Prologika Newsletter Spring 2023
 There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our Atlanta Power BI Group and you can find the recording here (I have to admit we could have done better job with the recording quality, but we are still learning in the post-COVID era).
There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our Atlanta Power BI Group and you can find the recording here (I have to admit we could have done better job with the recording quality, but we are still learning in the post-COVID era).
What’s Data Lakehouse
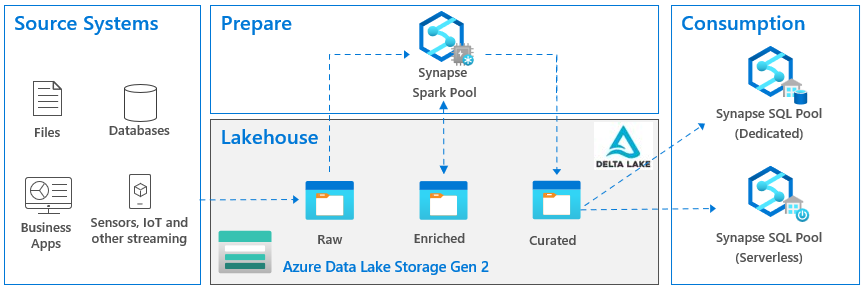
According to Databricks which are credited with this term, a data lakehouse is “a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.” It other words, it’s a hybrid between a relational data warehouse and a data lake. Sounds great, right? Visualizing this in Microsoft parlor, the last incarnation of the lakehouse architecture that I came across looks like this:
The Good
I’m sure that many large companies or companies with complex data integration needs could benefit from a similar architecture. As I said many times, staging data to a lake is a good thing when you must deal with files. For example, some cloud vendor that hasn’t matured enough to give direct access to your data, could decide to push files instead (I described a similar scenario in this blog). A “network share” on steroids, the data lake is the best place to store files. A good question here and the one I personally struggled with would be “what if the data comes from relational databases or from REST APIs?” Should you stage that data in a data lake as files before it flows into the data warehouse? A wise consultant’s answer here would be “it depends”. Here are some good reasons when this might make sense.
- Stage data first – For some, a large ISV company (see related newsletter here), had to integrate data from many databases with similar but not the same schema. They preferred to stage the data to a data lake and figure out the integration “mess” caused my schema discrepancies and data quality later.
- A glorified archive – For example, in case you want to reload the data, you can do it from the lake in the case where the source systems truncate data. However, my personal preference to address this scenario would be to stage the data into a relational Operational Data Store (ODS), especially in the case where changes must be tracked. In a nutshell, if I’m given a choice between a file or relational database, I’d go with the latter.
- Synapse – If you decide to host your data warehouse in a Synapse dedicated SQL pool and use Azure Data Factory (ADF) to load the data, ADF will stage the data to Azure Data Lake Service (ADLS) anyway to load it faster into Synapse. Another good thing for Synapse here is that you can use Synapse Serverless to query that data using SQL which might come handy (I share some “serverless” lessons learned here).
- Data science – There are some good reasons why data scientists prefer files instead of loading the data from a relational database. Or so I was told (I’m not a data scientist).
- Uniformity – If your organization prefers a uniform data flow path despite the additional effort, inconvenience, and redundancy, then this might make sense. Then despite the source data type (structured or unstructured), all data follows the same ingestion pipeline. Just make sure to hire more ETL developers.
Outside these considerations, when you can connect directly to the data source, staging data to files is probably overkill as files are notoriously difficult to deal with.
The Bad
Now let’s look at the so-called zones in the lake: raw, enriched and curated, sometimes also referenced as bronze, silver, and gold. The idea here is to enrich the staged data. So, the raw zone has the staged data 1:1 as in the source. Then let’s say a data scientist needs some enrichment, and we spin more ETL to add a bunch of columns to some file. And then Business needs to reference the data that might require more enrichment. So, into the ETL rabbit hole we go again.
The problem is that many people take this architecture verbatum, whether it makes sense or not. A question came from the audience during Patrick’s presentation “What data do we add to these zones?” How do we know when it’s time to move to the next zone? And the answer here is that these zones are just a recommendation that someone has come up with. A large organization might benefit from them. But in most cases in my opinion spinning more and more ETL and moving data around just so that you follow some vendor’s best practices, makes no sense. And should you stage the data 1:1 from the source? In some cases, like the Get Data First aforementioned scenario, it might make sense. But in most cases, it would be much more efficient to stage the data in the shape you need it, which may necessitate joining multiple tables at the source (by the way, a relational server is the best place to handle joins).
The omni-presence of Synapse in such architectural diagrams is questionable at least. As I stated in another newsletter, like a red giant star, Synapse seems to engulf everything in its path in order to increase its value potential. But Synapse shouldn’t be a default choice for most organizations. It’s rather expensive and has limitations, such as lacking important T-SQL features.
Finally, Spark/Databricks that orchestrates the data preparation with Python or some other custom code since all the toolset you get is a notebook with a blinking cursor. What happened to low code, no code approach? More ETL developers to the rescue…
The Ugly
The omnipresence of the delta lake regardless if it makes sense or not. I’m sure that some scenarios for staging changing data into a lake, such as IoT streaming, will benefit greatly from a delta lake. But it shouldn’t be a default recommendation. The moment we introduce a delta lake, our tool choice becomes rather restricted because of the file format. On ETL side of things, for example, you must use data flows with Azure Data Factory (I’d personally favor ELT over data flows). And to read the data, you must provision either a Spark cluster or Synapse Serverless. So, complexity increases together with cost while data accessibility decreases.
UPDATE 05/28/2023 Microsoft Fabric embraced the delta format as the its native storage but provides more options, including Power Query dataflows and Azure Data Factory copy activity, to load data. All Fabric services save and read data from the delta lake and you don’t have to provision anything.
And if you go with Databricks (credited for inventing the delta lake too), they are far more ambitious . They want to replace RDBMs for OLAP (OLTP won’t work with a delta lake for performance reasons). We’ve seen similar claims before and how they ended. Another question came from the audience during the presentation was if a lakehouse can deliver the same performance as a relational database. One house must be redundant, right? True, after rewriting their software, Databricks can deliver some decent performance (they even claim to be the world’s fastest “data warehouse” although only one other vendor submitted results to that specific benchmark). James Serra (Data & AI Solution Architect at Microsoft), whose excellent blog discusses these topics in detail, recently gave our group a presentation and said that anyone he knows of that has tried replacing a relational data warehouse with a data lake, has failed. Enough said.
What’s a best practice? A best practice to me is adopting the most efficient way to achieve something without sacrificing too much flexibility for what might be thrown at you in the future. To me, a lakehouse as a replacement for a relational data warehouse or as a default staging area is as big of a hype as Big Data was, with all the vendor propaganda surrounding it to buy stuff you don’t need. Large organizations with complex integration needs might benefit from the lakehouse architecture shown above. However, most companies could save a lot of implementation, maintenance, and licensing costs by simplifying it and judicially introducing pieces when it makes sense.

Teo Lachev
Prologika, LLC | Making Sense of Data
![]()

 A few days ago an exalted customer shared that they’ve acquired Synapse and now they’re ready for Power BI modeling. He just wasn’t sure how to give business users access to Synapse so cool self-service BI can finally start. In the process of the conversation, it became clear that he opened Synapse Studio and was left with the impression that Synapse has semantic modeling features. This is what happens when Marketing gets involved and people get confused about what a tool actually does. This newsletter attempts to clear up this confusion.
A few days ago an exalted customer shared that they’ve acquired Synapse and now they’re ready for Power BI modeling. He just wasn’t sure how to give business users access to Synapse so cool self-service BI can finally start. In the process of the conversation, it became clear that he opened Synapse Studio and was left with the impression that Synapse has semantic modeling features. This is what happens when Marketing gets involved and people get confused about what a tool actually does. This newsletter attempts to clear up this confusion.