Prologika Newsletter Spring 2019
 At least five of the top 10 IT trends in 2019 identified by Gartner involve machine learning in one form or the other. The list includes autonomous things, augmented analytics, AI-driven development, digital twins, and immersive experience. Gartner also predicts that by 2022, at least 40 percent of new application development projects will have machine learning (ML). Therefore, it’s not surprising to see vendors making huge investments in predictive analytics. This newsletter focuses on two important Power BI enhancements for ML that will be available for public review soon: AutoML and integration with Azure Predictive Analytics services (Azure ML and Cognitive Services).
At least five of the top 10 IT trends in 2019 identified by Gartner involve machine learning in one form or the other. The list includes autonomous things, augmented analytics, AI-driven development, digital twins, and immersive experience. Gartner also predicts that by 2022, at least 40 percent of new application development projects will have machine learning (ML). Therefore, it’s not surprising to see vendors making huge investments in predictive analytics. This newsletter focuses on two important Power BI enhancements for ML that will be available for public review soon: AutoML and integration with Azure Predictive Analytics services (Azure ML and Cognitive Services).
AutoML
The problem with machine learning is that it’s hard and there aren’t that many data scientists out there (or least ones that you can afford). The promise of AutoML is to bring predictive analytics to data analysts just like self-service BI brought descriptive analytics to business users. Power BI AutoML is based on another recent technology introduced by Microsoft: ML.NET. ML.NET is for .NET developers who want to incorporate machine learning features in .NET apps without external dependencies or tools.
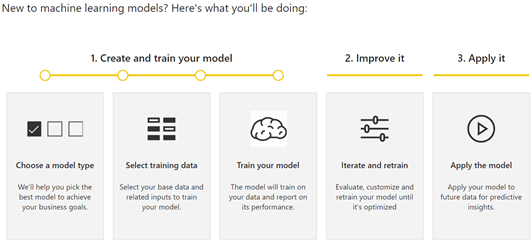
As it stands, Power BI AutoML requires a premium capacity (either via Power BI Premium or Power BI Embedded). The process starts with the data analyst creating an entity containing the data to be predicted. For example, the entity might return a list of customers who have purchased a product in the past with some fields that the data analyst believes are significant to “convert” a customer into a buyer, such as demographics fields. Then, the data analyst can use AutoML to create a predictive model that forecasts the likelihood of future customers to purchase a product. This could be useful for a targeted campaign or to implement “customers who purchased this product have also purchased another product” but many other ML scenarios are possible. The process for implementing an AutoML model is simple and starts with clicking the AI Insights button on the entity page.
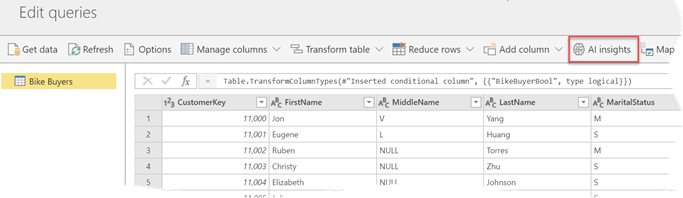
This starts a wizard that walks the data analyst through a few steps that I described in more detail in my “First Look at Power BI AutoML” blog. In the same blog, I shared some ideas to simplify the experience even further that I hope Microsoft will implement.
Integration with Azure ML and Cognitive Services
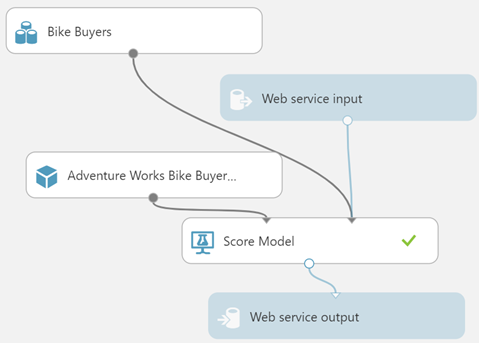
While AutoML is a “quick and dirty” way for data analysts to implement predictive models, data scientists need more control. They have many tools in the Microsoft ecosystem, ranging from R and Python in SQL Server to cloud-based PaaS services, such as Azure ML. One of the easiest tool is Azure ML.However, currently Power BI doesn’t integrate natively with Azure ML experiments, so you must resort to using the Web connector to call the experiment’s web service. I demonstrate how you can do this in a singleton way (one row at a time) in chapter 11 of my latest Power BI book (you can download the code from the book page). This method is still available but it’s cumbersome to implement and it’s slow.
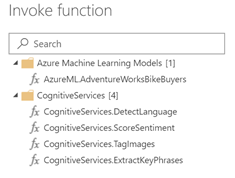
I describe the new Power BI integration in my blog “First Look at the New Power BI Integration with Azure ML “. It offers two important benefits:
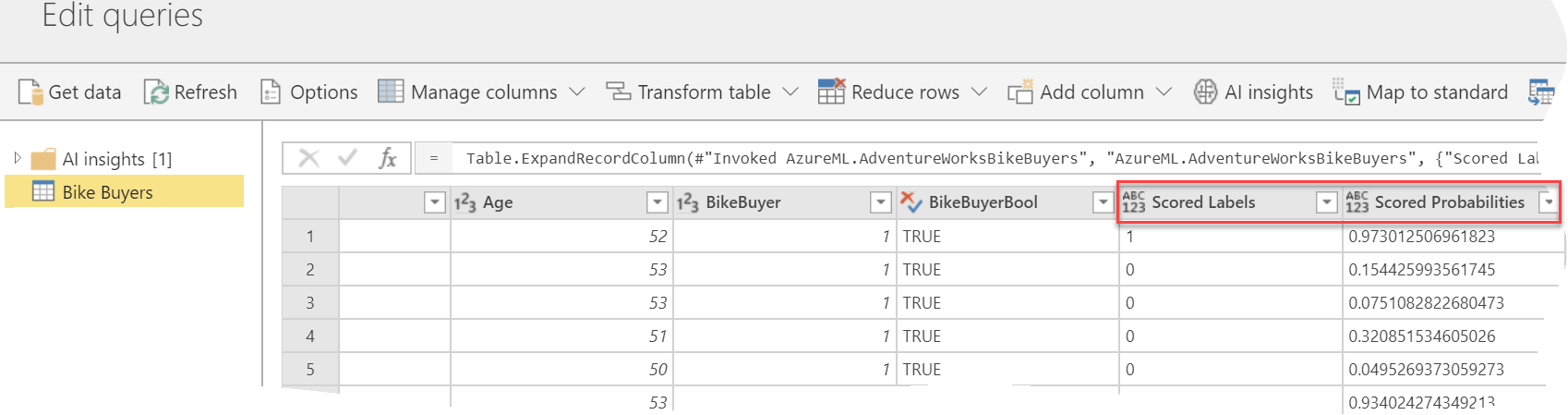
- It simplifies the integration with Azure ML and Cognitive Services – In the case of Azure ML, all you have to do is to select the predictive web service and map the source columns as input to the model. Power BI will invoke the web service and add new predictive columns (in this case, to predict if the customer will be a buyer and the probability for this to happen).

- It’s much faster – Power BI calls the service in batch mode, which is significantly faster than predicting one row at the time.
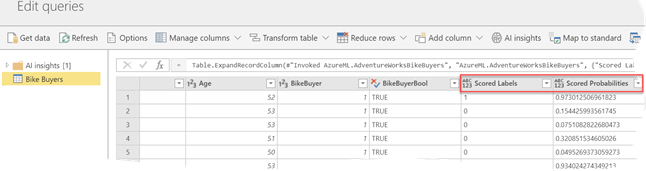
The Cognitive Services integration works in a similar way. It allows you to augment your Power BI data with cognitive features, such as sentiment analysis and image recognition. For more information, watch the related announcements: integration with Cognitive Services and Azure ML, and the new Auto ML features (skip to 1:08:30).
The forthcoming AutoML and Integration with Azure ML and Cognitive Services will be major enhancements to the Power BI predictive analytics capabilities. Both features will be available in public preview soon.

Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
![]()