Prologika Newsletter Winter 2025
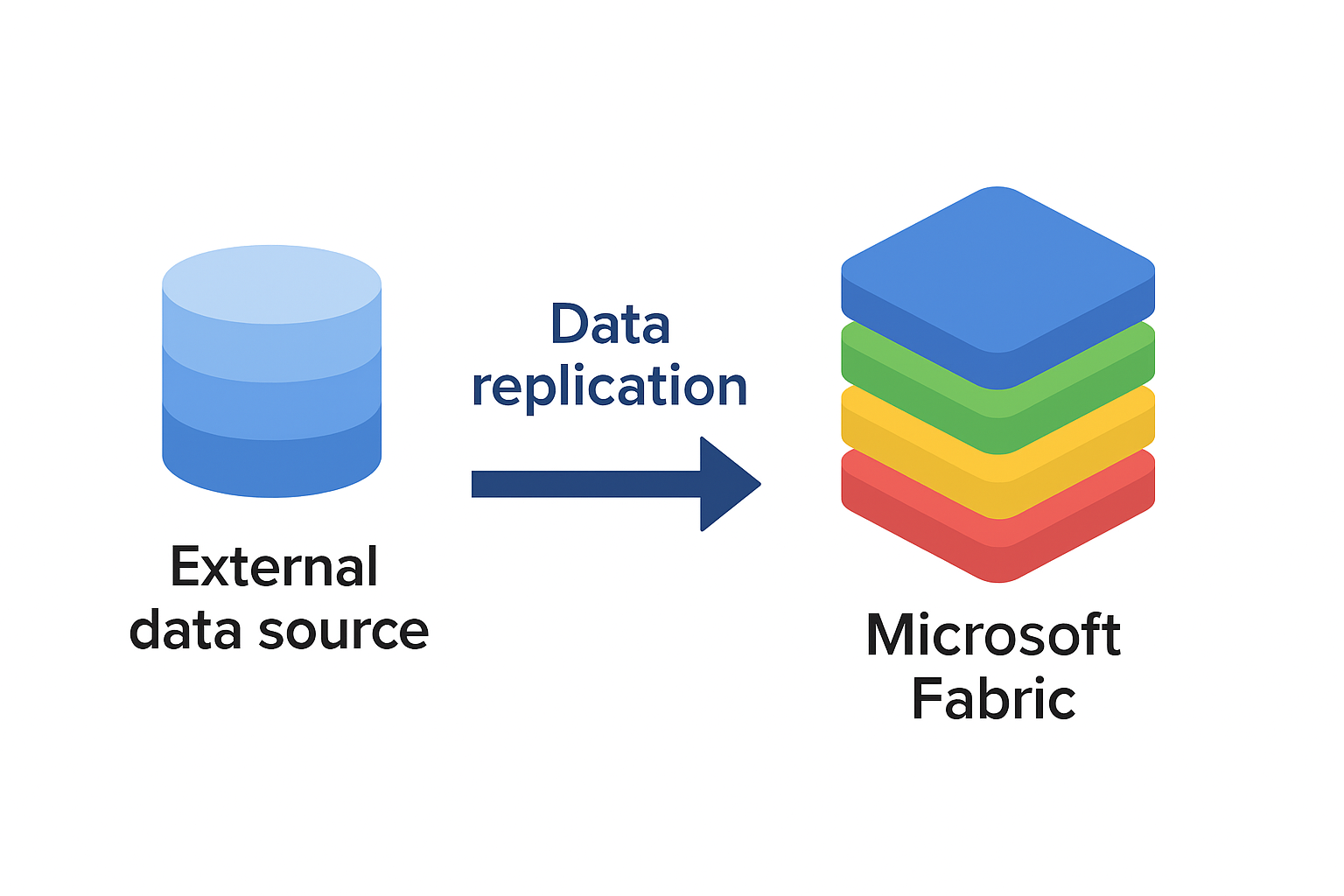
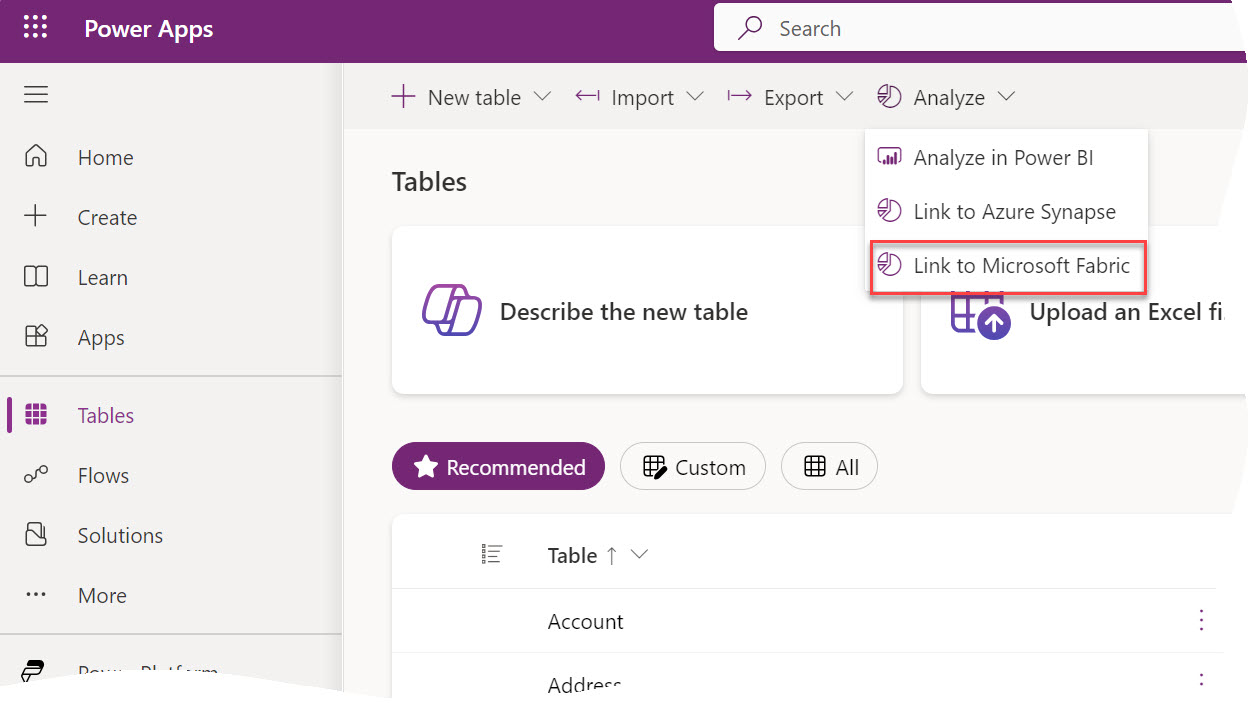
If Microsoft Fabric is in your future, you need to come up with a strategy to get your data in Fabric OneLake. That’s because the holy grail of Fabric is the Delta Parquet file format. The good news is that all Fabric data ingestion options (Dataflows Gen 2, pipelines, Copy Job and notebooks) support this format and the Microsoft V-Order extension that’s important for Direct Lake performance. Fabric also supports mirroring data from a growing list of data sources. This could be useful if your data is outside Fabric, such as EDW hosted in Google BigQuery, which is the scenario discussed in this newsletter.
Avoiding mirroring issues
A recent engagement required replicating some DW tables from Google BigQuery to a Fabric Lakehouse. We considered the Fabric mirroring feature for Google BigQuery (back then in private preview, now in public preview) and learned some lessons along the way:
1. 400 Error during replication configuration – Caused by attempting to use a read-only GBQ dataset that is linked to another GBQ dataset, but the link was broken.
2. Internal System Error – Again caused by GBQ linked datasets which are read-only. Fabric mirroring requires GBQ change history to be enabled on tables so that it can track changes and only mirror incremental changes after first initial load.
3. (Showstopper for this project) The two permissions that raised security red flags are bigquery.datasets.create and bigquery.jobs.create. To grant those permissions, you must assign one of these BigQuery roles:
• BigQuery Admin
• BigQuery Data Editor
• BigQuery Data Owner
• BigQuery Studio Admin
• BigQuery User
All these roles grant other permissions, and the client was cautious about data security. At the end, we end up using a nightly Fabric Copy Job to replicate the data.
Fabric Copy Job Pros and Cons
The client was overall pleased with the Fabric Copy Job.
Pros
- 250 million rows replicated in 30-40 seconds!
- You can have only one job to replicate all tables in Overwrite mode.
- In the simplest case, you don’t need to create pipelines.
Cons
The Copy Job is work in progress and subject to various limitations.
- No incremental extraction
- You can’t mix different load options (Append and Overwrite) so you must split tables in separate jobs
- No custom SQL SELECT when copying multiple tables
- (Bug) Lost explicit column bindings when making changes
- Cannot change the job’s JSON file
- The user interface is clunky and it’s difficult to work with
- No failure notification mechanism. As a workaround: add Copy Job to data pipeline or call it via REST API
Summary
In summary, the Fabric Google BigQuery built-in mirroring could be useful for real-time data replication. However, it relies on GBQ change history which requires certain permissions. Kudos to Microsoft for their excellent support during the private preview.

Teo Lachev
Prologika, LLC | Making Sense of Data
![]()
 Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the
Like the Ancient Greek philosopher Diogenes, who walked the streets of Athens with a lamp to find one honest man, I have been searching for a convincing Fabric feature for my clients. As Microsoft Fabric evolves, more scenarios unfold. For example, Direct Lake storage mode could help you alleviate memory pressure with large semantic models in certain scenarios, as it did for one client. This newsletter summarizes the important takeaways from this project. If this sounds interesting and you are geographically close to Atlanta, I invite you to the December 1st meeting of the 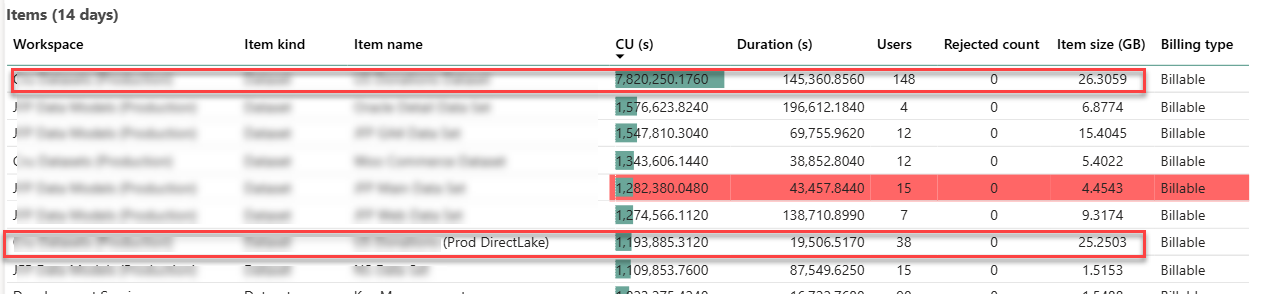

 Looking for easy ways to create intelligent bots or Retrieval-Augmented Generation (RAG) apps?
Looking for easy ways to create intelligent bots or Retrieval-Augmented Generation (RAG) apps?  I conducted recently an assessment for a client facing memory pressure in Power BI Premium. You know these pesky out of memory errors when refreshing a biggish dataset. They started with P1, moved to P2, and now are on P3 but still more memory is needed to satisfy the memory appetite of full refresh. The runtime memory footprint of the problematic semantic model with imported data is 45 GB and they’ve done their best to optimize it. This newsletter outlines a few strategies to tackle excessive memory consumption with large semantic models. Unfortunately, given the current state of Power BI boxed capacities, no option is perfect and at end a compromise will probably be needed somewhere between latency and performance.
I conducted recently an assessment for a client facing memory pressure in Power BI Premium. You know these pesky out of memory errors when refreshing a biggish dataset. They started with P1, moved to P2, and now are on P3 but still more memory is needed to satisfy the memory appetite of full refresh. The runtime memory footprint of the problematic semantic model with imported data is 45 GB and they’ve done their best to optimize it. This newsletter outlines a few strategies to tackle excessive memory consumption with large semantic models. Unfortunately, given the current state of Power BI boxed capacities, no option is perfect and at end a compromise will probably be needed somewhere between latency and performance. When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!
When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!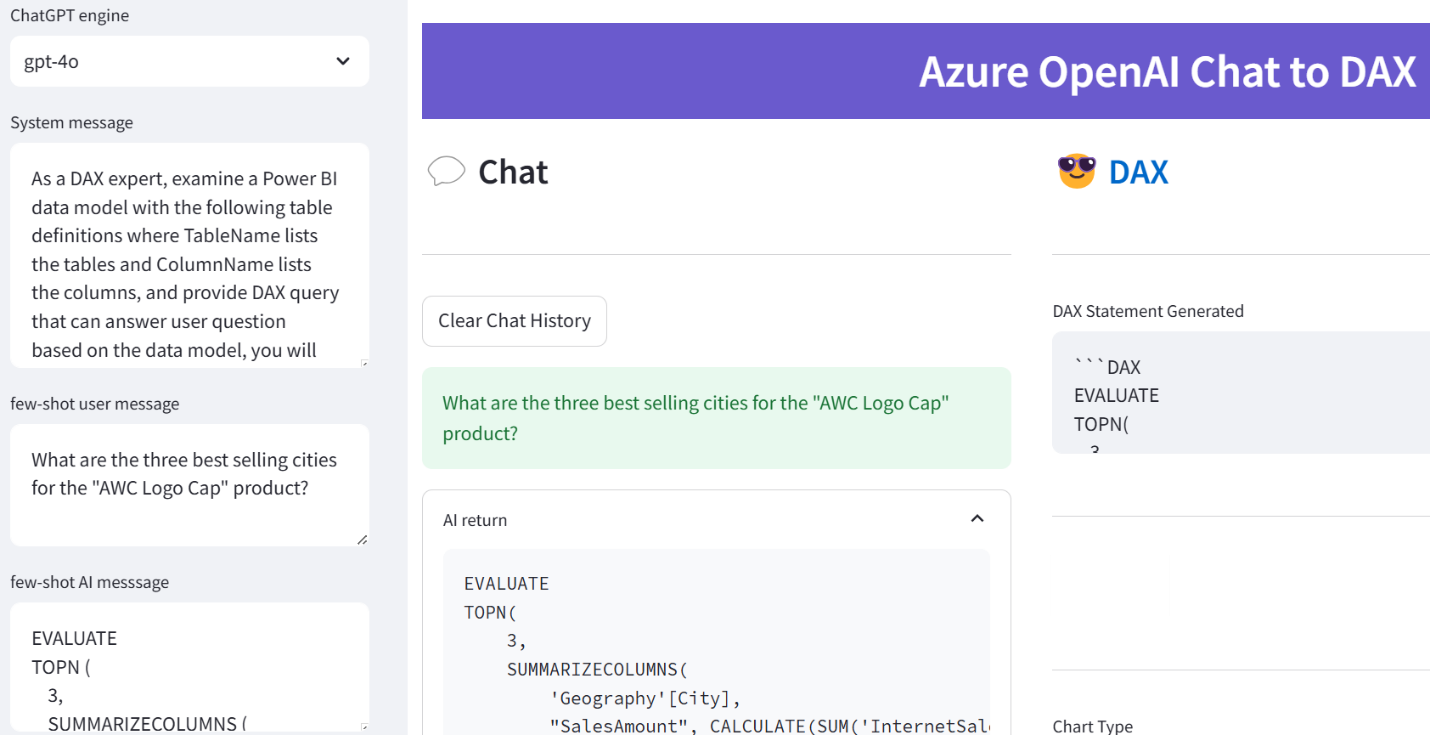
 I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “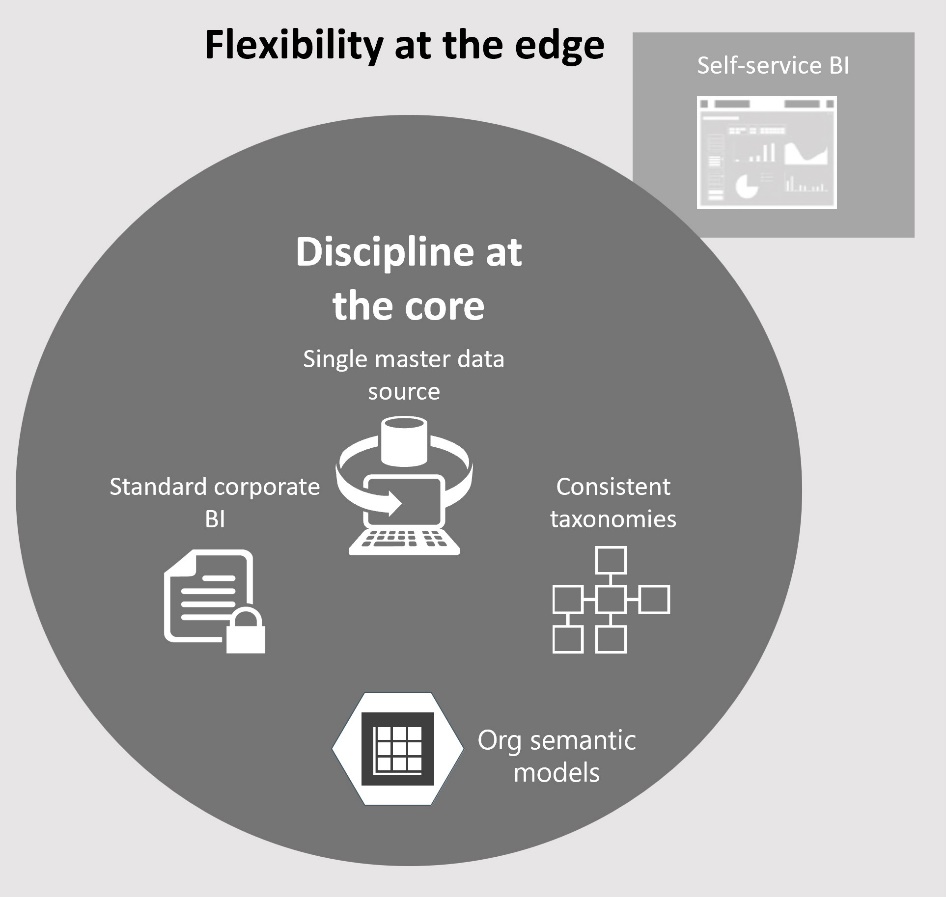
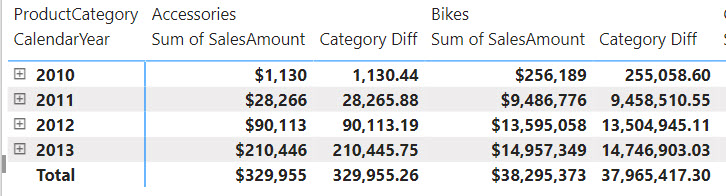
 One of the main goals and benefits of a semantic model is to centralize important business metrics and KPIs, such as Revenue, Profit, Cost, and Margin. In Power BI, we accomplish this by crafting and reusing DAX measures. Usually, implementing most of these metrics is straightforward. However, some might take significant effort and struggle, such as metrics that work at aggregate level. In an attempt to simplify such scenarios, the February 2024 release of Power BI Desktop includes a preview of
One of the main goals and benefits of a semantic model is to centralize important business metrics and KPIs, such as Revenue, Profit, Cost, and Margin. In Power BI, we accomplish this by crafting and reusing DAX measures. Usually, implementing most of these metrics is straightforward. However, some might take significant effort and struggle, such as metrics that work at aggregate level. In an attempt to simplify such scenarios, the February 2024 release of Power BI Desktop includes a preview of 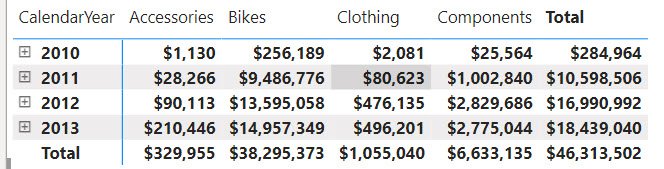
 I’ve covered my first impression about Microsoft Fabric in a
I’ve covered my first impression about Microsoft Fabric in a