TAG BI is organizing a “Making Big Data Real” event on August 23th and I was honored to be one of the panelists. Please join us if you can and ask me the techniques we use to implement multi-terabyte data warehouses on symmetric multiprocessing (SMP) systems that deliver reports within milliseconds and maximize your return on investment.
“The Technology Association of Georgia’s Business Intelligence/Enterprise Performance Management society explores one of the hottest topics in the technology landscape, Big Data. You have likely read the articles and the books and now you need to know more. On August 23, we will bring together a panel of experts for a most important session: “Making Big Data Real”. Please join us as we engage corporate technology leaders and consultants that are on the cutting edge of this new technology landscape. We will tell you what Big Data is all about and how you can make it real and actionable at your workplace and in your career. This is surely a professional event you do not want to miss.”
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-08-11 14:22:562016-02-16 06:40:09Making Big Data Real from TAG BI
I’d delegate this one to the PerformancePoint 2013 blog, where Kevin Donovan, Microsoft Program Manager, nicely addresses PerformancePoint speculation, confusion and misinformation while also introducing what is new in detail.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-08-10 00:29:222021-02-16 02:47:21What’s New in Office 2013 BI: Part 5 – New Features in PerformancePoint 2013
To demonstrate the new features with Excel web reports, I stood up an Office 365 Technical Preview site. If you have received Office 365 invitations already, make sure that you choose the one with the SKU E3. Otherwise, you’ll get access to the administrator portal only and you won’t see the SharePoint, Outlook, and other menus.
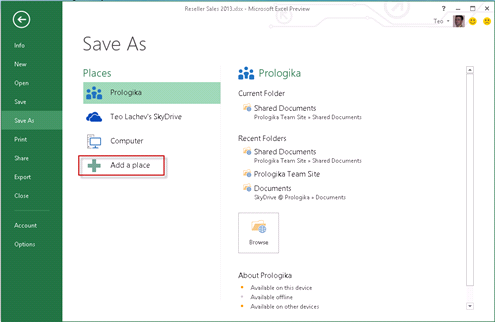
Assuming you use Office 2013, you’ll find that it integrated much better with the cloud. Gone is the Save and Send menu. Instead, saving to could destinations, such as SkyDrive and Office 365, can be now be initiated from the Save As menu by adding a new place.
As before, once the Excel workbook lands in the Office 365 SharePoint (or SharePoint 2013) land, it’s automatically available for web reporting. However, the most exciting new feature now is that the web reports are editable and end users can change the report layout with both PowerPivot and OLAP cubes as data sources! To do so, simply right-click any cell on the pivot report and click Show Field List. Just like the desktop version of Excel, you can now add or remove fields in the Field List to update the report.
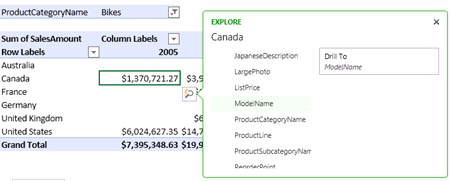
The Quick Explore feature is available as well to support a “Proclarity-like” data exploration experience. You can click a cell on the report and then click on the magnifying class icon and pops up. Or, right-click a cell and click Quick Explore. Then, expand a table (dimension) and select which field (attribute) you want to drill-down to.
Unfortunately, drillthrough is still unsupported and you can’t drill down a cell to see the underlying details as you can in Excel desktop. This feature is very frequently requested and I don’t know why it didn’t make the cut. Another feature that I would love to get with both Excel desktop and web reports is the Decomposition Tree that is currently only available with PerformancePoint Services. Speaking of PerformancePoint, SharePoint 2013 brings improved branding, filter enhancements and filter search, as well as support for Analysis Services EffectiveUser connecting string setting in case configuring Kerberos is not an option.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-08-06 13:37:002016-02-16 06:44:24What’s New in Office 2013 BI: Part 4 – New Features in Excel Web Reports
Excel 2013 includes features that improve productivity. Here are the ones related to BI.
Flash Fill
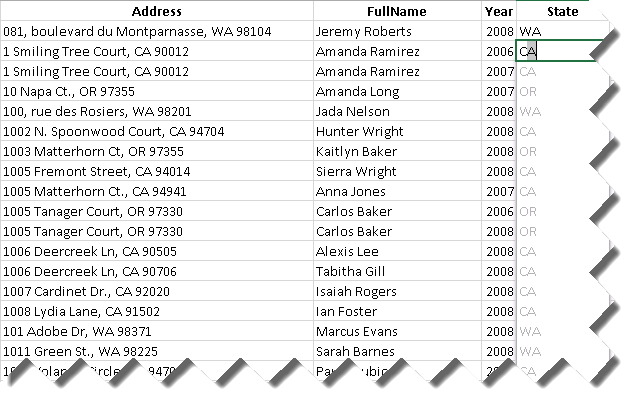
Suppose that you have a list of customers with addresses. When analyzing the data, you might want to analyze sales by USA states but the data doesn’t include a state column. Instead, suppose you have an address column that includes the mailing address, state, and zip code. So, you decide to create a new column. Now, instead of using a formula to parse the address as you would do in the past, you just enter WA in the first row. When you start typing CA in the second row, Excel figures the pattern and suggests to flash-fill the column. Notice that Flash Fill doesn’t use Excel formulas and you won’t get formulas in the column. Excel handles flash fill natively.
Quick Explore
This feature was included to allow you to quickly generate charts for analyzing data by time with Multidimensional and Tabular models. When you click a cell in a pivot report, the Quick Explore button is shown that gives you options to create trend or cycle chart. Notice that you can select another date dimension (table) to replace the default selection of Date.Calendar Date.
Speaking about analysis by time, Excel adds a new fitter, called “timeline”, that is specifically designed for this purpose. I found it an improved version of the Power View filter for integer fields. You can click a section in the timeline to select a specific period. Or, you can drag the mouse for an extended selection, such as years 2005-2007.
Quick Analysis
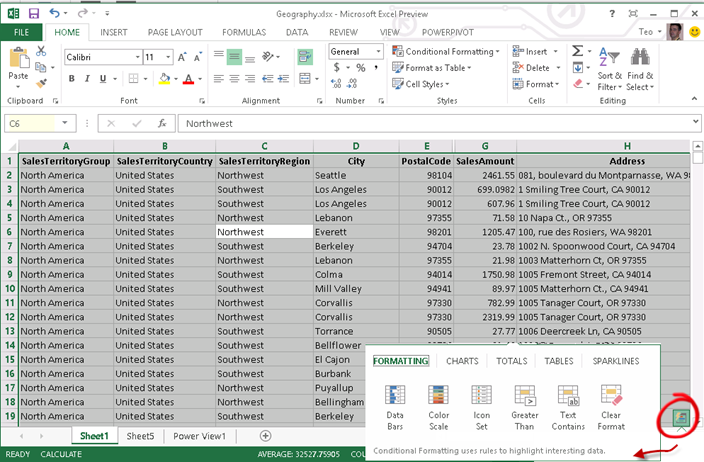
Suppose you have an Excel table but you don’t know much about pivot table, charts, and formatting. You can simply select the list (Ctrl+A) and click the Quick Analysis button to open a window that examines the dataset and suggests formatting (data bars, color scales, and conditional formatting, charts, tables, and sparklines.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-30 01:45:002016-02-16 06:51:22What’s New in Office 2013 BI: Part 3 – Improved Productivity
Power View in Office 2013 brings the following new features:
Integration with Excel 2013 – Microsoft has decoupled Power View from SharePoint and included it in Excel so you can create ad-hoc reports connected to BI models, just like you can create pivot reports. I hope the PerformancePoint Decomposition Tree will follow suit.
New visualizations – This includes interactive and drillable geospatial maps and pie charts.
Better support of tabular models – Power View now supports key performance indicators (KPIs) and hierarchies.
Design and branding enhancements – You can now insert images and change the report theme.
To showcase some of these enhancements, I created a personal BI model based on a customer dataset imported from the AdventureWorksDW2012 database (I attached the Excel workbook). To create a Power View report, click on Insert ð Power View button in the Excel ribbon. This creates an empty Power View report connected to the BI model.
My dataset includes the customer location defined as address, postal code, city, state, and country. I’ve found two ways to visualize geospatial data:
Use longitude and latitude coordinates – Power View doesn’t support SQL Server geography data types. However, if you have a geography data type, extracting the longitude and latitude values is easy. You just need to query the Lat and Long property of the geography data type.
SELECT SpatialLocation.Lat, SpatialLocation.Long FROM Person.Address
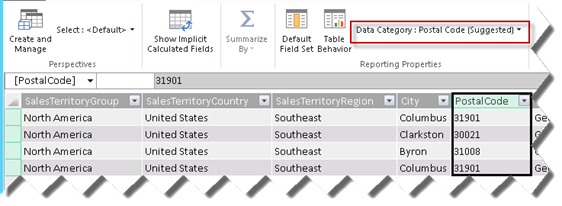
Geocode from an address. If you drop an address field to the Locations zone, the map will prompt you to geocode it. Power Pivot also supports advanced properties and it tries to infer automatically known field categories. For example, in the screenshot below, Power View has identified that the PostalCode field contains zip codes and mapped it to the Postal Code category.
If you place multiple fields in the Locations zone, Power View will allow you to drill down these fields. In my case, I put the StateProvinceName and PostalCode fields in the Locations zone. Consequently, if I double-click on a bubble, Power View will zoom in the map to show me where my customers are located by postal code within that state. I can click the “drill up” in the map right upper corner to go back to the state level.
Note Not sure if this is a bug with the pre-release version of Office 2013, but Power View seems to have a problem with drilling down to entities with the same name. For example, initially I put the City field in the Locations zone but when I drilled down Georgia, Power View switched to Columbus, Ohio because both Ohio and Georgia have a city Columbus. It appears that Power View drills down to the first entity in finds in that level instead of constraining the list to the parent’s children only.
The Power View report also shows a pie chart. If I click a segment on the pie chart it cross-filters the map. For example, if I click the 2005 pie, the map highlights customers with sales in 2005. Vice versa, if I click a bubble in the map, the pie chart gets updated to show the data for that bubble only, such as sales for customers in Georgia. The field list shows that Power View now supports KPIs and hierarchies. The Gross Sales is defined as a KPI in the underlying model and Customers by Country is defined as a hierarchy. Finally, you can change the report theme and add images from the Excel’s Power View ribbon.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-26 00:27:002016-02-16 06:54:42What’s New in Office 2013 BI: Part 2 – Power View Enhancements
Jen Underwood wrote a great summary about what’s new in Office 13 BI. Interestingly, you’ll be able to drill down to lower location in the Power View maps, e.g. from country to state and then to lowest level you placed in the location zone when configuring the map visualization.
In a current project, international users indicated that they prefer dates and numbers to be formatted using their regional settings. Localization is a big and complicated topic and we’ve been fortunate that the scope was limited to just number and date formatting … or, at least so far.
Localizing reports on a report server running in native mode is easy. You just need to use culture –neutral format strings, e.g. C for currency of P for percentage, and set the report-level Language property to =User!Language. However, this is not enough for reports running in a SharePoint integrated mode. SharePoint requires installing language packs as follows:
For each language you plan to support, download the corresponding language pack. For example, to download the German language page, change the drop-down to German and download the pack.
Log in a SharePoint Farm Administrator and install the language pack. At the end of the setup process, leave the checkbox to start the wizard in order to run the wizard to reconfigure the farm.
Once the wizard is done, go to the site that you want to localize, click Site Actions -> Site Settings, and then click the Language Settings link under Site Administration.
Check all languages that will be supported on the site.
To avoid “The LocaleIdentifier property is not overwritable and cannot be assigned a new value” error (more than likely a bug) when an international user requests a report connected to an Analysis Services cube, change the connection string of the SSAS data sources to pin it to the locale identifier of the server by appending the following setting, as Kasper De Jonge mentions in his blog: Locale Identifier=1033
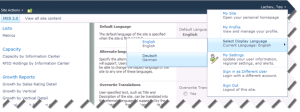
Instruct your users to personalize the display language by expanding the name drop-down and selecting a display language:
Once this is done, the users will see the SharePoint menus translated, and dates and numbers on the reports formatted using the selected display language.
As you probably know by now, Microsoft unveiled the Office 2013 Technology Preview. As the portal page says, “we’ve Taken Self-Service BI to the Next Level”. Indeed, this is where I believe we’ll see Office 2013 emerging as a leading tool on the market for self-service BI. Based on my experience, business users love Excel 2010 with PowerPivot because of its familiar environment and ease of use. However, the Excel visualization capabilities have been lacking. As familiar as they are, pivot table reports are getting somewhat outdated. This is why I put enhanced visualization options on my wish list. This all changes in Office 2013 where the question won’t be “Why we don’t have modern visualization options?” but “Which visualization option should I use?”
Microsoft decoupled Power View from SharePoint and added it to Excel to allow business users to create ad-hoc Power View reports that source data from the personal models that they create in Excel. Speaking of personal models, xVelocity (previously known as VertiPaq) integrates now natively in Excel to power any PivotTable and PivotChart report. Fellow MVPs have already covered some of the new BI features. Check Chris Webb’s Building a Simple BI Solution in Excel 2013 blog series and Thomas Ivarsson’s Power View in Excel 2013 blog series. In this blog, I’ll show you the Excel native integration with xVelocity and explain why you still need PowerPivot. Now that MSDN subscribers can set up a free VM on Windows Azure, I stood up a Virtual Machine that has SQL Server 2012 and Office 13. I plan to add SharePoint 2013 later on. A great solution for my demos!
Suppose you are a business analyst with Adventure Works and you’re tasked to analyze reseller sales data that is kept in the company’s data warehouse.
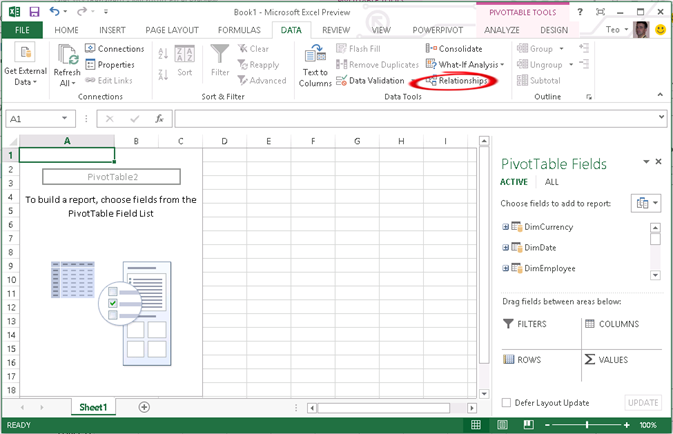
Unlike Excel 2010, you don’t have to go to the PowerPivot Window to start the import process. Instead, you can use the Excel native import capabilities. Click on Data From Other Data Sources From SQL Server. Then, specify the server name and database.
In the Select Database and Table step, check the “Enable selection of multiple tables” checkbox so we can import multiple tables in one shot. Enabling importing of multiple tables would automatically put the data into the xVelocity store as Excel doesn’t natively support joining tables. Then, check FactResellerSales and click the Select Related Tables button to select all tables that are directly related to FactResellerSales if there are referential integrity constraints defined in the database.
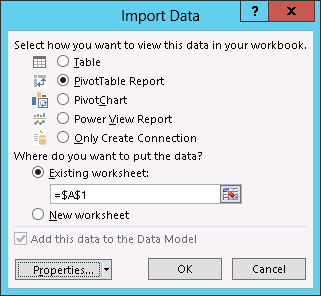
In the Save Data Connection File and Finish step, enter the name of the file name and a friendly name of the connection and click Finish. The Import Data dialog box deserves more attention.
If you chose the first option, Excel will add new sheets with data, each corresponding to a database table. However, if you chose the other options, the data will be imported into the model but no sheets will be added to the workbook. This will be useful if you want to import a table with more than a million rows because Excel still has the limitation of having one million rows per sheet. As with the previous releases, the 64-bit of Excel is preferable if you want to pack lots of data in the xVelocity engine because it can access all the memory as opposed to 2 GB only.
Next, Excel imports the data and adds tables into the internal model, and then shows the tables in the field list (notice that the Excel field list supersedes the PowerPivot Field list). Also, notice that you can click the Relationship button to manage the table relationships as you can do now with PowerPivot for Excel. As you can see, some of the PowerPivot features moved to Excel. From the PivotTable field list ALL tab you can see any other table that exists in the workbook and use them in the pivot.
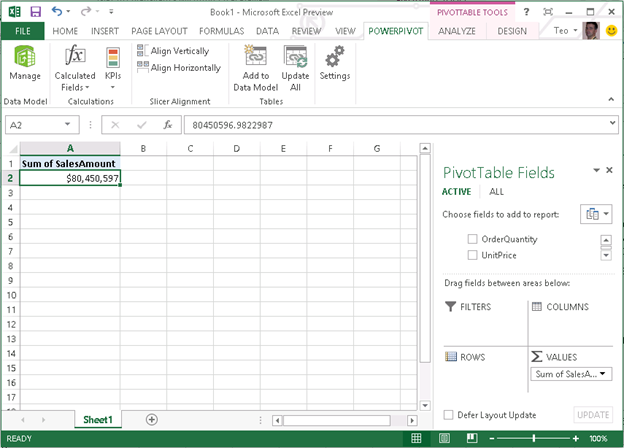
So, what about PowerPivot for Excel? The add-in is still there but not enabled by default. To enable it, click File ð Options, then click the Add-Ins tab. In the Manage drop-down, select COM Add-ins, and then check the Microsoft Office PowerPivot for Office 2013 add-in. This adds the PowerPivot menu to the Excel ribbon. From the PowerPivot menu, you can click the Manage button to launch the familiar PowerPivot for Excel window. No new PowerPivot features are added to Office 2013.
What can you do with PowerPivot that you can’t do with Excel 15? Here are some reasons to use the add-in:
Add calculated columns to tables in the model
Add calculated measures
Change the metadata, e.g. rename tables and columns, format columns, change column data types
Hide tables and columns so they will not show in the field list
Use the diagram view to visualize the schema, manage relationships, create hierarchies
Using the PowerPivot advanced features, such as perspectives and Power View reporting features
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-23 02:49:002016-02-16 07:03:26What’s New in Office 2013 BI: Part 1 – Personal BI with Excel
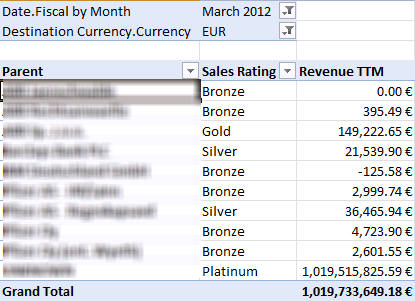
Consider the following calculated member definition added to the script in an Analysis Services cube:
CREATE MEMBER CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1;
When you browse the member in Excel, you’ll find that the member is not formatted as currency. However, when you use SSMS and query the member, when you double-click the member cell in the query results, you’ll see that the value is formatted as expected. Clearly, Excel has an issue with formatting calculated members and there is a connect bug report that has been quietly sitting in the Excel bucket for years. To Microsoft credit, we have a KB article “Description of the LANGUAGE cell property in SQL Server 2005 Analysis Services”.
“However, SQL Server 2005 Analysis Services cannot determine the value of the LANGUAGE cell property or of the currency symbol for calculated members from the query context. You must specify the LANGUAGE cell property if you want to obtain a nondefault currency symbol. If you do not specify the LANGUAGE cell property, the numeric value of the cell value and the currency symbol of the cell value may not match.”
I think what they meant was specifying the Language property in the calculated member definition. Indeed, the following change causes Excel to show the calculated member formatted as currency (USD in this case):
CREATE MEMBER CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1, LANGUAGE=1033;
What about dynamic formatting based on the selected currency? Assuming that you have a Destination Currency dimension and includes a Locale column with the integer locale identifier, e.g. 1033 for USD, 1031 for EUR, and so on), the following script overwrites the member language and the value will be formatted based on the destination currency selected by the user:
Language( this ) = [Destination Currency].[Currency].Properties( “Locale” );
End Scope;
TIP On the subject of formatting, you might need to “pin” a calculated member to a particular currency format to avoid the OLAP browser changing the format. As a fist attempt, you might try hardcoding the currency sign, such as “$0,0.00′”. Unfortunately, Excel will ignore it and overwrite it based on the regional settings. For example, a UK user will still see “£100.00”. Hrvoje Piasevoli suggested escaping the currency symbol to prevent this from happening, e.g. create member currentcube.measures.test as 1000.01, format_string=”\$0,0.00″, language=1033;
Since I live in the USA, I have to admit I’m somewhat shielded from the localization complexities surrounding currency and date formatting. Chris Webb wrote a blog “Currency formats: should they be tied to language?” a while back that you should check as well.
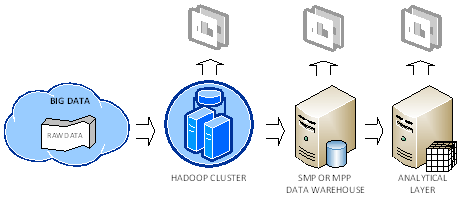
Let’s recap my thoughts on Hadoop. I’ve found the case studies presented in the chapter 16 of the “Hadoop: The Definitive Guide” book very useful to understand how organizations are currently using Hadoop. In general, the following deployment scenario emerges as a common pattern:
An organization accumulates Big Data from various sources, such as web logs, sensors, website traffic, and so on. The organization decides to store the raw data in the Hadoop fault-tolerant file system (HDFS). As far as cost, RainStor published an interesting study about the cost of running Hadoop. It estimated that you need an investment of $375 K to store 300 TB which translates to about $1,250 per terabyte before compression. I reached about the same conclusion from the price of single PowerEdge C2100 database server, which Dell recommends for Hadoop deployments.
Note I favor the term “raw data” as opposed to unstructured data. In my opinion, whatever Big Data is accumulated, it has some sort of structure. Otherwise, you won’t be able to make any sense of it. A flat file is no less unstructured than if you use it as a source for ETL processes but we don’t call it unstructured data. Another term that describes the way Hadoop is typically used is “data first” as opposed to “schema first” approach that most database developers are familiar with.
Saving Big Data in a Hadoop cluster not only provides a highly-available storage but it also allows the organization to perform some crude BI on top of the data, such as by analyzing data in Excel by using the Hive ODBC driver, which I discussed in my previous blog.
The organization might conclude that the crude BI results are valuable and might decide to add them (more than likely by pre-aggregating them first to reduce size) to its data warehouse running on an SMP server or MPP system, such as Parallel Data Warehouse. This will allow the organization to join these results to conformant dimensions to support analyzing data by other subject areas then the ones included in the raw data. The important point here is that Hadoop and RDBMS are not competing but completing technologies.
Ideally, the organization would add an analytical layer, such as an Analysis Services OLAP cube, on top of the data warehouse. This is the architecture that Yahoo! and Klout followed. See my Why an Analytical Layer? blog about the advantages of having an analytical layer.
Note Currently, it’s not possible for an Analysis Services OLAP cube to load data directly from Hadoop because of the subselect queries that the ODBC cartridge injects. PowerPivot or Tabular would work as they use opaque queries (QueryDefinition query bindings).
The world has spoken and Hadoop will become an increasingly important platform for storing Big Data and distributed processing. And, all the database mega vendors are pledging their support for Hadoop. On the Microsoft side of things, here are the two major deliverables I expect from the forthcoming Microsoft Hadoop-based Services for Windows whose community technology preview (CTP) is expected by the end of the year:
A supported way to run Hadoop on Windows. Currently, Windows users have to use Cygwin and Hadoop is not supported for production use on Windows. Yet, most organizations run Windows on their servers.
Ability to code MapReduce jobs in .NET programming languages, as opposed to using Java only. This will significantly broaden the Hadoop reach to pretty much all developers.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-01 19:44:002021-02-16 03:52:25MS BI Guy Does Hadoop (Part 5 – The Big Picture)