Synapse Serverless: The Good, The Bad, and The Ugly
When you a provision a Synapse workspace, you get a serverless endpoint for free (or almost free). This endpoint represents Synapse Serverless: a query service for ad-hoc exploration of data in CVS, Parquet, and JSON files stored in Azure Data Lake.
The Good
Being able to query files using SQL is great. Some of you might remember the U-SQL language that was introduced a few years ago alongside Azure Data Lake Storage (ADLS) Gen 1 which is now deprecated. It never caught up because it looked like SQL but it wasn’t (it was actually closer to C#). Now we’re talking about real SQL. To query files! This opens the possibility to implement a logical warehouse (the emphasis is on logical as everyone to my knowledge who tried to replace a data warehouse with a data lake has failed). Or, you can connect Power BI to the serverless endpoint and start querying all these files in DirectQuery mode. So, this enables real-time BI on top of file extracts.
Behind the scenes, Synapse Serverless uses a distributed query engine to conquer and process files in parallel. For more information, read the “POLARIS: The Distributed SQL Engine in Azure Synapse” whitepaper. I ran some limited performance testing and I’m impressed. I’m yet to test joins between large tables (I’d love to hear from someone on this subject).
Pricing is based on the data processed but it’s only $5 per TB. So, export your data in *.parquet files which are smaller and faster (TIP: you can use Azure Data Factory to output Parquet files). Furthermore, Serverless will automatically update statistics for Parquet files (CVS files will require you to update statistics manually) which together with proper partitioning could improve performance for joins and filters so that Serverless doesn’t have to read all the files.
The Serverless feature that I like most though is the flexible schema.
Consider the following query, which defines the expected schema using the WITH clause. Will the query break if a schema drift is detected, e.g. some of the files have additional columns or the column names don’t match? Nope. The query still executes successfully, and if not specified in the WITH clause, the schema drift columns will come back empty. This opens the opportunity to do analytics on top of different schemas which is something you can’t do with your trusted SQL Server!
SELECT
COUNT([Month]), COUNT([Month1])
FROM
OPENROWSET(
BULK ‘https://dvdls01.dfs.core.windows.net/dvdlsfs01/google/*.csv’,
FORMAT = ‘CSV’,
PARSER_VERSION=‘2.0’,
HEADER_ROW = TRUE
)
WITH (
[Year] int,
[Month] NVARCHAR(200),
[Month1] NVARCHAR(200),
[Day] int,
[Ecommerce Conversion Rate] NVARCHAR(50),
[New Users] int
)
AS [result]
The Bad
Currently, Serverless is limited to accessing data stored in ADLS only. I wish Microsoft extends Serverless to other vendors, such as Amazon (S3 and Athena) or Google. As a PaaS offering, there is no option to plug in additional drivers. The same limitation applies to the Synapse SQL Pool by the way. Adding the ORC files to the list of supported file formats will be a good addition, as well as the AVRO format which is generated by the Event Hub Capture.
You can find more crowdsourced improvement ideas at the Synapse Forum.
The Ugly
Now that you have a logical data warehouse, a common requirement is to get that data and load it into a physical data warehouse hosted in the Synapse SQL Pool. Unfortunately, the current architecture keeps the two pools separate (think of them as two different SQL servers). Views saved in a Serverless database are not accessible by the SQL Pool. The SQL Pool doesn’t support OPENROWSET either, so the approach outlined here won’t work. You must use Azure Data Factory or another ETL tool to stage the data in the SQL Pool if you follow the ELT pattern. I’d love to see the SQL Pool extended to support OPENROWSET as Azure SQL Managed Instance does to avoid yet another data movement and data staging.


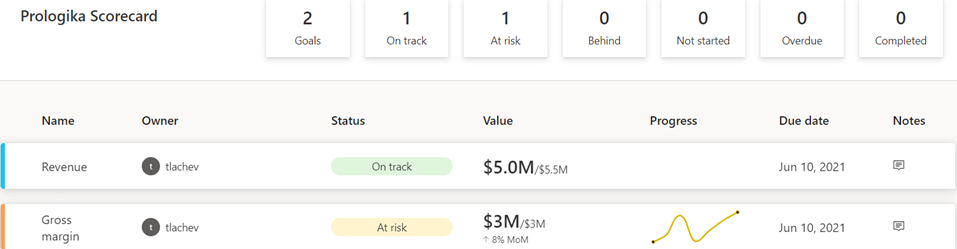
 Business Performance Management (BPM) is a methodology to help the company predict its performance. An integral part of a BPM strategy is creating and monitoring a scorecard with Key Performance Indicators (KPIs). In this newsletter, I’ll discuss how the newly released Power BI Goals can help you augmenet your BPM strategy. But before that, I’d like to share my excitement that Microsoft have recently awarded me
Business Performance Management (BPM) is a methodology to help the company predict its performance. An integral part of a BPM strategy is creating and monitoring a scorecard with Key Performance Indicators (KPIs). In this newsletter, I’ll discuss how the newly released Power BI Goals can help you augmenet your BPM strategy. But before that, I’d like to share my excitement that Microsoft have recently awarded me