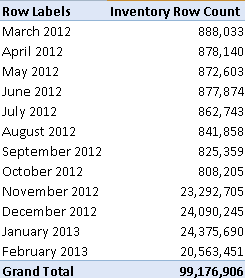Transactional Reporting with Tabular
Scenario: We had a requirement to replace the existing implementation of transactional reporting over large data volumes. By “transactional reporting” I mean allowing the user to query individual transactions as they’re stored in the fact table. In some cases, this style of reporting requires simply reading data without aggregations. This, of course is what RDBMS are designed for but in our case, requirements call for extending the reporting model with metadata about the item, such as the item barcode, alias, etc., as well as supporting fast aggregation analysis (for trend reports) and data security. In general, when implementing BI solutions, you should always have an analytical layer between the database and presentation layer for the reasons I discussed in the “Why an Analytical Layer?” blog.
Challenges: Because of the in-memory nature of Tabular and more relaxed schema requirements, such as no separation of dimension and fact tables and ability to keep text-based columns in fact tables, we opted for Tabular on top of a data warehouse and star schema. Our initial schema included an Item dimension table (700 million rows) where the item metadata is kept and Transactions table (1.5 billion rows) that stores the item transactions. However, as we found out quickly, this design presented challenges for Tabular:
- Excessive processing time – It took very long to process the initial model. By default, SSMS generates a transactional processing batch that supports processing multiple tables in parallel. However, if there is an error during processing the entire transaction is rolled back and you need start from scratch. To avoid this, we tried scripting the batch and changing it to non-transactional (Transaction=’false’). This option preserves the processed partitions but it doesn’t allow tables to be processed in parallel. This is by design to avoid unexpected interactions due to the potential cross-object dependencies in the recalculation chain. Since both the Item and Transactions tables were portioned, the net effect was that the processing was serialized by table and partition when two scripts for processing Item and Transactions are simultaneously executed (partition 1 of Transactions is processed, partition 1 of Item is processed, partition 2 of Transactions is processed, partition 2 of Item is processed, and so on). To make things worse, there is currently a bug with Tabular where the server builds relationships even when Process Data is used as a processing option which further slows down processing.
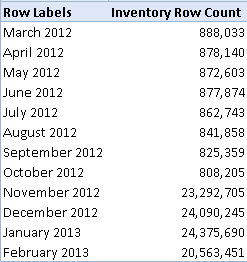
- Excessive memory footprint – For some reason, Tabular used a lot of memory with the two table approach. Granted, we had to load the dataset twice (one for Item and a second time for Transactions) but still it should have taken less memory (see the memory footprint in the Solution section). The development server had 80 GB of RAM. We ran out of memory half-way during the full load and ended up with the in-memory model taking 65 GB of RAM.
- Excessing query time – This was the worst. When we tried Power View as a reporting tool, each time the Item table was involved in the query, the report took more than a minute to finish. The report filter would return only in a few rows from the Transactions table but when the join was made to the Item table (one the one side of the Item-Transactions relationship), the report performance would degrade significantly. As it turned out, Tabular hasn’t been tuned for such scenarios where queries involve large dimension tables and the filter is applied on the fact table.
Solution: To work around the Tabular limitations, we merged the two datasets by joining the Item and Transactions tables in a SQL view. This approach resolved all issues:
- Processing time was reduced x10 because Tabular had to process only one large table.
- The memory footprint of the entire database with all the data was reduced to 13.5 GB.
- The query times went down to seconds.
The only caveat is that processing would incur a hit because of the join between two large tables but we’d rather spend more time during processing than sacrificing query performance.
At least for now, don’t be confused by the “relational” nature of Tabular. It’s still optimized for queries that request a restricted set of columns and aggregate data. Currently, it’s not optimized for transactional (detail-level) style of reporting that requires many columns and requests data at the lowest level. Microsoft is aware of this and would probably introduce optimizations in time.
In a future blog, I’ll discuss techniques to optimize the query performance with transactional reporting and Tabular. Many thanks to Marius Dumitru (Principal Architect on the SSAS team) for answering my questions.