Prologika Newsletter Winter 2021

Happy Holidays! More and more organizations consider data virtualization to abstract the underlying storage and integrate siloed sources. In this letter, I’ll discuss a real-life project that used PolyBase to expose third-party ERP data as SQL tables. Before I get to the subject of this newsletter, I’m excited to announce the seventh edition of my “Applied Microsoft Power BI” book. It should be available on Amazon in the first days of 2022. As far as I know, it’s the only book that is updated annually to keep it up to the date with the fast-changing Power BI. Stay tuned for a future blog with more details about the book.
Business Case
Think of data virtualization is a logical data layer that integrates enterprise data across various on-premises and cloud sources. A large, multinational chemical manufacturer decided to migrate their on-premises ERP system to the cloud. As usually happens, the tradeoff for embracing the cloud is losing access to your data in its native storage. Previously, the client could readily integrate the ERP data stored in a SQL Server database. But the ERP vendor didn’t support this option in their cloud offering. The usual explanation cites security and performance issues, although none of them really hold water. The ERP vendor could have supported a premium tier where data is exposed privately without affecting other customers, and report queries could have been redirected to a secondary replica. This is no different that securing and scaling an Azure SQL Database. Alas, as more and more companies find when embracing the cloud, the integration burden gets heavier and is on them and not on the vendor.
To make things even more difficult, the vendor had a replication mechanism to export the data to AWS S3 data lake. Realizing that most clients would struggle calling their REST APIs, the vendor provided an JDBC driver that abstracted the APIs. Great, except that the client wanted to access the data on Microsoft Azure, but no Microsoft tool supports JDBC drivers because no Microsoft BI tool is written in Java.
Integration Options
One integration option could have been to use a JDBC-capable ETL tool, such as Pentaho. But that would have required implementing integration pipelines to pull the data periodically and stage it on Azure. This presented two issues. First, the data integration effort became more difficult as someone had to own and troubleshoot ETL failures. Second, Business wanted as much real-time access to data as possible. In the past, the business users had implemented self-service Power BI models that they would refresh as needed to cache the data from the on-premises database. However, since the ERP vendor required at least 20 minutes for data changes to be applied to the S3 data lake and ETL needed additional time (even with incremental extraction), the data latency became an issue.
The second option was to somehow virtualize the data. Had the vendor supported exporting the data as files on Azure, Synapse Serverless could have been used to expose the data as virtual tables that can be queried with SQL and loaded in Power BI Desktop. But Serverless doesn’t support AWS S3 and even if it did, the vendor didn’t allow direct access to the staged data (REST APIs and JDBC driver were the only supported options).
PolyBase to the Rescue
The solution I proposed was to use PolyBase which is included in SQL Server and Azure SQL Managed Instance. Ideally, the client wanted a full PaaS solution but only PolyBase in SQL Server supports ODBC. So, we had to use an IaaS VM just to virtualize the data. This diagram shows the solution architecture.
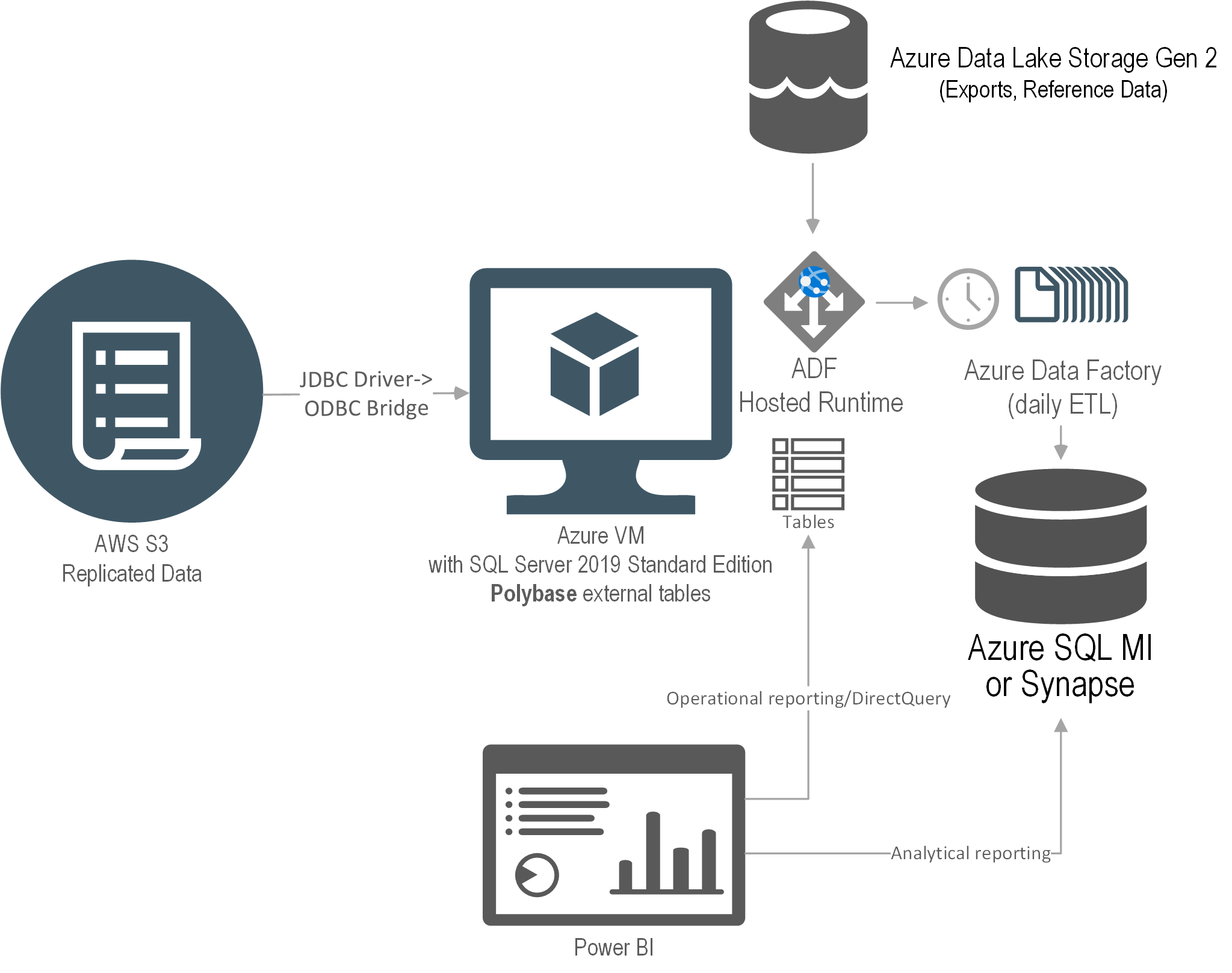
An Azure VM was provisioned with SQL Server 2019 Standard Edition. The JDBC driver was installed on the VM and configured to access the ERP data. We used a third-party JDBC-to-ODBC bridge driver to map the JDBC data source as an ODBC data source. Then, PolyBase external tables were set up to virtualize the ERP data as SQL Server tables.
The main drawback of this solution was that no matter how small the source table was, PolyBase would add about 30 seconds in internal processing. Specifically, the PolyBase runtime log has a detailed trail that shows that it takes some time for PolyBase to “warm up” before it gets to the query, and then it needs even more time to process the results. That’s because, as a distributed system (like Synapse), a head node coordinates the query execution with data nodes even if everything is installed on a single VM. More gotchas specific to the fact that the vendor has decided to use Oracle as their relational database can be found at https://prologika.com/polybase-adventures/.
Conclusion
Microsoft has made bold strides in data virtualization. I’m really impressed by Synapse Serverless, which I used for other projects, such as for the project described in this case study. I wish Microsoft extends Serverless to support more storage options. If Synapse Serverless is not an option, your next best bet would be PolyBase. Although PolyBase is supported in SQL MI and Synapse, only the SQL Server box SKU supports ODBC data sources, requiring an IaaS layer to virtualize the data.
Benefits
The solution delivered the following benefits to the client:
- No ETL effort – Data was left at the original source.
- Data virtualization – Polybase was used to create external tables that can be queried just like SQL Server regular tables.
- Reduced data latency – Data changes were available as soon as they are replicated to the data lake.
- Scalability – PolyBase can be scaled out to other servers if needed.

Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
![]()



