Atlanta BI fans, please join us in person for the next meeting on Monday, July 1st at 6:30 PM ET. John Kerski (Microsoft MVP) will shows us how to integrate ChatGPT with Power BI. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Details
Presentation: Commenting Power Query with Azure OpenAI Delivery: In-person Date: July 1, 2024 Time: 18:30 – 20:30 ET Level: Intermediate Food: Pizza and drinks will be provided
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Venue
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Large Language Models (such as ChatGPT) can greatly enhance the way you develop and deliver Power BI solutions. In this session I will show you how to integrate Azure Open AI into Power BI using prompt engineering techniques.
Speaker: John Kerski has over a decade of experience in technical and government leadership. He specializes in managing Data Analytics projects and implementing DataOps principles to enhance solution delivery and minimize errors. John’s expertise is showcased through his ability to offer patterns and templates that streamline the adoption of DataOps with Microsoft Fabric and Power BI. His in-depth knowledge and hands-on approach provide clients with practical tools to achieve efficient and effective data operations.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-06-25 11:14:362024-06-25 11:14:36Atlanta Microsoft BI Group Meeting on July 1st (Commenting Power Query with Azure OpenAI)
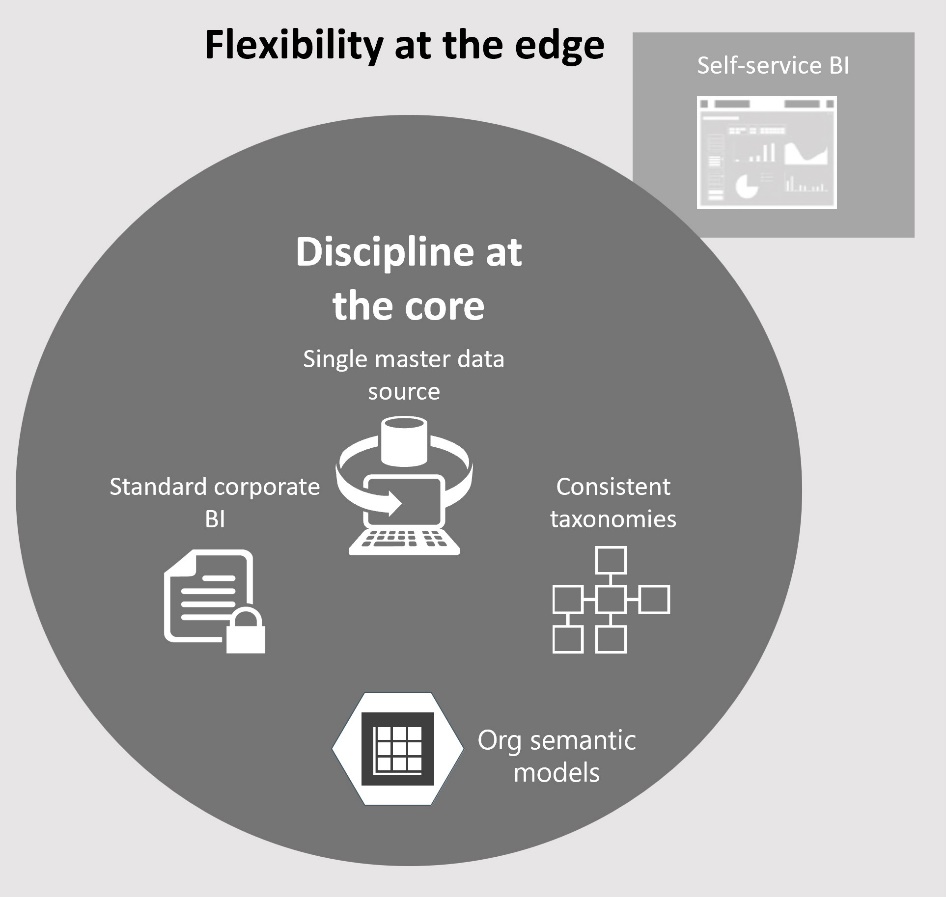
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “Are you modern yet?” and “Data Lakehouse: The Good, the Bad, and the Ugly”) but a recent assessment inspired to me write about this topic again. This newsletter advocates a hybrid and cautionary approach for data integration to avoid overdoing data lakes and warns about pitfalls of over-staging source data to files. It recommends instead following the “Discipline at the core, flexibility at the edge” methodology with emphasis on implementing enterprise data warehouse and organizational semantic models.
Data Lake Overstaging
How did the large vendor attempt to solve these horrible issues? Modern Data Warehouse (MDM) architecture of course. Nothing wrong with it except that EDW and organizational semantic model(s) are missing and that most of the effort went into implementing the data lake medallion architecture where all the incoming data ended up staged as Parquet files. It didn’t matter that 99% of the data came from relational databases. Further, to solve a data change tracking requirement, the vendor decided to create a new file each time ETL runs. So even if nothing has changed in the source feed, the data is duplicated should one day the user wants to go back in time and see what the data looked like then. There are of course better ways to handle this that doesn’t even require ETL, such as SQL Server temporal tables, but I digress.
At least some cool heads prevailed and the Silver layer got implemented as a relational ODS to serve the needs of home-grown applications, so the apps didn’t have to deal with files. What about EDW and organizational semantic models? Not there because the project ran out of budget and time. I bet if that vendor got hired today, they would have gone straight for Fabric Lakehouse and Fabric premium pricing (nowadays Microsoft treats partners as an extension to its salesforce and requires them to meet certain revenue targets as I explain in “Dissolving Partnerships“), which alone would have produced the same outcome.
What did the vendor accomplish? Not much. Nor only didn’t the implementation address the main challenges, but it introduced new, such as overcomplicated ETL and redundant data staging. Although there might be good reasons for file staging (see the second blog above), in most cases I consider it a lunacy to stage perfect relational data to files, along the way losing metadata, complicating ETL, ending up serverless, and then reloading the same data into a relational database (ODS in this case).
I’ve heard that the vendor justified the lake effort by empowering data scientists to do ML one day. I’d argue that if that day ever comes, the likelihood (pun not intended) of data scientists working directly on the source schema would be infinitely small since more than likely they would require the input datasets to be shaped in a different way which would probably require another ETL pipeline altogether.
Better Data Staging
I don’t subject my clients to excessive file staging. My file staging litmus test is what’s the source data format. If I can connect to a server and get in a tabular (relational) format, I stage it directly to a relational database (ODS or DW). However, if it’s provided as files (downloaded or pushed, reference data, or unstructured data), then obviously there is no other way. That’s why we have lakes.
Fast forward a few years, and your humble correspondent got hired to assess the damage and come up with a strategy. Data lakes won’t do it. Lakehouses and Delta Parquet (a poor attempt to recreate and replace relational databases) won’t do it. Fabric won’t do it and it’s too bad that Microsoft pushes Lakehouse while the main focus should have been on Fabric Data Warehouse, which unfortunately is not ready for prime time (fortunately, we have plenty of other options).
What will do it? Going back to the basics and embracing the “Discipline at the core, flexibility at edge” ideology (kudos to Microsoft for publishing their lessons learned). From a technology standpoint, the critical pieces are EDW and organizational semantic models. If you don’t have these, I’m sorry but you are not modern yet. In fact, you aren’t even classic, considering that they have been around for long, long time.
Just passed DP-600 and therefore I’m officially a Fabric Analytics Engineer. Besides renewals, I intend this to be my last Microsoft certification. After more than 30 years of certifying (12 certifications and 30 exams) and helping other certify with training and books, I think it’s time to close this chapter. Call me certifiable…
Atlanta BI fans, please join us in person for the next meeting on Monday, June 3rd at 6:30 PM ET. Shabnam Watson (Consultant and Owner of ABI Cube) will discuss the benefits of using the Direct Lake storage mode in Microsoft Fabric. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Presentation: Power BI Direct Lake storage mode: How to achieve blazing fast performance without importing data Delivery: In-person Time: 18:30 – 20:30 ET Level: Beginner/Intermediate Food: Pizza and drinks will be provided
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Venue
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Power BI engine in Microsoft Fabric has been significantly revamped to work directly with Delta files in OneLake. This brand-new storage mode is called Direct Lake which allows Power BI to achieve super-fast query performance on billion row datasets without having to import the data into Power BI. Join this session to learn how you can work with Direct Lake with just a few clicks.
Speaker: Shabnam is a business intelligence consultant and owner of ABI Cube, a company that specializes in delivering data solutions using the Microsoft Data Platform. She has over 20 years of experience and is recognized as a Microsoft Data Platform MVP for her technical excellence and community involvement. She is passionate about helping organizations harness the power of data to drive insights and innovation. She has a deep expertise in Microsoft Analysis Services, Power BI, Azure Synapse Analytics, and Microsoft Fabric. She is also a speaker, blogger, and organizer for SQL Saturday Atlanta – BI version, where she shares her knowledge and best practices with the data community.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-05-28 11:53:322024-05-28 11:54:16Atlanta Microsoft BI Group Meeting on June 3rd (Power BI Direct Lake storage mode)
Atlanta BI fans, please join us in person for the next meeting on Monday, April 1st at 6:30 PM ET. Aravinth Krishnasamy (Principal Architect at Ecolab) will provide an end-to-end overview of Microsoft Fabric real-time analytics capabilities. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Presentation: Real-Time Analytics with Microsoft Fabric: Unlocking the Power of Streaming Data
Delivery: In-person
Date: April 1, 2024
Time: 18:30 – 20:30 ET
Level: Beginner/Intermediate
Food: Pizza and drinks
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Microsoft BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: This session will provide an end-to-end overview of Microsoft Fabric Real-Time Analytics capabilities. We will go over the following topics:
1. Introduction to Real-Time Analytics: Overview of the platform and its capabilities
2. Data Ingestion: How to ingest data from various streaming sources into Fabric
3. Data Analysis & Visualization: How to analyze and visualize data using Real-Time Analytics and Power BI
4. Use Cases: Real-world use cases for Real-Time Analytics.
Speaker: Aravinth Krishnasamy is a Principal Architect at Ecolab, where he focuses on business intelligence, data warehousing and advanced analytics applications. Aravinth holds numerous technical certifications and has over 18 years of IT experience.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-26 11:50:102024-03-26 11:50:10Atlanta Microsoft BI Group Meeting on April 1st (Real-Time Analytics with Microsoft Fabric: Unlocking the Power of Streaming Data)
Previously, I discussed the pros and cons of Microsoft Fabric OneLake and Lakehouse. But what if you have a data lake already? Will Fabric add any value, especially if your organization is on Power BI Premium and you get Fabric features for free (that is, assuming you are not overloading your capacity resources)? Well, it depends.
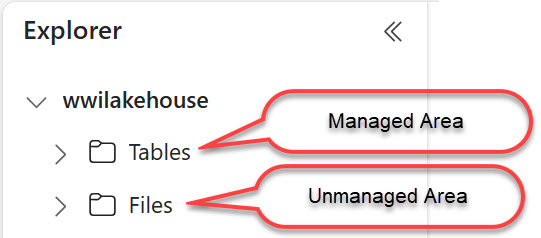
Managed Area
A Fabric lakehouse defines two areas: managed and unmanaged. The managed area (Tables folder) is exclusively for Delta/Parquet tables. If you have your own data lake with Delta/Parquet files, such as Databricks delta lake, you can create shortcuts to these files or folders located in ADLS Gen 2 or Amazon S3. Consequently, the Fabric lakehouse would automatically register these shortcuts as tables.
Life is good in the managed area. Shortcuts to Delta/Parquet tables open interesting possibilities for data virtualization, such as:
Your users can use the Lakehouse SQL Analytics endpoint to join tables using SQL. This is useful for ad-hoc analysis. Joins could also be useful so users can shape the data they need before importing it in Power BI Desktop as opposed to connecting to individual files and using Power Query to join the tables. Not only could this reduce the size of the ingested data, but it could also improve refresh performance.
Users can decide not to import the data at all but build semantic models in Direct Lake mode. This could be very useful to reduce latency or avoid caching large volumes of data.
Unmanaged Area
Very few organizations would have lakes with Delta Parquet files. Most data lakes contain heterogeneous files, such as text, Excel, or regular Parquet files. While a Fabric lakehouse can create shortcuts to any file, non Delta/Parquet shortcuts will go to the unmanaged area (Files folder).
Life is miserable in the unmanaged area. None of the cool stuff you see in demos happens here because the analytical endpoint and direct lake modes are not available. A weak case can still be made for data virtualization that shortcuts bring data readily available to where business users collaborate in Power BI: the Power BI workspace.
But what can the user do with these unmanaged shortcuts? Not much really. Power BI Desktop doesn’t even expose them when you connect to the lakehouse. Power BI dataflows Gen2 do give the user access to the Files folder so potentially users can create dataflows and transform data from these files.
Of course, the tradeoff here is that you are adding dependencies to OneLake which could be a problem should one day you decide to part ways. Another issue could be that you are layering Power BI security on top of your data lake security.
Oh yes, users can also load Parquet and CSV files to Delta tables by right-clicking a folder or a file in the Unmanaged area, and then selecting Load to Tables (New or Existing). Unfortunately, as it stands, this is a manual process that must be repeated when the source data changes.
Imagined Unmanaged Data Virtualization
This brings me to the two things that I believe Microsoft can do to greatly increase the value proposition of “unmanaged” data virtualization:
Extend load to table to the most popular file formats, such as JSON, XML, and Excel. Or, at least the ones that Polybase has been supporting for years. Not sure why we have to obsess with Delta Parquet and nothing else if Microsoft is serious about data virtualization.
Implement automatic synchronization to update the corresponding Delta table when the source file changes.
If these features are added, throwing Fabric to the mix could become more appealing.
In summary, Microsoft Fabric has embraced Delta Parquet as its native storage file format and has added various features that targets it. Unfortunately none of these features extend to other file formats. You must evaluate pros and cons when adopting Fabric with existing data lakes. As it stands, Fabric probably wouldn’t add much business value for data virtualization over file formats other than Delta Paquet files. As Fabric matures, new scenarios might be feasible to justify Fabric integration and dependency.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-13 14:19:362024-03-20 12:55:54What Can Fabric Do For My Lake?
Atlanta BI fans, please join us in person for the next meeting on Monday, March 4th at 6:30 PM ET. The famous Patrick LeBlanc (Guy in the Cube) will take a deep dive into the Microsoft Fabric ecosystem, from Lakehouse to Warehouses and Power BI, ensuring you can make informed decisions about your data processing needs. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Presentation: Navigating Microsoft Fabric – Choosing the Right Workload for Your Needs
Delivery: In-person
Date: March 4
Time: 18:30 – 20:30 ET
Level: Beginner/Intermediate
Food: Pizza and drinks
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Microsoft BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: As businesses transition to the cloud and leverage advanced analytics, understanding the nuances of data infrastructure becomes paramount. Microsoft Fabric offers a suite of powerful tools designed to handle various data workloads, but the key to harnessing its full potential lies in understanding which tool to use and when. This session provides a deep dive into the Microsoft Fabric ecosystem, from Lakehouse to Warehouses and Power BI, ensuring that participants can make informed decisions about their data processing needs. We’ll also look at current limitations that will help guide you.
Speaker: Patrick LeBlanc is a currently a Principal Program Manager at Microsoft and a contributing partner to Guy in a Cube. Along with his 15+ years’ experience in IT he holds a Master of Science degree from Louisiana State University. He is the author and co-author of five SQL Server books. Prior to joining Microsoft, he was awarded Microsoft MVP award for his contributions to the community. Patrick is a regular speaker at many SQL Server Conferences and Community events.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-27 08:11:522024-02-27 08:11:52Atlanta Microsoft BI Group Meeting on March 4th (Navigating Microsoft Fabric – Choosing the Right Workload for Your Needs)
Last year my wife and I did a tour of Greece, and we had a blast. Greece, of course, is the place to go if you are interested in ancient history and the origin of democracy. One of the places we visited was Delphi. The ancient Greeks believed it to be the center of the universe. Now not much was left of it except lots of ruins and imagination. But back then it was magnificent. People from all over the world would come to consult with the Oracle of Delphi. She delivered her prophecies from the temple of Apollo, which had three inscriptions, with one of them being “Know thyself”. The practical benefit for the oracle was that if you believed her cryptic prophecy wasn’t fulfilled then your interpretation was wrong. Therefore, the problem was in you because you didn’t know yourself.
How does this translate into BI? I see clients overly excited about Microsoft Fabric/Power BI Premium, believing that bundling features will solve all their issues. But knowing your organization, ask yourself if your users would use all these features to justify the premium price. A case in point: Power BI source control via workspace Git integration: a feature that appear to be created from developers for developers. Kristyna Hughes did a great presentation for our Atlanta BI Group on Monday covering how developers can take the most of this feature.
Given the self-service focus of Power BI, however, I doubt that data analysts would subject themselves to learning Azure DevOps, Visual Studio Code, and Git CI/CD. Yet, Power BI source control has been in demand since the beginning with the most common ask – the ability to roll back changes.
Here is my take to simplify Power BI source control for regular users:
Power BI Premium/PPU/Fabric clients
If you are on Power BI Premium, set up a branch for each workspace that you want to put under source control, and configure the workspaces for Git integration.
Let business users publish changes as usual.
Periodically and as a part of the change management process, the workspace admin approves the changes and commits them to source control. I hope one day Power BI would transparently commit changes to Git as Azure Data Factory does it, without requiring explicit synchronization. Meanwhile, the admin must manually commit.
Someone privileged to Azure DevOps would need to roll back changes if needed. Again, I hope one day history review, compare, and roll back will be baked in Power BI.
Power BI Pro clients
Once this feature is generally available, embrace Power BI Desktop projects.
When significant changes are made, back up report and model.bim json files to some location, such as OneDrive which has built-in version control.
Replace the project files when you need to roll back changes. Again, this “poor man” source control emphasizes simplicity and saves premium licenses.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-08 14:40:172024-02-08 14:40:17Know Thyself: Power BI Source Control
What a better way to spend a lazy holiday afternoon than to do more Fabric performance testing? In my previous post, I shared my results from a single-threaded ETL load test to gauge the F2 ingest performance and F2 did pretty well (or at least outperformed Azure SQL DB). Will F2 hold as parallelism increases? Throughput testing is especially important for report loads because parallel tasks can run within a report, such as visuals executing DAX queries in parallel, and across reports, such as when concurrent report requests overlap.
I used the artifacts are included in the “Microsoft Dashboard in a Day” for this test and load tested only the first report page.
The Sales fact table in the semantic model has over seven million rows so it represents a good size dataset. Naturally, the more involved the report is and the more data the semantic model has, the more CPU power and parallelism are needed. I used the Microsoft Power BI Dedicated Capacity Load Assessment Tool and configured it to filter the report on different years in order to avoid report caching. I ran four tests for 1, 2, 3 and 4 virtual users with no think time, and each test ran for 10 minutes.
Here are the results:
Users
Total report renders
Renders per user
1
63
1×63
2
100
2×50
3
135
3×45
4
164
4×41
Here are some additional findings:
Within the first minute or so, F2 generates reports fast, presumably because bursting comes into play to let F2 borrow and recruit more CPU resources. As the sustained load continues, Fabric starts scaling back and throttling CPU.
As time goes by, report executions are getting increasingly slower. While during the first minute a report can take 1-2 seconds for example, later it might take as much as 40 seconds to render (users are unlikely to tolerate this). This happens even with one virtual user, presumably because the quarter of the core is insufficient.
I haven’t encountered any errors. All report executions succeeded irrespective of how long they take.
What all these tests mean is that if Fabric is appealing to you, F2 can be a viable option for smaller organizations where report users are expected to run reports sporadically. In case of a sudden load, such as everyone running reports at 8 AM on Monday, Fabric bursting can elevate the pressure for the first minute or so. Of course, you need to weigh in many other factors, such as relenting control to Microsoft, waiting for the technology to mature, avoiding lock-in, evaluating budget (note that viewers would still need at least Power BI Pro individual licenses for capacities lower than F64), and various other considerations I covered in my previous Fabric-related posts.
As inspired by Amir Netz‘s encouragement to partners to test the Fabric F2 capacity performance, I got on a quest to test what it would do to ETL loads for Fabric Warehouse. I must admit that I was skeptical that a quarter of a core would take a warehouse off the ground, but as usual, life proved me wrong and “wrong” is a big understatement of what happened.
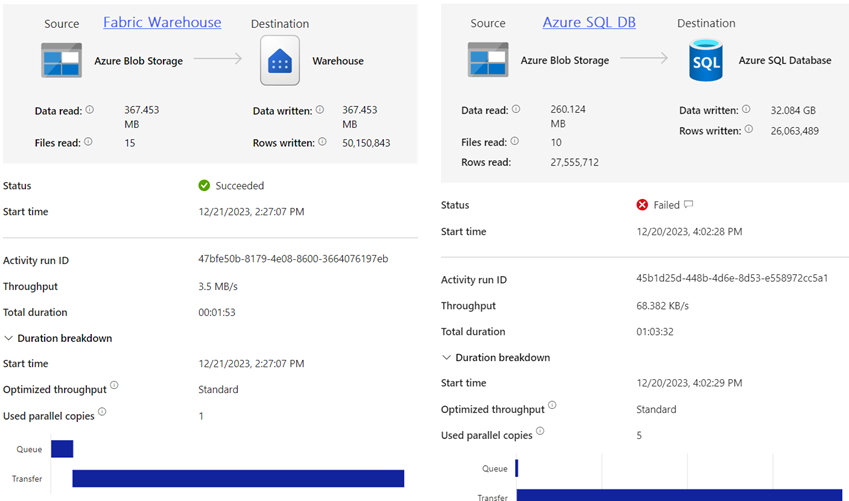
After provisioning a Fabric F2 capacity and a warehouse, I settled on the Retail Data Model for World Wide Importers sample star schema dataset consisting of five dimension tables and one fact table. In terms of performance, I was mostly interested in how long it would take for the ADF copy activity to insert all the data (50 million rows) in the fact table. Granted, it’s a limited test but enough to rule out the technology for real-life projects. Then, I compared the performance against Azure SQL Database Serverless running on up to 2 cores and provisioned by the free trial offer that Microsoft has on Azure. To exclude impact on data transfer between regions, both technologies were provisioned on East US 2 data region, which is the region where my Power BI tenant is hosted on.
Much to my surprise, it took less than two minutes to load all 50 million rows in F2, whereas it took 1 hour to load to load 27 million rows to Azure SQL Database before the maximum 30 GB disk space was exhausted! I couldn’t believe it so I ran the test three times to confirm. Surely, bursting helps a lot! Now, throughput would be a different story, but as far as the warehouse is concerned, it doesn’t matter because in most cases, data will be imported in a Power BI semantic model and the warehouse will be out of the picture. As a next step, I plan to test the report throughput to see what concurrent report load would saturate the F2 capacity.
In conclusion, the Fabric lowest capacity F2 ($262.80 monthly cost) could be a viable option for smaller organizations willing to make their foray in the Fabric world. On the downside, we must leave Fabric to marinate for a few months and add needed features, including surrogate keys and MERGE for Warehouse and on-prem connectivity for Azure Data Factory, in order to be in consideration for real-life projects. More tests are needed to gauge the F2 report throughput.
UPDATE 12/24/2023 I was curious how much loading the same dataset from a CSV file would impact performance. It took much longer: 18 minutes. The most significant factor was that loading from CVS requires staging to a data lake although this appears redundant because the CVS file was in a lakehouse in the same Power BI workspace. ADF spent a total of 18 minutes in the two-staged copy (ten minutes to stage the data and eight minutes to load the fact table from the staged copy). Therefore, Parquet outperformed significantly CVS, probably because the Microsoft-provided Parquet file was compressed.

 I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “