I ran into a severe performance issue with the Aggregate function and unrelated dimensions which I reported on connect. In this context, an unrelated dimension is a dimension that doesn’t join any measure group in the cube. Why have unrelated dimensions? My preferred way to implement time calculations is use a regular dimension that is added to the cube but not related to any measure groups. Then, I use scope assignments to overwrite the time calculations, e.g. for YTD, MTD, etc. For example, the scope assignment for YTD might look like:
Notice the use of the Aggregate function which when executed maps to the default aggregation function of the underlying measure. For some reason with SQL Server 2012, a query that uses the Relative Date dimension experiences a significant performance hit. Replacing Aggregate with Sum fixes the issue, assuming you can sum up the affected measure to produce the time calculations.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2013-02-05 13:55:462016-02-16 04:57:16Performance Degradation with the Aggregate Function and Unrelated Dimensions
What options does a PowerPivot user have to refresh data in a PowerPivot model on the desktop, aka PowerPivot for Excel?
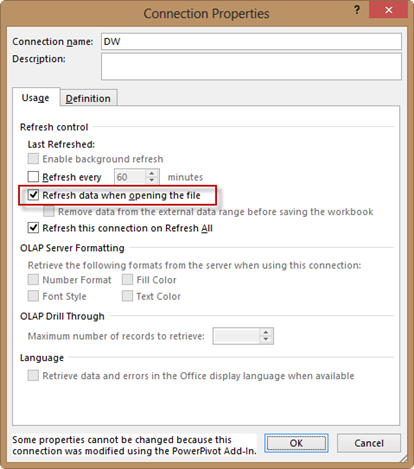
Prior to Excel 2013, the answer was just one – manual refresh by either clicking the Refresh button in the PowerPivot window or the Refresh button in the Existing Connections dialog box. Note that the Refresh button in the Excel ribbon doesn’t work since Excel doesn’t know anything about PowerPivot. Not does the checking the “Refresh data when opening the file” checkbox in the PowerPivot connection. In Excel 2010, these options won’t reopen the PowerPivot connections to the data sources. Instead, the net effect is that they will simply refresh the pivot reports from the pivot cache which is not what you’re after.
Starting with Excel 2013, however, Excel and PowerPivot play better together as I discussed in my What’s New in Office 2013 BI blog. And, now we have additional options to refresh data:
Right-click the pivot report, go to PivotTable Options, click the Data tab, and then click “Refresh data when opening the file”. Enabling this option will refresh the data in the PowerPivot tables that are used on the report when you re-open the Excel workbook file.
In the Excel Data ribbon, click Connections, select the connection you want to refresh, and then click Properties. Notice that all PowerPivot connections are now exposed in the Connections dialog. In the Connections Properties dialog box, check the “Refresh data when opening the file”. This option will open the connection when you open the file, and refresh all PowerPivot tables using the connection.
3. Finally, you can also automate PowerPivot tasks, including refreshing data. For example, if you want to refresh the ResellerSales table on open, you can add the following line to the Workbook_Open() event:
Speaking of automation, everything you can do in the Excel UI is exposed in the object model and automatable in Excel 2013. Here is another example of adding a table from the Excel workbook to the model and then creating a relationship between that table and another table which is already in the model:
Besides the usual hassle configuring PerformancePoint, including insufficient permissions to databases and service accounts, version 2013 requires the SQL Server 2008 R2 drivers. This is surprising considering that SharePoint 2013 shipped after SQL Server 2012.
In a previous blog, I explained how to configure the SharePoint 2013 BI Center. When you go to any of the PerformancePoint-related links, such as Dashboards or PerformancePoint Content, you’ll see the following ribbon.
The Dashboard Designer button is the new way to launch the PerformancePoint Designer. However, when you attempt to configure a data source pointing to Analysis Services, you will likely get an error. The first stop for troubleshooting SharePoint and PerformancePoint issues is of course the Windows Event Log. If you examine the Windows Event Log, you’ll see that PerformancePoint fails to load the 10.0 version of Microsoft.AnalysisServices.AdomdClient. This is the version that’s included in SQL Server 2008 R2. This sends you to the SQL Server 2008 R2 Feature Pack page, from where you can download and install the Microsoft SQL Server 2008 R2 ADOMD.NET library. Now, you can connect to Analysis Services.
The next trip to the SQL Server 2008 R2 Feature Pack page will happen when you try to import (not create) KPIs defined in an Analysis Services cube. This time the error in the Event Log indicates that PerformancePoint requires the 10.0 version of the Microsoft.AnalysisServices dll, which represents the Analysis Services Management Objects (AMO). Back to the SQL Server 2008 R2 Feature Pack, you need to download and install Microsoft SQL Server 2008 R2 Analysis Management Objects. While you there, you might as well download and install Microsoft Analysis Services OLE DB Provider for Microsoft SQL Server 2008 R2 although I don’t think PerformancePoint uses it.
Where should I put my BI reports? Should I upload them to department-level SharePoint sites or put them in one place?
These are common questions that we get from customers. Delivering on the promise of pervasive BI, my preference is to centralize BI artifacts in a single place. Ideally, this BI depository should be the SharePoint Business Intelligence Center. If organizational security is required, you can control security at SharePoint site or library level. For example, you can create department-specific PowerPivot galleries.
The BI Center is one of the SharePoint site templates that is specifically designed to host BI reports. In SharePoint 2013, Microsoft has extended the BI Center to accommodate various types of BI documents.
When I first installed the BI Center in SharePoint 2013 (click Settings (the wheel in the top-right corner), Site Contents, New Subsite, Enterprise Tab, Business Intelligence Center), I was confused. The images are not clickable and the default home page doesn’t offer much more. It turned out that by default, the BI Center doesn’t add a navigation menu. To fix this:
Navigate to the BI Center, navigate to the BI center link.
Click Settings, Site Settings, and click the Navigation link (under the Look and Feel section).
In the Current Navigation section, select the Structural Navigation option.
In the Structural Navigation Sorting section, click Add Heading to add a new menu item for each library your users want to navigate to. To get the links, back to the BI Center, go to Settings, Site Contents, and then right-click the library you are interested in, such as Dashboards, and click Copy Shortcut. Then, paste the shortcut in the URL field in the Navigation Heading dialog box.
This is what the resulting navigation pane might look like. One thing that might not be obvious is that the added benefit of creating your links using the SharePoint structural navigation is that links reflect security. For example, if the user doesn’t have permission to a library, the user won’t see the link. Note that there might be additional steps required, such as to enable the library content types, as with SharePoint 2010.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2013-02-04 01:23:002016-02-16 05:57:42The SharePoint 2013 Business Intelligence Center
In a previous blog “Installing HDInsight Server for Windows”, I introduced you to the Microsoft HDInsight Server for Windows. Recall that HDInsight Server for Windows is a Windows-based Hadoop distribution that offers two main benefits for Big Data customers:
An officially supported Hadoop distribution on Windows server – Previously, you can set up Hadoop on Windows as an unsupported installation (via Cygwin) for development purposes. What this means for you is that you can now set up a Hadoop cluster on servers running Windows Server OS.
Extends the reach of the Hadoop ecosystem to .NET developers by allowing them to write MapReduce jobs in .NET code, such as C#.
And, in previous blogs, I’ve introduced you to Hadoop. Recall that there are two main reasons for using Hadoop for storing and processing Big Data:
Storage – You can store massive files in a distributed and fault-tolerant file system (HDFS) without worrying that hardware failure will result in a loss of data.
Distributed processing – When you outgrows the limitations of a single server, you can distribute job processing across the nodes in a Hadoop cluster. This allows you to perform crude data analysis directly on files stored in HDFS or execute any other type of jobs that can benefit from a parallel execution.
This blog continues the HDInsight Server for Windows journey. As many of you probably don’t have experience in Unix or Java, I’ll show you how HDInsight makes it easy to write MapReduce jobs on a Windows machine.
Note Writing MapReduce jobs can be complex. If all you need is performing some crude data analysis, you should consider an abstraction layer, such as Hive, which is capable for deriving the schema and generating the MapReduce jobs for you. This doesn’t mean that experience in MapReduce is not useful. When processing the files go beyond just imposing a schema on the data and querying the results , you might need programming logic, such as in The New York Times Archive case.
As a prerequisite, I installed HDInsight on my Windows 8 laptop. Because of its prerelease status, the CTP of HDInsight Server for Windows currently supports a single node only which is fine for development and testing. My task is to analyze the same dataset that I used in the MS BI Guy Does Hadoop (Part 2 – Taking Hadoop for a Spin) blog. The dataset (temp.txt) contains temperature readings from weather stations around the world and it represents the weather datasets kept by National Climatic Data Center (NCDC). You will find the sample dataset in the source code attached to this blog. It has the following content (the most important parts are highlighted in red: the year found in offset 15 and temperature found in offset 88).
Note that the data is stored in its raw format and no schema was imposed on the data. The schema will be derived at runtime by parsing the file content.
Installing Microsoft .NET SDK for Hadoop
The Microsoft .NET SDK for Hadoop facilitates the programming effort required to code MapReduce jobs in .NET. To install it:
Install NuGet first. NuGet is a Visual Studio extension that makes it easy to add, remove, and update libraries and tools in Visual Studio projects that use the .NET Framework.
Open Visual Studio (2010 or 2012) and create a new C# Class Library project.
Go to Tools ð Library Package Manager ð Package Manager Console.
In the Package Manager Console window that opens in the bottom of the screen, enter: install-package Microsoft.Hadoop.MapReduce –pre
This command will download the required Hadoop binaries and add them as references in your project.
Coding the Map Job
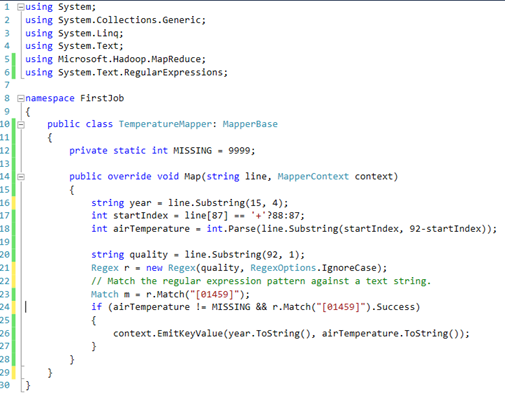
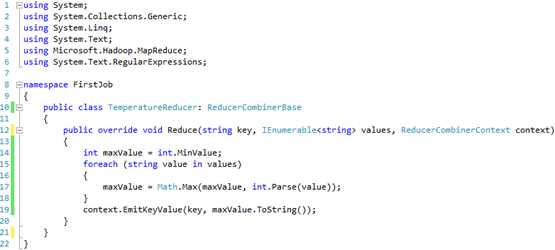
The Map job is responsible for parsing the input (the weather dataset), deriving the schema from it, and generating a key-value pair for the data that we’re interested in. In our case, the key will be the year and the value will be the temperature measure for that year. The Map class derives from the MapperBase class defined in Microsoft.Hadoop.MapReduce.dll.
At runtime, HDInsight will parse the file content and invoke the Map method once for each line in the file. In our case, the Map job is simple. We parse the input and extract the temperature and year. If the parsing operation is successful, we return the key-value pair. The end result will look like this:
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
Coding the Reduce Job
Suppose that we want to get the maximum temperature for each year. Because each weather station might have multiple readings (lines in the input file) for the same year, we need to combine the results and find the maximum year. This is analogous to GROUP BY in SQL. The following Reduce job gets the work done:
The Reduce job is even simpler. The Hadoop framework pre-processed the output of the Map jobs before it’s sent to the Reduce function. This processing sorts and groups the key-value pairs by key, so the input to the Reduce job will look like this:
(1949, [111, 78])
(1950, [0, 22, −11])
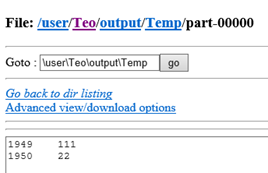
In our case, the only thing left for the Reduce job is to loop through the values for a given key (year) and return the maximum value, so the final output will be:
(1949, 111)
(1950, 22)
Testing MapReduce
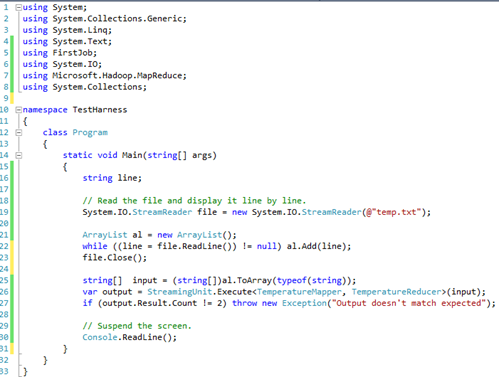
Instead of deploying to Hadoop each time you make a change during the development and testing lifecycle, you can add another project, such as a Console Application, and use it as a test harness to test the MapReduce code. For your convenience, Microsoft provides a StreamingUnit class in Microsoft.Hadoop.MapReduce.dll. Here is what our test harness code looks like:
The code uses a test input file. It reads the content of the file one line at the time and adds each line as a new element to an instance of ArrayList. Then, the code calls the StreamInsight.Execute method to initiate the MapReduce job.
Deploying to Hadoop
Once the code is tested, it’s time to deploy the dataset and MapReduce jobs to Hadoop.
Deploy the file to the Hadoop HDFS file system. C:\Hadoop\hadoop-1.1.0-SNAPSHOT\bin>hadoop fs -copyFromLocal D:\MyApp\Hadoop\MapReduce\temp.txt input/Temp/input.txt
Note When you execute the hadoop command shell in the previous step, the file will be uploaded to your folder. However, if you use the JavaScript interactive console found in the HDInsight Dashboard, the file will be uploaded to the Hadoop folder in HDFS because the console runs under the hadoop user. Consequently, the MapReduce job won’t be able to find the file. So, you use the hadoop command prompt.
2. Browse the file system using the web interface (http://localhost:50070) to see that the file is in your folder.
3. Finally, we need to execute the job with HadoopJobExecutor, which be called in various ways. The easiest way is to use MRRunner D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug>.\mrlib\mrrunner -dll FirstJob.dll
Job\bin\Debug\MRLib\Microsoft.Hadoop.CombineDriver.exe, D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\FirstJob.dll, D:\MyApp\Hadoop\MapReduce\FirstJob\bin\Debug\Microsoft.Hadoop.MapReduce.dll, D
12/12/28 12:35:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
log4j:ERROR Failed to rename [C:\Hadoop\hadoop-1.1.0-SNAPSHOT\logs/hadoop.log] to [C:\Hadoop\hadoop-1.1.0-SNAPSHOT\logs/hadoop.log.2012-12-27].
12/12/28 12:35:20 WARN snappy.LoadSnappy: Snappy native library not loaded
12/12/28 12:35:20 INFO mapred.FileInputFormat: Total input paths to process : 1
12/12/28 12:35:20 INFO streaming.StreamJob: getLocalDirs(): [c:\hadoop\hdfs\mapred\local]
12/12/28 12:35:20 INFO streaming.StreamJob: Running job: job_201212271510_0010
12/12/28 12:35:20 INFO streaming.StreamJob: To kill this job, run:
12/12/28 12:35:20 INFO streaming.StreamJob: C:\Hadoop\hadoop-1.1.0-SNAPSHOT/bin/hadoop job -Dmapred.job.tracker=localhost:50300 -kill job_201212271510_0010
12/12/28 12:35:20 INFO streaming.StreamJob: Tracking URL: http://127.0.0.1:50030/jobdetails.jsp?jobid=job_201212271510_0010
12/12/28 12:35:21 INFO streaming.StreamJob: map 0% reduce 0%
12/12/28 12:35:38 INFO streaming.StreamJob: map 100% reduce 0%
12/12/28 12:35:50 INFO streaming.StreamJob: map 100% reduce 100%
12/12/28 12:35:56 INFO streaming.StreamJob: Job complete: job_201212271510_0010
12/12/28 12:35:56 INFO streaming.StreamJob: Output: output/Temp
4. Using the web interface or the JavaScript console, go to the output folder and view the part-00000 file to see the output (should match your testing results).
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-12-28 20:18:002016-02-16 06:05:19Programming MapReduce Jobs with HDInsight Server for Windows
As another year is winding down, it’s time to review and plan ahead. 2012 was a great year for both Prologika and BI. On the business side of things, we achieved Microsoft Gold BI and Silver Data Platform competencies. We added new customers and consultants. We completed several important projects with Microsoft acknowledging two of them.
2012 was an eventful year for Microsoft BI. SQL Server 2012 was released in March. It added important BI enhancements, including Power View, PowerPivot v2, Reporting Services End-User Alerting, Analysis Services in Tabular mode, Data Quality Services, Integration Services enhancements, MDS Add-In for Excel, Reporting in the Cloud, and self-service BI for Big Data with the Excel Hive add-in. The next BI wave came with Office 2013 and added important organizational and self-service BI features, including PowerPivot Integration in Excel 2013, Power View Integration in Excel 2013, Excel updatable web reports in SharePoint, productivity enhancements (Flash Fill, Quick Explore, Quick Analysis, and so on), PerformancePoint theming support and enhanced filtering, better mobile BI support, and self-service BI in Office 365.
Microsoft added support for Big Data and Hadoop both on cloud with HDInsight Service and on-premises with the CTP release of HDInsight Server. Finally, we got the public prerelease bits of DAXMD to connect Power View to multidimensional cubes.
As we witnessed, BI is a very important part of the Microsoft data strategy. Although overwhelming in times, I hope the trend will continue in 2013 and beyond. In the spirit of the season, here is my top 5 wish list:
Continuing focus on integration and simplification – Fast-paced in nature, Microsoft BI has grown in complexity and redundancy through evolution and product acquisitions. Personally, I’d like to see further unification of the Multidimensional and Tabular models, so BI pros don’t have to choose which path to take and what compromise to make. Integration opportunities exist in other areas, such DQS and MDS, as well Tabular native support in the client tools (Excel and SSRS).
Extending mobile BI reach – Customers are asking for it.
Easier and simpler self-service BI – Excel 2013 has started the path but I think we can do a better job to simplify the user experience and compete more successfully with other self-service BI vendors.
BI in the cloud – This will enable interesting scenarios and extend the reach of BI products and services.
Enterprise lineage and change impact analysis – I think it’s about time to have this.
Most importantly, I hope to see Microsoft B having a renewed focus on customers in 2013. We should be listening more to our customers as sometimes as geeks we tend to be too much caught up in technology and we learn our lesson the hard way.
Microsoft announced yesterday the availability of the Community Technology Preview (CTP) of Microsoft SQL Server 2012 With Power View for Multidimensional Models (aka DAXMD). As a participant of the CTP program and I’m very excited about this enhancement. Now customers can leverage their investment in OLAP and empower business users to author Power View ad-hoc reports and dashboards from Analysis Services cubes. Previously, Power View supported only PowerPivot workbooks or Analysis Services Tabular models as data sources. I’m not going to repeat what T.K. Anand said in the announcement. Instead, I want to emphasize a few key points:
This CTP applies only to the SharePoint-version of Power View. Excel 2013 customers need to wait for another release vehicle to be able to connect Power View in Excel 2013 to cubes.
You’ll need to upgrade both the SharePoint server and SSAS server because enhancements were made in both Power View and SSAS.
Although not supported, I successfully tested that you can install the CTP on top of SQL Server 2012 SP1.
The CTP will not be upgradable to RTM.
It’s not known at this point when and how the RTM bits will ship.
DAXMD doesn’t translate DAX queries to MDX. Instead, the DAX queries are handled natively on the server and performance is awesome!
Kudos to the SSAS and SSRS teams for listening to customers and working together on this feature!
I’ll be presenting What’s New in Excel 2013 and SharePoint 2013 BI at our Atlanta BI Group on Monday, December 3rd.
Microsoft has recently released the 2013 version of Excel and SharePoint. Both technologies include major enhancements for self-service and organizational BI. Join us to review these new features. Learn how business users can quickly analyze and understand data in Power Pivot which is now natively supported by Excel. See how Power View enables rich data visualization and having fun with data both on the desktop and server. Understand the new Excel and SharePoint features for organizational BI that opens new opportunities for analyzing OLAP and Tabular models.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-11-29 13:15:112016-02-16 06:08:50Atlanta BI Group Meeting on Monday, December 3rd
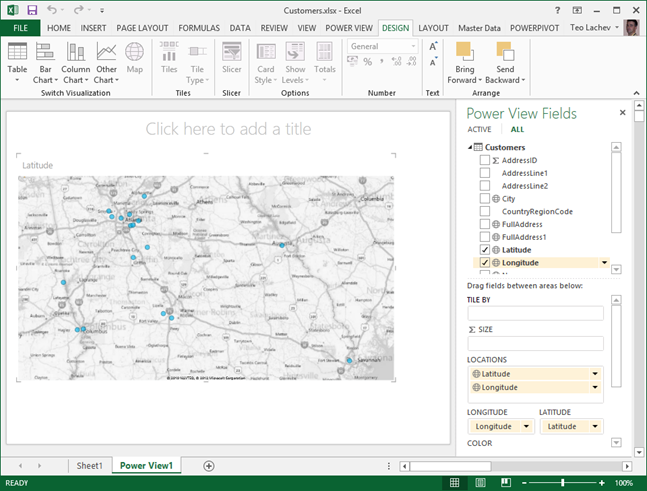
As I wrote before, Power View in Excel 2013 and SharePoint with SQL Server 2012 SP1 supports mapping. The map region supports geocoding and it allows you to plot addresses, countries, states, etc, or pairs of latitude-longitude coordinates. The key for getting this to work is to mark the columns with appropriate categories.
Using latitude-longitude
If you have a SQL Server table with a Geography data type, you can extract the latitude and longitude as separate columns.
SELECT SpatialLocation.Lat, SpatialLocation.Long FROM Person.Address
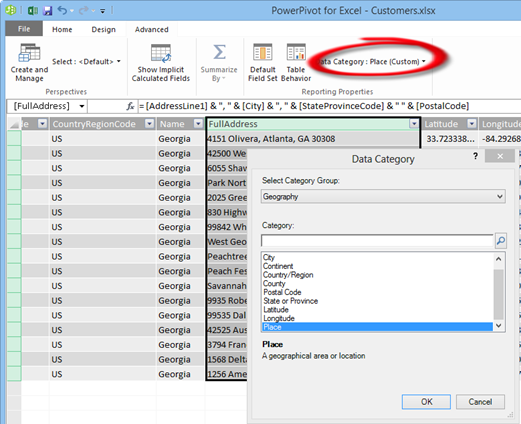
Once you import the dataset in PowerPivot, make sure to categorize the columns using the Advanced tab.
The map region doesn’t support grouping on latitude-longitude so you can’t just place them in the Latitude-Longitude zones and expect it work. Instead, you have to add another field, such as address or both the Latitude-Longitude combination to the Location field. The map groups on the Location zone but uses the Latitude and Longitude to place the points.
Address geocoding
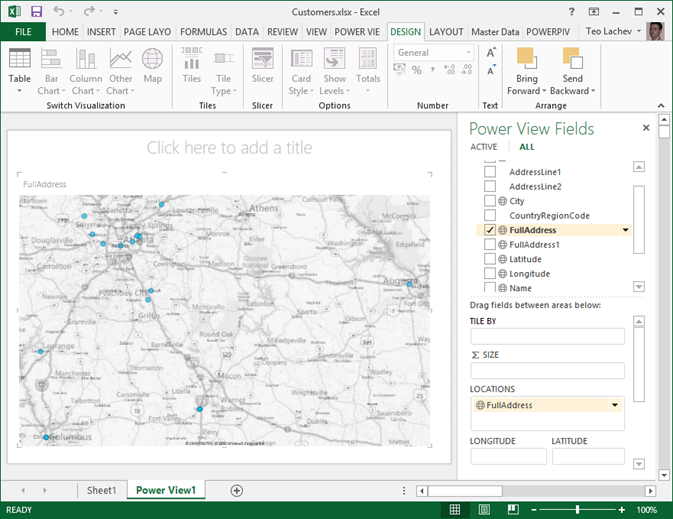
If you don’t have Latitude-Longitude, the map is capable of geocoding full addresses. Again, the trick here is to categorize the FullAddress column as Address. However, if you have invalid addresses, you’ll find that the map won’t show them. Instead, categorize the column as Place, which you can find in the More Categories section (thanks to Sean Boon from the Reporting Services team for the tip).
The map passes to Bing the fact that the field is mapped as Address so it should plot whatever we get back from Bing. The Bing Maps web experience isn’t identical to the API as you can’t pass the Address hint to Bing in the web experience. The Place category is more liberal in terms of what it will attempt to plot.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-11-29 13:08:002016-02-16 06:13:20Geocoding with Power View Maps
I’ve recently had the pleasure to read the book “Microsoft SQL Server 2012 Analysis Services – The BISM Tabular Model” by Marco Russo, Alberto Ferrari, and Chris Webb. The authors don’t need an introduction and their names should be familiar to any BI practitioner. They are all well-known experts and fellow SQL Server MVPs who got together again to write another bestseller after their previous work “Expert Cube Development with Microsoft SQL Server 2008 Analysis Services”. The latest book was published about five months after my book “Applied Microsoft SQL Server 2012 Analysis Services: Tabular Modeling”. Although both books are on the same topic, we didn’t exchange notes when starting on the book projects. In fact, I was well into writing mine when I learned on the SSAS insider’s discussion list about the trio’s new project. Naturally, you might think that the books compete with each other but after reading Microsoft SQL Server 2012 Analysis Services – The BISM Tabular Model” I agree with Marco and Chris that the books actually complement each other pretty well.
A central theme of my book is the continuum of Self-service, Team, and Organizational BI. I felt that it is very important to show how Tabular addresses the needs of both business users and BI pros. Indeed, the Tabular journey can start very unassuming, perhaps with a business user creating a simple personal model, gains popularity and evolves to a deployed model shared by teammates, and finally to a corporate model that is provisioned and sanctioned by IT. Because of this, the first part of the book covers PowerPivot for Excel, the second covers PowerPivot for SharePoint, and the third part covers Analysis Services Tabular. Since my book naturally targets different reader audiences (business users, power BI users, and BI pros), I felt that it was imperative to lower the learning curve as much as possible, such as providing step-by-step instructions for the exercises and video tutorials. Writing a book that targets such a broad base is not easy. To make sure that the book will be well accepted, I had readers who represented each of these groups review the manuscript and provide feedback.
On the other hand, Microsoft SQL Server 2012 Analysis Services – The BISM Tabular Model focuses on the professional side of Analysis Services Tabular and targets mainly BI pros. More than half of the book is devoted on DAX and you’ll be hard pressed to find a better coverage on this topic (a note to myself that DAX deserves more attention if I ever write a revision). Besides DAX, Microsoft SQL Server 2012 Analysis Services – The BISM Tabular Model covers equally well other aspects of Tabular and the author’s real life experience shows through. My favorite chapters are Chapter 11 “Data Modeling in Tabular” and Chapter 12 “Using Advanced Tabular Relationships”.
All in all, any serious BI pro willing to learn Tabular should have this book on the shelf… I hope next to mine.