First Look at Fabric IQ: The Good, The Bad, and The Ugly
Telegraph sang a song about the world outside
Telegraph road got so deep and so wide
Like a rolling river…
The Telegraph Road, Dire Straits
At Ignite in November, 2025, Microsoft introduced Fabric IQ. I noted to go beyond the marketing hype and check if Fabric IQ makes any sense. The next thing I know, around the holidays I’m talking to an enterprise strategy manager from an airline company and McKinsey consultant about ontologies.
Ontology – A branch of philosophy, ontology is the study of being that investigates the nature of existence, the features all entities have in common, and how they are divided into basic categories of being. In computer science and AI, ontology refers to a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
So, what better way to spend the holidays than to play with new shaky software?
What is Fabric IQ?
According to Microsoft, Fabric IQ is “a unified intelligence platform developed by Microsoft that enhances data management and decision-making through semantic understanding and AI capabilities.” Clear enough? If not, if you view Fabric as Microsoft’s answer to Palantir’s Foundry, then Fabric IQ is the Microsoft equivalent of Palantir’s Foundry Ontology, whose success apparently inspired Microsoft.
Therefore, my unassuming layman definition of Fabric IQ is a metadata layer on top of data in Fabric that defines entities and their relationships so that AI can make sense of and relate the underlying data.
For example, you may have an organizational semantic model built on top of an enterprise data warehouse (EDW) that spans several subject areas. And then you might have some data that isn’t in EDW and therefore outside the semantic model, such as HR file extracts in a lakehouse. You can use Fabric IQ as a glue that bridges that data together. And so, when the user asks the agent “correlate revenue by employee with hours they worked”, the agent knows where to go for answers.
Following this line of thinking, Microsoft BI practitioners may view Fabric IQ as a Power BI composite semantic model on steroids. The big difference is that a composite model can only reference other semantic models while Fabric IQ can span data in multiple formats.
The Good
Palantir had a head start of a decade or so compared to Microsoft Fabric, but yet even in its preview stage, I like a thing or two about Fabric IQ from what I’ve seen so far:
- Its oncology can span Power BI semantic models (with caveats explained in the next section), powered by best-in-class technology. As I mentioned before, this allows you to bridge all the business logic and calculations you carefully crafted in a semantic model to the rest of your Fabric data estate.
- Fabric IQ integrates with other Microsoft technologies, such as real-time intelligence (eventhouses), Copilot Studio, Graph. This tight integration turns Fabric into a true “intelligence platform,” reducing duplicated logic, one-off models, and maintenance while enabling multi-hop reasoning and real-time operational agents.
- Democratized and no-code friendly – Visual tools allow business users to build and evolve the ontology, lowering barriers compared to more engineering-heavy alternatives. Making it easy to use has always been a Microsoft strength.
- Groundbreaking semantics for AI Agents: Fabric IQ elevates AI from pattern-matching to true business understanding, allowing agents to reason over cascading effects, constraints, and objectives—leading to more reliable, auditable decisions and automation.
- Compared to Palantir, I also like that Fabric OneLake has standardized on an open Delta Parquet format and embraced data movements tools Microsoft BI pros and business users are already familiar with, such as Dataflows and pipelines, to bring data in Fabric and therefore Fabric IQ.
The Bad
I hope some of these limitations will be lifted after the preview but:
- Only DirectLake semantic models are accessible to AI agents. Import and DirectQuery models are not currently supported for entity and relationships binding. Not only does this limitation rule out pretty much 99.9% of the existing semantic models, but it also prevents useful business scenarios, such as accessing the data where it is with DirectQuery instead of duplicating the data in OneLake.
- No automatic ontology building – It requires cross-functional agreement on business definitions, workshops, and governance—labor-intensive for organizations without mature semantic models. I hope Microsoft will simplify this process like how Purview has automated scans.
- Risk of overhype vs. delivery gap – We’ve seen this before when new products got unveiled with a lot of fanfare, only to be abandoned later.
The Ugly
OneLake-centric dependency. Except for shortcuts to Delta Parquet files which can be kept external, your data must be in OneLake. What about these enterprises with investments in Google BigQuery, Teradata, Snowflake, and even SQL Server or Azure SQL DB? Gotta bring that data over to OneLake. Even shortcut transformations to CSV, Parquet, JSON files in OneLake, S3, Google Cloud Storage, will copy the data to OneLake. By contrast, Palantir has limited support for virtual tables to some popular file formats, such as Parquet, Iceberg, Delta, etc.
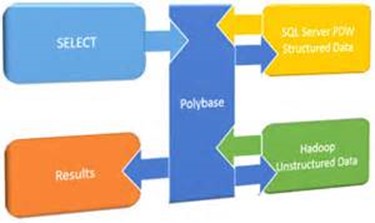
What happened to all the investments in data virtualization and logical warehouses that Microsoft has made over years, such as PolyBase and the deprecated Polaris in Synapse Serverless? What’s this fascination with copying data and having all the data in OneLake? Why can’t we build Fabric IQ on top of true data virtualization?
Which is where I was thinking that semantic models with DirectQuery can be used as a workaround to avoid copying data over from supported data sources, but alas Fabric IQ doesn’t like them yet.
Summary
Microsoft Fabric IQ is a metadata layer on top of Fabric data to build ontologies and expose relevant data to AI reasoning. It will be undoubtedly appealing to enterprise customers with complex data estates and existing investments in Power BI and Fabric. However, as it stands, Fabric IQ is OneLake-centric. Expect Microsoft to invest heavily in Fabric and Fabric IQ to compete better with Palantir.