What Can Fabric Do For My Lake?
Previously, I discussed the pros and cons of Microsoft Fabric OneLake and Lakehouse. But what if you have a data lake already? Will Fabric add any value, especially if your organization is on Power BI Premium and you get Fabric features for free (that is, assuming you are not overloading your capacity resources)? Well, it depends.
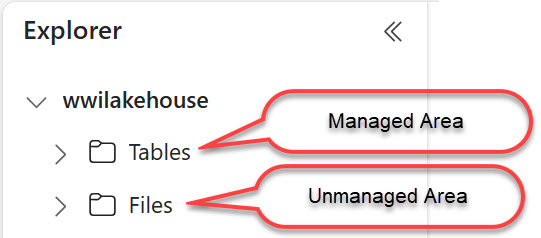
Managed Area
A Fabric lakehouse defines two areas: managed and unmanaged. The managed area (Tables folder) is exclusively for Delta/Parquet tables. If you have your own data lake with Delta/Parquet files, such as Databricks delta lake, you can create shortcuts to these files or folders located in ADLS Gen 2 or Amazon S3. Consequently, the Fabric lakehouse would automatically register these shortcuts as tables.
Life is good in the managed area. Shortcuts to Delta/Parquet tables open interesting possibilities for data virtualization, such as:
- Your users can use the Lakehouse SQL Analytics endpoint to join tables using SQL. This is useful for ad-hoc analysis. Joins could also be useful so users can shape the data they need before importing it in Power BI Desktop as opposed to connecting to individual files and using Power Query to join the tables. Not only could this reduce the size of the ingested data, but it could also improve refresh performance.
- Users can decide not to import the data at all but build semantic models in Direct Lake mode. This could be very useful to reduce latency or avoid caching large volumes of data.
Unmanaged Area
Very few organizations would have lakes with Delta Parquet files. Most data lakes contain heterogeneous files, such as text, Excel, or regular Parquet files. While a Fabric lakehouse can create shortcuts to any file, non Delta/Parquet shortcuts will go to the unmanaged area (Files folder).
Life is miserable in the unmanaged area. None of the cool stuff you see in demos happens here because the analytical endpoint and direct lake modes are not available. A weak case can still be made for data virtualization that shortcuts bring data readily available to where business users collaborate in Power BI: the Power BI workspace.
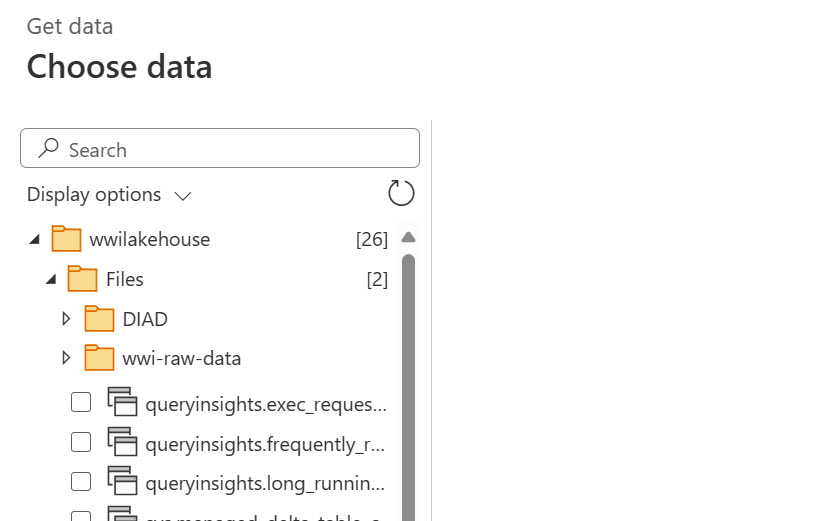
But what can the user do with these unmanaged shortcuts? Not much really. Power BI Desktop doesn’t even expose them when you connect to the lakehouse. Power BI dataflows Gen2 do give the user access to the Files folder so potentially users can create dataflows and transform data from these files.
Of course, the tradeoff here is that you are adding dependencies to OneLake which could be a problem should one day you decide to part ways. Another issue could be that you are layering Power BI security on top of your data lake security.
Oh yes, users can also load Parquet and CSV files to Delta tables by right-clicking a folder or a file in the Unmanaged area, and then selecting Load to Tables (New or Existing). Unfortunately, as it stands, this is a manual process that must be repeated when the source data changes.
Imagined Unmanaged Data Virtualization
This brings me to the two things that I believe Microsoft can do to greatly increase the value proposition of “unmanaged” data virtualization:
- Extend load to table to the most popular file formats, such as JSON, XML, and Excel. Or, at least the ones that Polybase has been supporting for years. Not sure why we have to obsess with Delta Parquet and nothing else if Microsoft is serious about data virtualization.
- Implement automatic synchronization to update the corresponding Delta table when the source file changes.
If these features are added, throwing Fabric to the mix could become more appealing.
In summary, Microsoft Fabric has embraced Delta Parquet as its native storage file format and has added various features that targets it. Unfortunately none of these features extend to other file formats. You must evaluate pros and cons when adopting Fabric with existing data lakes. As it stands, Fabric probably wouldn’t add much business value for data virtualization over file formats other than Delta Paquet files. As Fabric matures, new scenarios might be feasible to justify Fabric integration and dependency.