Power BI Models Scaling Up
Chris Webb wrote a great post today “Power BI Roadmap Announcements In the Dynamics 365 Spring ’18 Release Notes” citing the many exciting new features coming to Power BI in the next few months and highlighting the huge momentum behind Power BI. I want to bring your attention to a couple of them:
- Incremental data refresh: Organizations can use incremental data refresh to scale datasets to even larger sizes. With incremental data refresh, users can load only new or changed data. When creating a dataset in the Power BI Desktop, a user configures a refresh table for each table in the model that is to load incrementally, and then publishes it to a Power BI Premium workspace. Thereafter, each scheduled refresh loads only new or changed data.
- Query acceleration for large datasets (Public Preview): Users can create DirectQuery models over any size data in sources, such as Spark and Azure SQL Data Warehouse, and then accelerate common queries by building in-memory aggregations over some of the data. Common queries use the aggregated cache to return results in a fraction of a second instead of directly querying the source. Users can create datasets of massive size and still provide interactive querying.
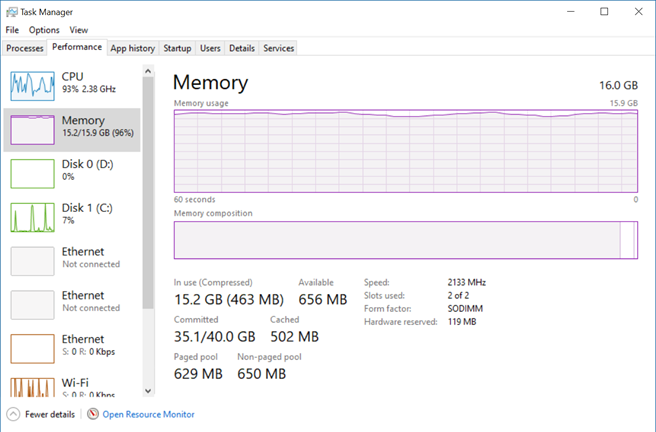
Why is this important? Because important professional features have crossed the Analysis Services-Power BI line and now business users can build large-scale models using Power BI Desktop. In fact, it looks like “in-memory aggregations” would come first to Power BI as we don’t have them in Analysis Services (yet). Now, I’m not a big proponent of business users building “massive” models (such datasets should be centralized and sanctioned by professionals) but apparently there is a good case for it. In fact, in my “Why Business Like Yours Choose Power BI Over Sisense” blog, I mentioned that SiSense uses this as a competitive advantage. At that time, the maximum Power BI dataset size was 1 GB. If you wanted to build larger models, you had to use Analysis Services, which has a separate price tag, and requires Visual Studio for development. Not to mention that you have to migrate your models from Power BI Desktop to Analysis Services (supported in AAS but not officially supported with on-premises SSAS) and learn new skills.
A lot has changed since. Notably, Power BI Premium raised the maximum dataset size to 10 GB and it’s likely that this limit would be raised further. While I’m not ready to embrace Power BI Desktop for organizational semantic models yet, soon Power BI Premium users will have the option to use a business-user friendly tool (Power BI Desktop) for implementing larger semantic models. And, of course, another important motivation to take this path is reducing licensing cost.

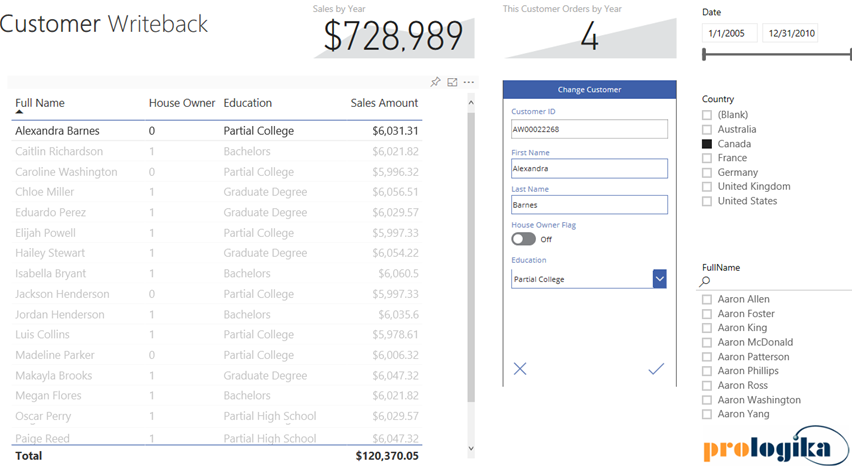
 With hundreds of vendors out there, choosing a BI tool isn’t easy. If you’ve been following me for a while, you know that I love Power BI. One of the Power BI most prominent strengths is that it’s a part of the much broader Microsoft Data Platform that spans various on-premises and cloud offerings for data storage, processing, and analysis. Thanks to this integration, you can implement real-time dashboards, extend your Power BI reports with predictive capabilities, integrate with Big Data, and much more. In this newsletter, I’ll talk about an exciting integration option: extending Power BI with business applications, thanks to its integration with PowerApps and Flow. And if you happen to be in the Microsoft office in Alpharetta, feel free to ask for a demo of the Power BI Writeback that Prologika prepared and deployed to the Microsoft environment. You’ll be directed to one of the big screens when you can test the report that I mention in this newsletter.
With hundreds of vendors out there, choosing a BI tool isn’t easy. If you’ve been following me for a while, you know that I love Power BI. One of the Power BI most prominent strengths is that it’s a part of the much broader Microsoft Data Platform that spans various on-premises and cloud offerings for data storage, processing, and analysis. Thanks to this integration, you can implement real-time dashboards, extend your Power BI reports with predictive capabilities, integrate with Big Data, and much more. In this newsletter, I’ll talk about an exciting integration option: extending Power BI with business applications, thanks to its integration with PowerApps and Flow. And if you happen to be in the Microsoft office in Alpharetta, feel free to ask for a demo of the Power BI Writeback that Prologika prepared and deployed to the Microsoft environment. You’ll be directed to one of the big screens when you can test the report that I mention in this newsletter.