter the trace results for Analysis Services server only.
At this point, I couldn’t believe my eyes! As you could see, the server spent a fraction of a second to read from disk. The remaining time was spent in number crunching to aggregate the results. To see the actual metric, I selected the I/O peak, right-clicked and clicked Summary Table. This showed that the server spent 29ms to read only 118,784 bytes from disk which makes sense (as I said the database is small). In summary, this particular case could benefit much more from more CPU power and potentially more CPUs since the storage engine is highly parallel.
As you can see, Xperf can help you gain important performance details that are not available in SQL Profiler. In this blog, I only scratched the surface of what XPerf can do for you. One very interesting feature is stack walking that gives you a breakdown in time spent per function call assuming you have the debug symbols loaded. The stack waking feature is explained in more details in this Windows Performance Toolkit – Xperf blog. Of course, it could have been nice if the SQL Profiler gives you more detailed tracing information so you don’t have to rely on Xperf, e.g. Reading Data From Disk Begin/End, Data Cache Population Begin/End, Storage Engine Work Begin/End, Formula Engine Work Begin/End. So, vote here.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2010-04-16 22:34:002016-02-17 05:50:47Using XPerf to Test Analysis Services
A couple of years ago I was working on a KPI dashboard project where we had to display a bunch of KPIs produced by counting (distinct count) number of customers, accounts, etc. Even with SSAS 2008 we couldn’t much to optimize the queries to render the page in a few seconds because we found that 50% of the execution time was spent in the storage engine. We flirted with the idea of using solid state disks (SSD) but back then there were not that popular.
A recent feedback from other MVPs and members of the SSAS team suggests that in general SSD are favorable for optimizing the SSAS I/O performance. As you would imagine, the more time the Storage Engine (SE) spends in reading data from disk, the more performance improvement you would expect by switching to faster disks. But then the question becomes how much time SSAS really spends reading data from disk. As it turns out, the SQL Profiler doesn’t give you the answer. That’s because the Started/Finished reading data from the partition events include also the time spent in aggregating data and this time may be significant especially in the case of parent-child or many-to-many dimensions. So, judging from the SQL Profiler alone, you may think that most of the query time is spent in I/O where faster disks may help while it may turn out that you may need more CPU power.
Since as it stands the SQL Server Profiler doesn’t break down the SE time, you need to rely on Windows performance counters to find how much time was spent in actual I/O. Event Tracing for Windows (ETW) can give you such information. For example, on Windows 2008 and Windows 7 you can use the Xperf tool from the Windows Performance Toolkit. The following resources should get you started with Xperf:
As you will find out, the information emitted by XPerf could be overwhelming to answer a simple question. I posted a feedback on connect for a future release of SSAS to include more detailed tracing about the SE inner workings. This information should be available in SE so it shouldn’t be that difficult to break down the Progress Begin/End reports so customers know if they should scale up in terms of CPU or I/O. Please vote for it if you find it useful.
Here is another one of those “by design” issues (see the Not All Calculated Members Are Born Equal blog for another recent gotcha) that are not documented but can sure waste you precious time figuring out. The issue was first submitted on connect.microsoft.com by Greg Galloway almost a year ago where it was left in an investigation phase (what can we do to get the SSAS team actually review the connect cases and post findings?). Then, I submitted a similar issue and official support case since I was 100% sure it was a bug and I needed a closure. Alas, Microsoft came back to declare it “by design”:
“…per feedback from several AS 2005 Beta customers, for compatibility with pre-existing AS 2000 behavior, AS 2005 RTM (and later releases) was changed to not include hidden calculated members in cell calculations and scopes (except when a hidden calculated member is explicitly referenced in the calculation scope).”
The issue affects hidden calculated members and scope assignments where a scope assignment simply ignores hidden calculated members if they are not explicitly referenced by the script. You can easily repro the issue by making the following changes to the Adventure Works script:
/*– Allocate equally to quarters in H2 FY 2005 ————————*/
CREATE MEMBER CURRENTCUBE.[Measures].[Visible Quota] AS null,
Here, I created two identical calculated members with the only difference that the first one is visible and second one hidden. Then, execute the following query:
SELECT {[Measures].[Sales Amount Quota], [Measures].[Visible Quota], [Measures].[Invisible Quota]} on 0
FROM [Adventure Works]
WHERE [Date].[Fiscal].[Fiscal Quarter].&[2005]&[1]
And here are the results (surprise!):
The Visible Quota member is populated as it should be but Invisible Quota refuses to budge as the script simply ignores it. If the script scopes on the Invisible Quota member explicitly or you make it visible, then we get the expected results. Since the issue is by design and a fix won’t be available anytime soon, you should be very careful when you use hidden calculated members and expect them to be affected by scope assignments. I use often helper calculated members which I hide since they shouldn’t be visible to the end users. This issue hit me really hard after QA reported wrong results and your humble correspondent had to debug a cube with some 1000+ lines of code.
You can use the Microsoft Connect website to find most requested features. Unfortunately, the search doesn’t let you specify a product so the search results may be related to other products. For example, searching on reporting services may bring in results from Analysis Services and reporting. Nevertheless, it was quite interesting to find the top voted suggestions. For example, the following query shows the top suggestions for Reporting Services (flip to the Suggestions tab):
Don Demsak pointed out another Silverlight-based control from Infragistics, which is currently in a CTP phase. There are actually two controls: XamWebDataChart and XamWebPivotGrid. I played a bit with it and it looks great. I liked the Excel-like paradigm with the metadata pane on the right and the PivotChart and PivotTable synchronized. As I’ve been saying – give me a Silverlight-based Excel Pivot and I am happy.
See my previous blog about the Intelligencia for Silverlight which is another Siliverlight-based control for Analysis Services.
Analysis Services leads the OLAP server market and it should be your platform of choice for historical and trend reporting. In the spirit of the season, here is my Top 10 Wish List for Analysis Services. All items are related to regular cubes and none to PowerPivot which I am yet to try.
Improved client support – No 1 on my list has nothing to do with the server itself but with how well the Microsoft-provided clients support Analysis Services. To its credit, Microsoft continues improving the Excel OLAP support but still there are major functionality gaps from one tool to another. This is especially evident in the area of Reporting Services (see my No 1 SSRS wish list item). I am not sure if that’s possible from a technical standpoint but I wish the SSAS team re-factors the query generation logic into a MDX Query Generator binary of some kind which all tools can share to produce the same results consistently.
Focus on UDM (aka Corporate BI) – Although I see some useful scenarios for self-serviced OLAP with PowerPivot (previously known as Gemini), for various reasons I believe the focus should stay on UDM which now Microsoft refers to as Corporate BI. First, the business problems that I solve with UDM exceed by far Gemini’s capabilities. Second, if not a single source for reporting and a single version of the truth, I believe UDM should handle 80-90% of the reporting needs. Finally, based on my experience, data acquisition is the most difficult thing. This is why we have a dimensional model which IT would put together. But once data is cleaned and transformed, building UDM on top of it shouldn’t take that long
Silverlight OLAP Viewer control – A Silverlight-based control that ships with Visual Studio to let developers embed an Excel-like Analysis Services browser into their ASP.NET applications.
Improved performance – Version 2008 has brought significant performance enhancement and SSAS performs great when aggregating regular measures. Usually, it is the calculations that will get you in trouble. So, anything that can be done to improve the server performance further will be welcome. For instance, the calculation engine executes the query on a single thread. It will be nice if a more complicated query can be parsed and executed in parallel.
MDX Query Analyzer – Related to performance, it will be great if we finally get a graphical query analyzer (a-la the T-SQL query analyzer) with hints about how to improve the query execution.
Memory-bound partitions – Again related to performance, it will be great if you could configure a partition to be memory-bound for super-fast access, as I mentioned in this blog.
Detail reporting – I wish Analysis Services improves the ability to report on detail level. For example, it will nice to support text measures that the server returns for the lowest grain. I also want detail queries, such as a query that returns accounts for given customer to perform faster and don’t give up with “The expression contains a function that cannot operate on a set with more than 4,294,967,296 tuples.” error.
Resource governor – Analysis Services should expand on letting the administrator manage resources, such as memory, connections, query timeouts, etc.
Custom security – Support custom authentication that is not Windows-based to facilitate Internet connectivity perhaps similar to custom security in Reporting Services.
Modeling enhancements – OK, this is a catch-all bucket for support issues that I logged and which were declared as “by design” and “future enhancements” [:D], such as aggregatable Many-to-Many relationships, fixing subselect issues, fixing exclusion filter with custom operator issue.
Happy holidays!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2009-12-07 18:27:002016-02-17 06:31:26Analysis Services Top 10 Wish List
Now that I’ve got my copy and read it, I can say a few things about the book Expert Cube Development with Microsoft SQL Server 2008 Analysis Services by Chris Webb, Alberto Ferrari, and Marco Russo. As mentioned in another post, the authors (all MVPs and prominent SSAS experts) don’t disappoint and you won’t go wrong picking up this book. The book is somewhat small in size (330 pages) but big in wisdom and best practices. It also includes plenty of references to external resources and blogs that the authors and other SSAS experts have written when you need further understanding of the topics discussed. Make no mistake though, this is not a step-by-step book and it doesn’t target novice users. As its title suggests, the book is geared toward more advanced users who have a few years of SSAS experience under their belt and are thirsty for more insightful knowledge.
Chapter 1 Designing the Data Warehouse for Analysis Services
The first and most important step for implementing a successful Analysis Services solution has nothing to do with Analysis Services at all. Its success depends on a solid schema design on which you’ll build the cube so the book is right on target to hit this topic first. Chapter 1 discusses common schema modeling challenges and provides plenty of tips to tackle them. One grudge I have here is about the following sentence “Beware of the temptation to avoid building a data warehouse and data marts” which may leave the reader with the impression that a data mart is a must. In fact, call me lazy but the first thing that I’d explore when starting a new SSAS project is if it’s possible to avoid a separate database. While a classic OLAP solution in many cases will require a new database (whatever you call it a data warehouse or a data mart) and the whole ETL enchilada that this entails, you may need to build a cube on top of simpler schemas, such on top of a DSS (decision support system) schema. In this case, I would explore the option to “dimensionalize” the source schema with a layer of SQL views. As with everything else, the keep-it-simple principle works for me.
Chapter 2 Basic Dimensions and Cubes
This chapter discusses the groundwork required to set up the raw dimensional model. This includes working with data sources, data source views, cubes, and dimensions. My favorite part of this chapter was the attribute design and setting up attribute relations. This often overlooked aspect of SSAS development is crucial for achieving good performance and the book explains why.
Chapter 3 Designing More Complex Dimensions
Next, the book explains how to handle more complex dimension schemas and hierarchies. This includes parent-child, ragged, slowly-changing, referenced, fact, and junk dimensions. The authors’ real-life experience shows through. About junk dimensions, my preference is to avoid them wherever possible for performance reasons. Instead, I’d explore the option to keep the low-cardinality attributes in the fact table and use report or URL actions to view them. In my opinion, SSAS is not there yet as far as reporting on details.
Chapter 4 Measures and Measure Groups
The whole purpose of building a cube is to aggregate measures. Analysis Services supports various aggregation functions and the book provides essential coverage. You will learn how to implement semi-additive measures if you cannot afford the Enterprise Edition of SQL Server. Custom aggregation by using unary operators and custom member formulas are presented too. Then the book discusses more complex relationship types, including different grains, linked dimensions and measure groups, role-playing dimensions and fact relationships.
Chapter 5 Adding Transactional Data
Although most users would be interested in aggregated data, sometimes users may need to see the level of details behind a cell. The book explains how you can do this by using drillthrough and actions. Drillthrough options are covered in great details. Excellent coverage is provided for many-to-many relationships as well.
Chapter 6 Adding Calculations to the Cube
Cubes usually include business calculations in the form of MDX expressions. Chapter 6 gives lays the foundation for using MDX. It provides practical examples for calculated members, including YTD, ratios, growths, same period last previous year, moving averages, and ranks. Handling relative dates is a common business requirement. For example, I personally had to implement two custom types of relative dates as explained in this blog. The book provides a great example for implementing a custom calculation dimension for implementing more flexible relative dates that the BI Wizard provides. Finally, the chapter discusses static and dynamic named sets.
Chapter 7 Adding Currency Conversion
I consider myself lucky for never having to support international users because of the complexities surrounding the issue. If you have to, SSAS gives you the necessary features to tackle various localization requirements. This chapter walks you through the details of implementing currency conversion using the BI wizard, measure expressions, and writeback. My advice is to avoid writeback due to its limitations. Instead, consider an URL action that navigates the user to a custom web page for handing data changes and proactive caching for automatically updating the cube.
Chapter 8 Query Performance Tuning
SSAS bends backwards to provide great performance. You can help by following best practices for cube design. This chapter teaches you how to implement partitions and aggregations. I like the sections for monitoring partition and aggregation usage and building aggregations manually. The chapter presents useful tips to diagnose and resolve performance issues, such as by using the MDX Studio, named sets, calculated members, and caching.
Chapter 9 Securing the Cube
Chances are you will need to provide restricted access to the cube for groups of users. This chapter shows you how to implement and test roles. It covers cell and dimension security. It presents solutions for implementing custom dimension data security which are similar to the ones I discussed in this article.
Chapter 9 Productionization
Your SSAS solution is ready and it’s time to see daylight. This chapter covers the tasks associated with deploying and managing your SSAS solution in production environment. These include managing and generating partitions and processing. I liked the coverage of different processing options.
Chapter 10 Monitoring Cube Performance and Usage
As an administrator, your job doesn’t end once the solution is deployed. You need to monitor it on a daily basis to ensure that it performs optimally. The last chapter explains different server monitoring techniques, such as performance counters, tracing, Resource Monitor, SQL Profiler, and using Dynamic Management Views (DMVs). I personally liked the memory management tips.
In summary, I highly recommend this book to anyone who has several years of experience in SSAS development and need a compass check to make sure that he follows the right track. Kudos to the authors for taking time to write it!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2009-12-02 14:00:002016-02-17 06:36:08Expert Cube Development with Analysis Services 2008
An interesting issue popped up yesterday regarding the calculated member syntax. I had to multiply negative amounts in a financial cube for certain account categories that had negative amounts. The cube also had a Many:Many relationship between financial accounts and account groups which may be related to the issue. So, I had the following scope assignment:
CREATE MEMBER CURRENTCUBE.[Multiplier] /* Old Style*/
AS [Financial Account].[Financial Account Hierarchy].CurrentMember.Properties(“Multiplier”, TYPED),
this = [Financial Account].[Financial Account Hierarchy].CurrentMember * [Measures].[Multiplier];
End Scope;
The Multiplier calculated member returns the Multiplier property of the current account member, which could be 1 or -1 (if the account has to be negated). Then, the scope assignment overwrites all measures for the current member. As simple as it is, the assignment didn’t work and the account amounts didn’t get converted although the Multiplier calculated member would return the correct number. I stripped out the entire cube script to only these two script definitions but I couldn’t make it to work. After some research, I came to this interesting discussion between Chris Webb and Read Jacobsen, which made me think that the issue probably has something to do with the solve order of the calculated member. As it turned out, the new style has a higher pass so the following fixed the issue:
As Chris suggested, I tend to believe that it’s a bug especially given the fact that I’ve recently logged another nasty calculated member-related issue, where scope assignments would produce wrong results if the calculated members with the old style definitions are hidden.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2009-11-13 14:30:562016-02-17 07:13:46Not All Calculated Members Are Born Equal
Readers have been asking about a revised edition of my Applied Microsoft Analysis Services book for version 2008. First of all, I’d like to thank all my readers who bought and liked the book. This book has been a great success and it really exceeded my expectations in any way! It has great reviews on Amazon and it has sold over 10,000 copies to date, which is not a bad sales record for a technical book. I am still supporting my readers on the book discussion list and more than likely will continue doing so for foreseeable future. At the same time, I decided not to write a revision for SSAS 2008 or R2 for two main reasons:
I just need a break from book writing. It took me several months to write the Applied Microsoft SQL Server 2008 Reporting Services and BI toolkit. I am not ready to start a new book and … face a divorce. Seriously, writing books is not easy and it takes a lot of time away from the family. And I just can’t write small.
Version 2008 of Analysis Services has been an incremental and stabilization release. The theme was “don’t rock the boat” since the boat was rocked big time in SSAS 2005, which was essentially a re-write of Analysis Services from ground up. The major 2008 enhancements were in the area of performance and manageability. So, hardly enough material to write a revision from a feature standpoint although I definitely have plenty of real-life experience to contribute. So, Applied Microsoft Analysis Services 2005 is still not outdated and I hope you won’t go wrong reading it. Speaking of this book, since it looks like the demand for it waned in the past months (everyone jumped on the 2008 bandwagon, and this is what you should do) I’m not planning a new print. Instead, I lowered the price of the e-book version to $29.95, so the book is still available in e-book format if you decide to buy it.
Although I am not planning a new SSAS book anytime soon, I am committed to Analysis Services, which I like very much and use heavily in real-life projects. Looking forward, I am planning a new SSAS revision for SQL Server 11, which is next major release of SQL Server after R2. Meanwhile, I offer an Analysis Services 2008 training class if you are looking for instructor-led online training.
What Analysis Services 2008 books would I recommend?

 Now that I’ve got my copy and read it, I can say a few things about the
Now that I’ve got my copy and read it, I can say a few things about the 

