Power View in Office 2013 brings the following new features:
Integration with Excel 2013 – Microsoft has decoupled Power View from SharePoint and included it in Excel so you can create ad-hoc reports connected to BI models, just like you can create pivot reports. I hope the PerformancePoint Decomposition Tree will follow suit.
New visualizations – This includes interactive and drillable geospatial maps and pie charts.
Better support of tabular models – Power View now supports key performance indicators (KPIs) and hierarchies.
Design and branding enhancements – You can now insert images and change the report theme.
To showcase some of these enhancements, I created a personal BI model based on a customer dataset imported from the AdventureWorksDW2012 database (I attached the Excel workbook). To create a Power View report, click on Insert ð Power View button in the Excel ribbon. This creates an empty Power View report connected to the BI model.
My dataset includes the customer location defined as address, postal code, city, state, and country. I’ve found two ways to visualize geospatial data:
Use longitude and latitude coordinates – Power View doesn’t support SQL Server geography data types. However, if you have a geography data type, extracting the longitude and latitude values is easy. You just need to query the Lat and Long property of the geography data type.
SELECT SpatialLocation.Lat, SpatialLocation.Long FROM Person.Address
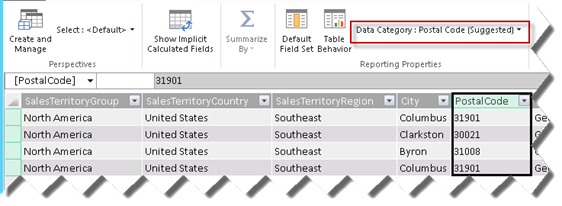
Geocode from an address. If you drop an address field to the Locations zone, the map will prompt you to geocode it. Power Pivot also supports advanced properties and it tries to infer automatically known field categories. For example, in the screenshot below, Power View has identified that the PostalCode field contains zip codes and mapped it to the Postal Code category.
If you place multiple fields in the Locations zone, Power View will allow you to drill down these fields. In my case, I put the StateProvinceName and PostalCode fields in the Locations zone. Consequently, if I double-click on a bubble, Power View will zoom in the map to show me where my customers are located by postal code within that state. I can click the “drill up” in the map right upper corner to go back to the state level.
Note Not sure if this is a bug with the pre-release version of Office 2013, but Power View seems to have a problem with drilling down to entities with the same name. For example, initially I put the City field in the Locations zone but when I drilled down Georgia, Power View switched to Columbus, Ohio because both Ohio and Georgia have a city Columbus. It appears that Power View drills down to the first entity in finds in that level instead of constraining the list to the parent’s children only.
The Power View report also shows a pie chart. If I click a segment on the pie chart it cross-filters the map. For example, if I click the 2005 pie, the map highlights customers with sales in 2005. Vice versa, if I click a bubble in the map, the pie chart gets updated to show the data for that bubble only, such as sales for customers in Georgia. The field list shows that Power View now supports KPIs and hierarchies. The Gross Sales is defined as a KPI in the underlying model and Customers by Country is defined as a hierarchy. Finally, you can change the report theme and add images from the Excel’s Power View ribbon.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-26 00:27:002016-02-16 06:54:42What’s New in Office 2013 BI: Part 2 – Power View Enhancements
Jen Underwood wrote a great summary about what’s new in Office 13 BI. Interestingly, you’ll be able to drill down to lower location in the Power View maps, e.g. from country to state and then to lowest level you placed in the location zone when configuring the map visualization.
In a current project, international users indicated that they prefer dates and numbers to be formatted using their regional settings. Localization is a big and complicated topic and we’ve been fortunate that the scope was limited to just number and date formatting … or, at least so far.
Localizing reports on a report server running in native mode is easy. You just need to use culture –neutral format strings, e.g. C for currency of P for percentage, and set the report-level Language property to =User!Language. However, this is not enough for reports running in a SharePoint integrated mode. SharePoint requires installing language packs as follows:
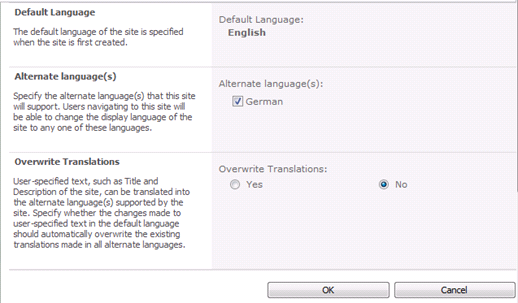
For each language you plan to support, download the corresponding language pack. For example, to download the German language page, change the drop-down to German and download the pack.
Log in a SharePoint Farm Administrator and install the language pack. At the end of the setup process, leave the checkbox to start the wizard in order to run the wizard to reconfigure the farm.
Once the wizard is done, go to the site that you want to localize, click Site Actions -> Site Settings, and then click the Language Settings link under Site Administration.
Check all languages that will be supported on the site.
To avoid “The LocaleIdentifier property is not overwritable and cannot be assigned a new value” error (more than likely a bug) when an international user requests a report connected to an Analysis Services cube, change the connection string of the SSAS data sources to pin it to the locale identifier of the server by appending the following setting, as Kasper De Jonge mentions in his blog: Locale Identifier=1033
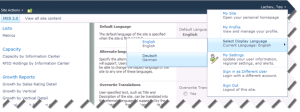
Instruct your users to personalize the display language by expanding the name drop-down and selecting a display language:
Once this is done, the users will see the SharePoint menus translated, and dates and numbers on the reports formatted using the selected display language.
As you probably know by now, Microsoft unveiled the Office 2013 Technology Preview. As the portal page says, “we’ve Taken Self-Service BI to the Next Level”. Indeed, this is where I believe we’ll see Office 2013 emerging as a leading tool on the market for self-service BI. Based on my experience, business users love Excel 2010 with PowerPivot because of its familiar environment and ease of use. However, the Excel visualization capabilities have been lacking. As familiar as they are, pivot table reports are getting somewhat outdated. This is why I put enhanced visualization options on my wish list. This all changes in Office 2013 where the question won’t be “Why we don’t have modern visualization options?” but “Which visualization option should I use?”
Microsoft decoupled Power View from SharePoint and added it to Excel to allow business users to create ad-hoc Power View reports that source data from the personal models that they create in Excel. Speaking of personal models, xVelocity (previously known as VertiPaq) integrates now natively in Excel to power any PivotTable and PivotChart report. Fellow MVPs have already covered some of the new BI features. Check Chris Webb’s Building a Simple BI Solution in Excel 2013 blog series and Thomas Ivarsson’s Power View in Excel 2013 blog series. In this blog, I’ll show you the Excel native integration with xVelocity and explain why you still need PowerPivot. Now that MSDN subscribers can set up a free VM on Windows Azure, I stood up a Virtual Machine that has SQL Server 2012 and Office 13. I plan to add SharePoint 2013 later on. A great solution for my demos!
Suppose you are a business analyst with Adventure Works and you’re tasked to analyze reseller sales data that is kept in the company’s data warehouse.
Unlike Excel 2010, you don’t have to go to the PowerPivot Window to start the import process. Instead, you can use the Excel native import capabilities. Click on Data From Other Data Sources From SQL Server. Then, specify the server name and database.
In the Select Database and Table step, check the “Enable selection of multiple tables” checkbox so we can import multiple tables in one shot. Enabling importing of multiple tables would automatically put the data into the xVelocity store as Excel doesn’t natively support joining tables. Then, check FactResellerSales and click the Select Related Tables button to select all tables that are directly related to FactResellerSales if there are referential integrity constraints defined in the database.
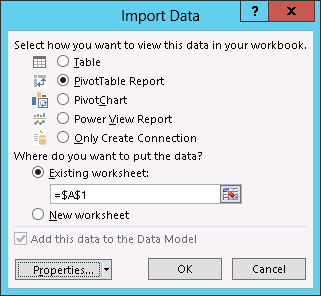
In the Save Data Connection File and Finish step, enter the name of the file name and a friendly name of the connection and click Finish. The Import Data dialog box deserves more attention.
If you chose the first option, Excel will add new sheets with data, each corresponding to a database table. However, if you chose the other options, the data will be imported into the model but no sheets will be added to the workbook. This will be useful if you want to import a table with more than a million rows because Excel still has the limitation of having one million rows per sheet. As with the previous releases, the 64-bit of Excel is preferable if you want to pack lots of data in the xVelocity engine because it can access all the memory as opposed to 2 GB only.
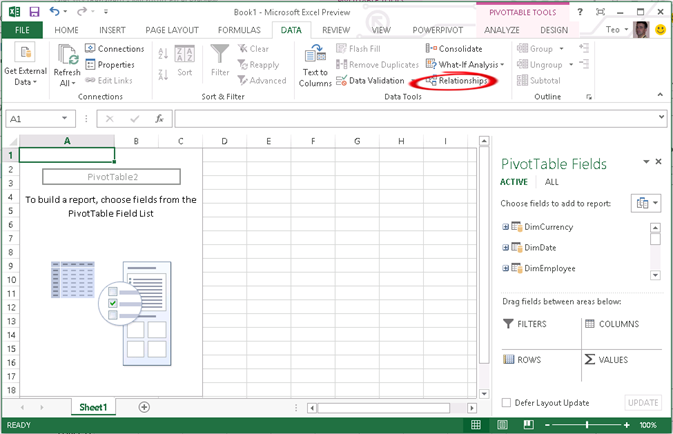
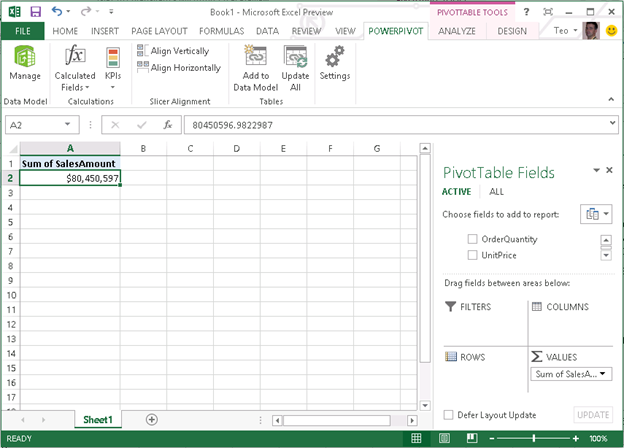
Next, Excel imports the data and adds tables into the internal model, and then shows the tables in the field list (notice that the Excel field list supersedes the PowerPivot Field list). Also, notice that you can click the Relationship button to manage the table relationships as you can do now with PowerPivot for Excel. As you can see, some of the PowerPivot features moved to Excel. From the PivotTable field list ALL tab you can see any other table that exists in the workbook and use them in the pivot.
So, what about PowerPivot for Excel? The add-in is still there but not enabled by default. To enable it, click File ð Options, then click the Add-Ins tab. In the Manage drop-down, select COM Add-ins, and then check the Microsoft Office PowerPivot for Office 2013 add-in. This adds the PowerPivot menu to the Excel ribbon. From the PowerPivot menu, you can click the Manage button to launch the familiar PowerPivot for Excel window. No new PowerPivot features are added to Office 2013.
What can you do with PowerPivot that you can’t do with Excel 15? Here are some reasons to use the add-in:
Add calculated columns to tables in the model
Add calculated measures
Change the metadata, e.g. rename tables and columns, format columns, change column data types
Hide tables and columns so they will not show in the field list
Use the diagram view to visualize the schema, manage relationships, create hierarchies
Using the PowerPivot advanced features, such as perspectives and Power View reporting features
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-23 02:49:002016-02-16 07:03:26What’s New in Office 2013 BI: Part 1 – Personal BI with Excel
Consider the following calculated member definition added to the script in an Analysis Services cube:
CREATE MEMBER CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1;
When you browse the member in Excel, you’ll find that the member is not formatted as currency. However, when you use SSMS and query the member, when you double-click the member cell in the query results, you’ll see that the value is formatted as expected. Clearly, Excel has an issue with formatting calculated members and there is a connect bug report that has been quietly sitting in the Excel bucket for years. To Microsoft credit, we have a KB article “Description of the LANGUAGE cell property in SQL Server 2005 Analysis Services”.
“However, SQL Server 2005 Analysis Services cannot determine the value of the LANGUAGE cell property or of the currency symbol for calculated members from the query context. You must specify the LANGUAGE cell property if you want to obtain a nondefault currency symbol. If you do not specify the LANGUAGE cell property, the numeric value of the cell value and the currency symbol of the cell value may not match.”
I think what they meant was specifying the Language property in the calculated member definition. Indeed, the following change causes Excel to show the calculated member formatted as currency (USD in this case):
CREATE MEMBER CURRENTCUBE.[Measures].[Revenue TTM] AS ([Measures].[Revenue Amount USD], [Relative Date].[TTM]), FORMAT_STRING = “Currency”, VISIBLE = 1, LANGUAGE=1033;
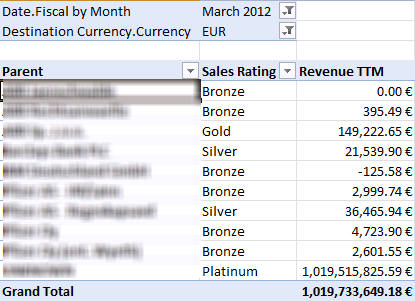
What about dynamic formatting based on the selected currency? Assuming that you have a Destination Currency dimension and includes a Locale column with the integer locale identifier, e.g. 1033 for USD, 1031 for EUR, and so on), the following script overwrites the member language and the value will be formatted based on the destination currency selected by the user:
Language( this ) = [Destination Currency].[Currency].Properties( “Locale” );
End Scope;
TIP On the subject of formatting, you might need to “pin” a calculated member to a particular currency format to avoid the OLAP browser changing the format. As a fist attempt, you might try hardcoding the currency sign, such as “$0,0.00′”. Unfortunately, Excel will ignore it and overwrite it based on the regional settings. For example, a UK user will still see “£100.00”. Hrvoje Piasevoli suggested escaping the currency symbol to prevent this from happening, e.g. create member currentcube.measures.test as 1000.01, format_string=”\$0,0.00″, language=1033;
Since I live in the USA, I have to admit I’m somewhat shielded from the localization complexities surrounding currency and date formatting. Chris Webb wrote a blog “Currency formats: should they be tied to language?” a while back that you should check as well.
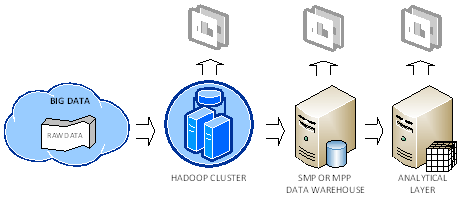
Let’s recap my thoughts on Hadoop. I’ve found the case studies presented in the chapter 16 of the “Hadoop: The Definitive Guide” book very useful to understand how organizations are currently using Hadoop. In general, the following deployment scenario emerges as a common pattern:
An organization accumulates Big Data from various sources, such as web logs, sensors, website traffic, and so on. The organization decides to store the raw data in the Hadoop fault-tolerant file system (HDFS). As far as cost, RainStor published an interesting study about the cost of running Hadoop. It estimated that you need an investment of $375 K to store 300 TB which translates to about $1,250 per terabyte before compression. I reached about the same conclusion from the price of single PowerEdge C2100 database server, which Dell recommends for Hadoop deployments.
Note I favor the term “raw data” as opposed to unstructured data. In my opinion, whatever Big Data is accumulated, it has some sort of structure. Otherwise, you won’t be able to make any sense of it. A flat file is no less unstructured than if you use it as a source for ETL processes but we don’t call it unstructured data. Another term that describes the way Hadoop is typically used is “data first” as opposed to “schema first” approach that most database developers are familiar with.
Saving Big Data in a Hadoop cluster not only provides a highly-available storage but it also allows the organization to perform some crude BI on top of the data, such as by analyzing data in Excel by using the Hive ODBC driver, which I discussed in my previous blog.
The organization might conclude that the crude BI results are valuable and might decide to add them (more than likely by pre-aggregating them first to reduce size) to its data warehouse running on an SMP server or MPP system, such as Parallel Data Warehouse. This will allow the organization to join these results to conformant dimensions to support analyzing data by other subject areas then the ones included in the raw data. The important point here is that Hadoop and RDBMS are not competing but completing technologies.
Ideally, the organization would add an analytical layer, such as an Analysis Services OLAP cube, on top of the data warehouse. This is the architecture that Yahoo! and Klout followed. See my Why an Analytical Layer? blog about the advantages of having an analytical layer.
Note Currently, it’s not possible for an Analysis Services OLAP cube to load data directly from Hadoop because of the subselect queries that the ODBC cartridge injects. PowerPivot or Tabular would work as they use opaque queries (QueryDefinition query bindings).
The world has spoken and Hadoop will become an increasingly important platform for storing Big Data and distributed processing. And, all the database mega vendors are pledging their support for Hadoop. On the Microsoft side of things, here are the two major deliverables I expect from the forthcoming Microsoft Hadoop-based Services for Windows whose community technology preview (CTP) is expected by the end of the year:
A supported way to run Hadoop on Windows. Currently, Windows users have to use Cygwin and Hadoop is not supported for production use on Windows. Yet, most organizations run Windows on their servers.
Ability to code MapReduce jobs in .NET programming languages, as opposed to using Java only. This will significantly broaden the Hadoop reach to pretty much all developers.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-07-01 19:44:002021-02-16 03:52:25MS BI Guy Does Hadoop (Part 5 – The Big Picture)
In my previous blog, I talked about Hive. Hive provides a SQL-like layer on top of Hadoop so you don’t have write tons of MapReduce code to query Hadoop and to aggregate and join data. To facilitate working with Hive, Microsoft introduced a Hive ODBC driver (as of this writing, the driver is only available to Hadoop on Azure CTP subscribers). You can use this driver to connect to Hive running on Microsoft Azure or your local Hadoop server. Danny Lee has provided detailed instructions of how to do the former. I’ll show you how to use it to connect to your local Hive server.
Start the Hive Server
If you use the Cloudera VM, the Hive server is not running by default. This service allows external clients to connect to Hive. To start it:
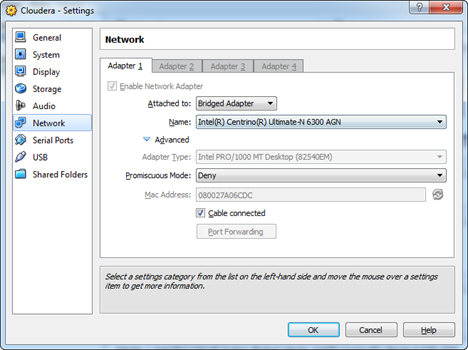
Configure your Cloudera VM to obtain an IP address on your network. To do so in Oracle Virtual Box, go to the VM settings (Network tab), and change the network adapter to Bridge Adapter.
Start the Cloudera VM and open the command prompt.
3.. If your host OS is Windows, edit the C:\Windows\System32\drivers\etc\host file and add an entry for that address, e.g.:
192.168.1.111 cloudera
4. Ping the VM from the host OS to make sure it responds on the DNS name
C:> ping cloudera
5. Start the Hive server using this command:
[cloudera@localhost ]$ hive –service hiveserver
By default, the Hive server listens on port 10000.
Analyze Data in Excel
There are two ways to bring Hive results in Excel and both options require the Hive ODBC driver:
You can use the Hive Pane to import data. This option provides a basic user interface, called a Hive Pane, which is capable of auto-generating Hive queries.
Import Hive tables directly into PowerPivot for Excel.
Using the Hive Pane
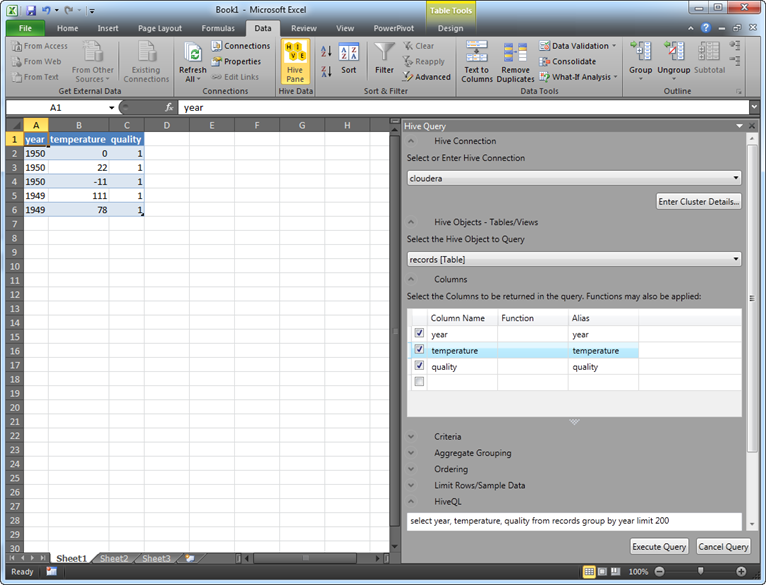
Once you install the Hive ODBC driver, you’ll get a new button in the Data ribbon group called Hive Pane.
Click the Enter Cluster Details button. In the Host field, enter whatever name you specified in the host file (cloudera in my case). Note that the default port is set to 10000. Click OK. You shouldn’t see errors at this point.
Expand the Select the Hive Object to Query and select a table. Select which columns you want to bring in. Optionally, specify criteria, aggregate grouping, and ordering. Notice that by default, the driver brings the first 200 rows but you can use the Limit Rows section to overwrite the default.
Click Execute Query to run the query and generate a table in Excel.
From there on, you can use the Excel native PivotTable and PivotChart reports to analyze data or link the data to PowerPivot.
Importing Data in PowerPivot
The second option is to bypass the Hive Pane and import a Hive table directly into PowerPivot. To do so, you need to set up a file data source first.
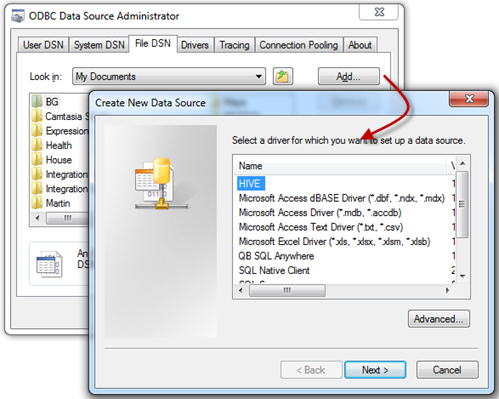
In Windows, go to Administrative Tools and click Data Sources (ODBC).
In the ODBC Data Source Administrator, click the File DSN tab, and then click the Add button.
In the Create New Data Source dialog box, select the HIVE driver.
Click Next and save the file data source, such as in the C:\Users\Teo\Documents\My Data Sources folder. Ignore the warning that pops up.
Back to the ODBC Data Source Administrator (File DSN tab), browse to the folder where you saved the file data source, select it, and click Configure. That will bring you to the same ODBC Hive Setup where you specify the Hadoop server name and port. Close the ODBC Data Source Administrator.
Back to Excel, click the PowerPivot ribbon menu, and then click the PowerPivot Window.
In the PowerPivot Window Home tab, click the From Other Sources button in the Get External Data ribbon group.
In the Table Import Wizard, select the Others (OLEDB/ODBC) option, and then click Next.
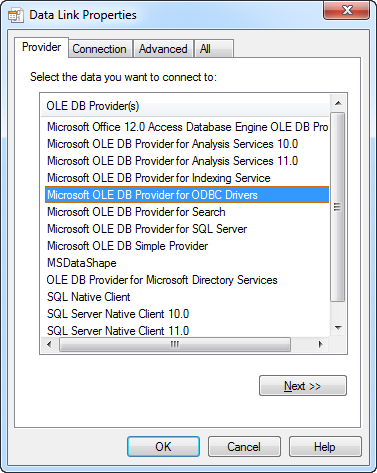
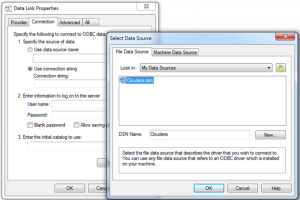
In the Specify a Connection String, click the Build button to open the Data Link Properties.
Select the Provider tab and then select the Microsoft OLE DB Provider for ODBC Drivers.
Select the Connection tab. Select the Use Connection String option, and then click the Build button.
In the Select Data Source dialog box, browse to the folder where you saved the file data source, select it, and then click OK to return back to the Data Link Properties.
The Connection String field should now be populated with the following text:
10. Click the Test Connection button to verify connectivity. Click OK to return to the Table Import Wizard which should now have the following connection string:
A long time ago, I wrote a blog about possible reasons for Reporting Services reports to time out. This issue raised its head again; this time in SharePoint 2010 environment where long running reports would time out after about 2 minutes. To resolve:
On each Web Front End (WFE) server, edit the web.config file of the SharePoint web application. For the default web application, the web.config file is located in C:\inetpub\wwwroot\wss\VirtualDirectories\80.
Find the httpRuntime element and change the executionTimeout setting. The default value is 110 seconds.
Save the web.config file. No need for iisreset since the ASP.NET process will apply the settings on change.
As a side note, you shouldn’t have such report hogs but sometimes you can’t avoid them. In this case, the end users requested a report that includes pretty much all measures in the cube sliced by the dimension with the highest cardinality so they can export it to Excel and analyze it in a pivot table.
UPDATE 6/29/2012
There is more to report timeouts if you have a SharePoint custom page that wraps the SQL Server Reporting Services ReportViewer webpart. In this case, the page won’t overwrite the timeout for the AJAX script manager control. To avoid this, make the following changes to the SharePoint master page:
1. Open the SharePoint Designer and connect to the site.
2. In the Navigation pane, click the Master Pages section.
3. Right-click the master page that site uses (v4.master is the default master page), and click Edit File in Advanced Mode.
4. Locate the ScriptManager element and add an AsyncPostBackTimeout element, as follows:
5. Save the master page, check it in, and approve it (if you use the SharePoint publishing features).
Important If the reports are deployed to a SharePoint subsite, use the SharePoint Designer to connect to the subsite and make the changes to the subsite master page.
Writing MapReduce Java jobs might be OK for simple analytical needs or distributing processing jobs but it might be challenging for more involved scenarios, such as joining two datasets. This is where Hive comes in. Hive was originally developed by the Facebook data warehousing team after they concluded that “… developers ended up spending hours (if not days) to write programs for even simple analyses”. Instead, Hive offers a SQL–like language that is capable of auto-generating the MapReduce code.
The Hive Shell
Hive introduces the notion of a “table” on top of data. It has its own shell which can be invoked by typing “hive” in the command window. The following command shows the Hive tables. I have defined two tables: records and records_ex.
[cloudera@localhost book]$ hive
hive> show tables;
OK
records
records_ex
Time taken: 4.602 seconds
hive>
Creating a Managed Table
Suppose you have a file with the following tab-delimited format:
1950 0 1
1950 22 1
1950 -11 1
1949 111 1
1949 78 1
The following Hive statement creates a records table with three columns.
hive> CREATE TABLE records (year STRING, temperature INT, quality INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’;
Next, we use the LOAD DATA statement to populate the records table with data from a file located on the local file system:
LOAD DATA LOCAL INPATH ‘input/ncdc/micro-tab/sample.txt’
OVERWRITE INTO TABLE records;
This causes Hive to move the file to its repository on local file system (/hive/warehouse). Therefore, by default, Hive will manage the table. If you drop the table, Hive will delete the source data.
Creating an External Table
What if the data is already in HDFS and you don’t want to move the files? In this case, you can tell Hive that the table will be external to Hive and you’ll manage the data. Suppose that you’ve already copied the sample.txt file to HDFS:
CREATE EXTERNAL TABLE records_ex (year STRING, temperature INT, quality INT)
LOCATION ‘/user/cloudera/records_ex’;
LOAD DATA INPATH ‘/input/ncdc/sample.txt’
OVERWRITE INTO TABLE records_ex
The EXTERNAL clause causes Hive to leave the data where it is without even checking if the file exists. The INPATH clause points to the source file. The OVEWRITE clause causes the existing data to be removed.
Querying Data
The Hive SQL variant language is called HiveQL. HiveQL does not support the full SQL-92 specification as this wasn’t a design goal. The following two examples show how to select all data from our table.
hive> select * from records_ex;
OK
1950 0 1
1950 22 1
1950 -11 1
1949 111 1
1949 78 1
Time taken: 0.527 seconds
hive> SELECT year, MAX(temperature)
> FROM records
> WHERE temperature != 9999
> AND quality in (1,2)
> GROUP BY year;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
As you can see from the second example, Hive generates a MapReduce job. Please don’t make any conclusions from the fact that this simple query takes 26 seconds on my VM while it would take a millisecond to execute on any modern relational database. It takes quite a bit of time to instantiate MapReduce jobs and end users probably won’t query Hadoop directly anyway. Besides, the performance results will probably look completely different with hundreds of terabytes of data.
In a future blog on Hadoop, I plan to summarize my research on Hadoop and recommend usage scenarios.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-06-24 23:54:002018-01-15 17:35:33MS Guy Does Hadoop (Part 3 – Hive)
In part 1 of my Hadoop adventures, I walked you through the steps of setting the Cloudera virtual machine, which comes with CentOS and Hadoop preinstalled. Now, I’ll go through the steps to run a small Hadoop program for analyzing weather data. The program and the code samples can be downloaded from the source code that accompanies the book Hadoop: The Definitive Guide (3rd Edition) by Tom White. Again, the point of this exercise is to benefit Windows users who aren’t familiar with Unix but are willing to evaluate Hadoop in Unix environment.
Downloading the Source Code
Let’s start by downloading the book source and the sample dataset:
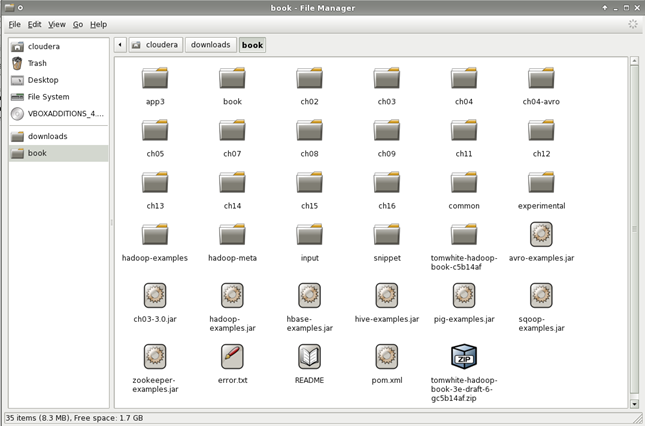
Start the Cloudera VM, log in, and open the File Manager and create a folder downloads as a subfolder of the cloudera folder (this is your home folder because you log in to CentOS as user cloudera). Then, create a folder book under the downloads folder.
Open Firefox and navigate to the book source code page, and click the Zip button. Then, save the file to the book folder.
Open the File Manager and navigate to the /cloudera/downloads folder. Right-click the book folder and click Open Terminal Here. Enter the following command to extract the file: [cloudera@localhost]$ unzip tomwhite-hadoop-book-3e-draft-6-gc5b14af.zip
Unzipping the file, creates a folder tomwhite-hadoop-book-c5b14af and extracts the files in it. To minimize the number of folder nesting, use the File Manager to navigate do the/book/tomwhite-hadoop-book-c5b14af folder, press Ctrl+A to copy all files and paste them into the /cloudera/downloads/books folder. You can then delete the tomwhite-hadoop-book-c5b14af folder.
Building the Source Code
Next, you need to compile the source code and build the Java JAR files for the book samples.
Tip I failed to build the entire source code from the first try because my virtual machine ran out of memory when building the ch15 code. Therefore, before building the source, increase the memory of the Cloudera VM to 3 GB.
Download and install Maven. Think of Maven as MSBUILD. You might find also the following instructions helpful to install Maven.
Open the Terminal window (command prompt) and create the following environment variables so you don’t have to reference directly the Hadoop version and folder where Hadoop is installed:
In the terminal window, navigate to the /cloudera/downloads/book and build the book source code with Maven using the following command. If the command is successful, it should show a summary that all projects are built successfully and place a file hadoop-examples.jar in the book folder.
Next, copy the input dataset with the weather data that Hadoop will analyze. For testing purposes, we’ll use a very small dataset which represents the weather datasets kept by National Climatic Data Center (NCDC). Our task it to parse the files in order to obtain the maximum temperature per year. The mkdir command creates a /user/cloudera/input/ncdc folder in the Hadoop file system (HDFS). Next, we copy the file from the local file system to HDFS using put.
1949 111 # the max temperature for 1949 was 11.1 Celsius
1950 22 # the max temperature for 1950 was 2.2 Celsius
Understanding the Map Job
The book provides detailed explanation of the source code. In a nutshell, the programmer has to implement:
A Map job
(Optional) a Reduce job – You don’t need a Reduce job when there is no need to merge the map results, such as when processing can be carried out entirely in parallel (see my note below).
An application that ties the Mapper and the Reducer.
Note What I learned from the book is that Hadoop is not just about analyzing data. There is nothing stopping you to write a Reduce job that does some kind of processing to take advantage of the distributed computing capabilities of Hadoop. For example, the New York Times used Amazon’s EC2 compute cloud and Hadoop to process four terabytes of scanned public articles and convert them to PDFs. For more information, read the “Self-Service, Prorated Supercomputing Fun!” article by Derek Gottfrid.
if (airTemperature != MISSING && quality.matches(“[01459]”)) {
context.write(new Text(year), new IntWritable(airTemperature));
} } }
The code simply parses the input file line by line to extract the year and temperature reading from the fixed-width input file. So, no surprises here. Imagine, you’re an ETL developer and decide to use code to parse a file instead of using the SSIS Flat File Source, which relies on a data provider to do the parsing for you. However, what’s interesting in Hadoop is that the framework is intrinsically parallel and distributes the ETL job on multiple nodes. The map function extracts the year and the air temperature and writes them to the Context object.
(1950, 0)
(1950, 22)
(1950, −11)
(1949, 111)
(1949, 78)
Next, Hadoop processes the output, sorts it and converts it into key-value pairs. In this case, the year is the key, the values are the temperature readings.
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
} }
Summary
Although simple and unassuming, the MaxTemperature application demonstrates a few aspects of the Hadoop inner workings:
You copy the input datasets (presumably huge files) to the Hadoop distributed file system (HDFS). Hadoop shreds the files into 64 MB blocks. Then, it replicates each block three times (assuming triple replication configuration): to the node where the command is executed, and two additional nodes if you have a multi-node Hadoop cluster to provide fault tolerance. If a node fails, the file can still be assembled from the working nodes.
The programmer writes Java code to implement a map job, a reduce job, and an application that invokes them.
The Hadoop framework parallelizes and distributes the jobs to move the MapReduce computation to each node hosting a part of the input dataset. Behind the scenes, Hadoop creates a JobTracker job on the name node and TaskTracker jobs that run on the data nodes to manage the tasks and report progress back to the JobTracker job. If a task fails, the JobTracker can reschedule the job to run on a different tasktracker.
Once the map jobs are done, the sorted map outputs are received by the node where the reduce job(s) are running. The reduce job merges the sorted outputs and writes the result in an output file stored in the Hadoop file system for reliability.
Hadoop is a batch processing system. Jobs are started, processed, and their output is written to disk.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2012-06-10 00:50:002016-02-16 07:28:18MS BI Guy Does Hadoop (Part 2 – Taking Hadoop for a Spin)