Prologika Newsletter Fall 2021

LabCorp operates one of the largest clinical laboratory networks in the world. It also has an Interactive Response Technology system that healthcare vendors can use to conduct case studies. Thanks to the cloud data analytics solution implemented by Prologika, LabCorp and its vendors can now analyze data across case studies. Read this newsletter to learn more about the solution architecture and business value.
Business Needs
The data for each study was saved into a separate on-prem SQL database. The total number of databases was more than 1,000. After the initial assessment, Prologika realized that one of the main gaps was that vendors couldn’t report across their studies or gain performance insights from studies conducted by other vendors. Further, as the IRT system evolves over time and to accommodate special requests, there were scheme differences between different versions.
LabCorp underscored the importance of consolidating the data from multiple studies into a single repository. They envisioned a cloud-based PaaS BI solution that would extract data from all the on-prem databases without impacting the system performance and centralize it into an enterprise data warehouse. Vendors would log an external portal that will deliver embedded reports. The first iteration was focused on analyzing audit and log data to gain strategic insights, such as how many users are using the system.
Solution
After assessing the current state and objectives, Prologika recommended and implemented the following architecture:
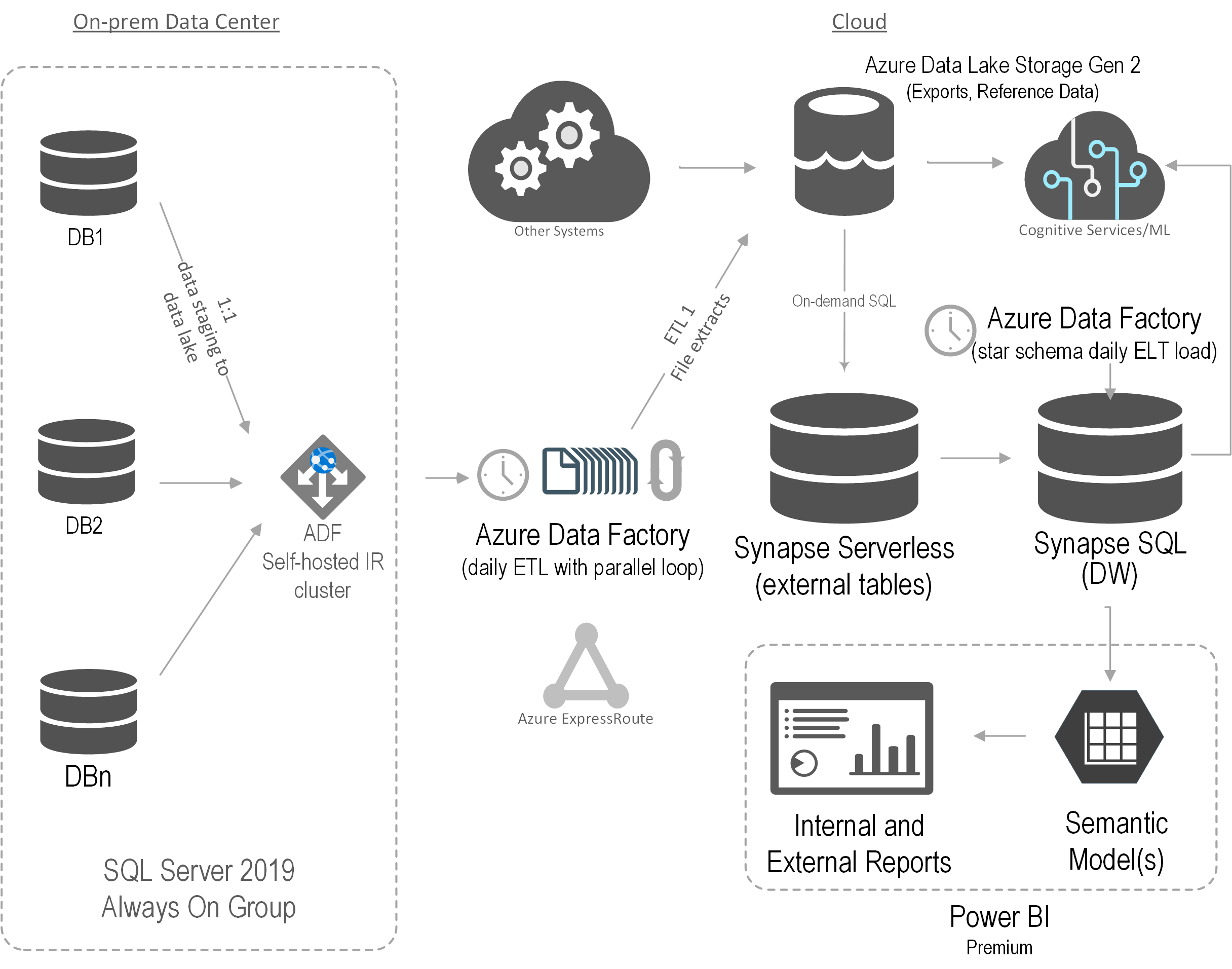
Prologika implemented an Azure Data Factory (ADF) configurable framework to extract data from the on-prem databases hosted on two production SQL Servers in parallel. The framework would stage the data into partitioned parquet files in Azure Data Lake Storage (ADLS).
Then Prologika created views in Synapse Serverless to consolidate the file extracts. For example, an Audit table could exist in several on-prem databases on both production servers. While each table would be staged in a separate file (or multiple files if the table supports incremental extraction), a Synapse Serverless would present a consolidated view across all files. We were impressed by the capabilities and performance of Synapse Serverless.
Another ADF process would extract the data from the Synapse Serverless views and load the data into a data warehouse hosted in a Synapse SQL pool. Although we considered other methods, such as using a linked server in a Azure SQL Managed Instance to Synapse Serverless to avoid data staging, we settled on Synapse SQL mainly for its scalability. Finally, a Power BI semantic model was created and Power BI Embedded used to deliver reports.
Benefits
The solution delivered the following benefits to LabCorp:
- Data consolidation – Data was extracted with minimum impact to the operational systems and consolidated in ADLS.
- Data virtualization – Thanks to the Synapse Serverless flexible support of schema differences, virtual views were created.
- Scalability – Synapse SQL pool can scale almost indefinitely.
- Secure and fast insights – Each vendor can access only their data.

Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
![]()


