I’m helping an enterprise client modernize their data analytics estate. As a part of this exercise, a SSAS Multidimensional financial cube must be converted to a Power BI semantic model. The challenge is that business users ask for almost real-time BI during the forecasting period, where a change in the source forecasting system must be quickly propagated to the reporting the layer, so the users don’t sit around waiting to analyze the impact. An important part of this architecture is the Fabric Direct Lake storage to eliminate the refresh latency, but it came up with a couple of gotchas.
Performance issues with calculated accounts
Financial MD cubes are notoriously difficult to convert to Tabular/Power BI because of advanced features that aren’t supported in the new world, such as Account Intelligence, scope assignments, parent-child hierarchies, and calculated dimension members. The latter presented a performance challenge. Consider the following MDX construct:
CREATE MEMBER CURRENTCUBE.[Account].[Accounts].&[1].[Calculations List].[ROI %]
AS IIF([Account].[Accounts].&[1].[Calculations List].[Average Invested Capital] = 0, NULL, ..,
FORMAT_STRING = "#,##0.0 %;-#,##0.0 %",
This construct adds an expression-based account as though the account is physically present in the chart of accounts. MD evaluates the MDX expression only for that account.
No such a construct exists in Tabular. To provide a similar reporting experience, I attempted to overwrite the Value measure conditionally based on the “current” account, such as:
However, no matter what I tried, the report performance got a big dent (from milliseconds to 10+ seconds) even when the Calculations List account was excluded. Interestingly, report performance in Direct Lake fared 2-3 times worse than an equivalent Power BI imported model.
So, we had to scrap this approach in favor of one of these workarounds:
Pre-calculating the calculated accounts values (materializing)
Pros: same reporting behavior as MD, faster performance compared to MDX expressions
Cons: effort shifted to ETL, potentially impacting real-time forecasting if calculations must be recomputed with each change.
Separate DAX measures
Pros: formulas applied at runtime as MD, no impact on ETL
Cons: different report experience
Excel dropping user-defined hierarchies
Excel never fails to disappoint me. Sad, considering its potential as an alternative reporting client, especially for financial users.
This time Excel pivots decided not to show user-defined hierarchies, which turns out to be a document limitation for DirectQuery and Direct Lake. Microsoft provides no explanation and I’m sure the Excel team has no plans to fix it, as well as to finally embrace DAX and Power BI semantic models.
Luckily, the client uses a third-party Excel-based tool, which provides better report experience and supports user-defined hierarchies. If the Excel limitation becomes an issue, Fabric Direct Lake is expected soon to support composite models. This will let you implement models with hybrid storage, such as importing dimensions, which don’t change frequently, but leave fact tables in Direct Lake. Luckily, Excel supports user-defined hierarchies with imported tables.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2026-02-24 15:17:002026-02-24 15:17:00A Couple of Direct Lake Gotchas
Atlanta BI fans, please join us in person for our next meeting on Monday, January 5th at 18:30 ET. Dean Jurecic will show you how Power BI visual calculations can simplify the process of writing DAX. And your humble correspondent will walk you through some of the latest Power BI and Fabric enhancements. Key2 Consulting will sponsor the meeting. For more details and sign up, visit our group page.
Delivery: In-person Level: Beginner/Intermediate Food: Pizza and drinks will be provided
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (news, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: Do you sometimes get lost in a sea of complicated DAX and wonder if there is an easier way? Is it difficult to drive self-service reporting in your organization because business users aren’t familiar with the nuances of DAX and Semantic Models? Visual Calculations might be able to help!
Introduced in 2024 and currently in preview, this feature is designed to simplify the process of writing DAX and combines the simplicity of calculated columns with the on-demand calculation flexibility of measures. This session is an overview of Visual Calculations and how they can be used to quickly produce results including:
• Background
• Example Use Cases
• Performance
• Considerations and Limitations
Speaker: Dean Jurecic is a business intelligence analyst and consultant specializing in Power BI and Microsoft Fabric with experience across diverse industries, including utilities, retail, government, and education. Dean is a Fabric Community Super User who holds a number of Microsoft certifications and has participated in the “Ask the Experts” program for Power BI at the Microsoft Fabric Community Conference.
Sponsor: Key2 Consulting is a cloud analytics consultancy that helps business leaders maximize their data. We are a Microsoft Gold-Certified Partner and our specialty is the Microsoft cloud analytics stack (Azure, Power BI, SQL Server).
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2025-12-30 07:19:272025-12-30 07:19:27Atlanta Microsoft BI Group Meeting on January 5th (Visual Calculations in Power BI)
When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!
Text2SQL
I have to say that I was impressed with LLM. I used the excellent Ric Zhou’s Text2SQL sample as a starting point inside Visual Studio Code.
The sample uses the Python streamlit framework to create a web app that submits natural questions to Azure OpenAI. I was amazed how simple the LLM input was. Given that it’s trained with many popular languages, including SQL, all you have to do is provide some context, database schema (generated in a simple format by a provided tool), and a few prompts:
[{'role': 'system', 'content': 'You are smart SQL expert who can do text to SQL, following is the Azure SQL database data model <database schema>},
{'role': 'user', 'content': 'What are the three best selling cities for the "AWC Logo Cap" product?'},
{'role': 'assistant', 'content': 'SELECT TOP 3 A.City, sum(SOD.LineTotal) AS TotalSales \\nFROM [SalesLT].[SalesOrderDe...BY A.City \\nORDER BY TotalSales DESC; \\n'},
{'role': 'user', 'content': natural question here'}]
Let’s drill into these prompts.
The first prompt is an example of role prompting which provides context to the model for our intention to act as a SQL expert.
The sample includes a tool that generates the database schema consisting of table and columns in the following format below. Notice that referential integrity constraints are not included (the model doesn’t need to know how the tables are related!)
The next “few shot” prompt assumes the role of an end user who will ask a natural question, such as ‘What are the three best selling cities for the “AWC Logo Cap” product? This is followed by the assistant’s response who hints the model what the correct query should be.
As a Microsoft BI practitioner, the next natural stop was Text2DAX. But wait, we have a Microsoft Fabric Copilot already for this, right? Yes, but what happens when you click the magic button in PBI Desktop? You are greeted that you need to purchase F64 or larger capacity. It’s a shame that Microsoft has decided that AI should be a super-premium feature. Given this horrible predicament, what would an innovative developer strapped for cash do? Create their own copilot of course!
Building upon the previous sample, this is remarkably simple. First, I obtained the model schema using Analysis Services Data Management Views (DMVs). Second, I changed slightly the prompt, along these lines:
“As a DAX expert, examine a Power BI data model with the following table definitions where TableName lists the tables and ColumnName lists the columns, and provide DAX query that can answer user questions based on the data model, you will think step by step throughout and return DAX statement directly without any additional explanation.”
In summary, it appears that LLM can effectively assist us in writing code. The emphasis is on assist because I view the LLM role as a second set of eyes. Hey, what do you think about this problem I’m trying to solve here? LLM doesn’t absolve us from doing our homework and learning the fundamentals, nor it can compensate for improper design. While LLM might not always generate the optimum code and might sometimes fabricate, it can definitely assist you in creating business calculations, generating test queries, and learning along the way.
BTW, you can use any of the publicly available LLM apps, such as Copilot, ChatGPT, Google Gemini or Perplexity (you don’t need the sample app I’ve demonstrated) for Text2SQL and Text2DAX and probably you will obtain similar results if you give it the right prompts. I took this approach because I was interested in automating the process for business users.
In my previous post, I covered how large language models, such as ChatGPT, can be used to convert natural queries to SQL. Let’s now see how Text2DAX fairs. But wait, we have a Microsoft Fabric copilot already for this, right? Yes, but what happens when you click the magic button in PBI Desktop? You are greeted that you need to purchase F64 or larger capacity. It’s a shame that Microsoft has decided that AI should be a super premium feature. Given this horrible predicament, what would a mortal developer strapped for cash do? Create their own copilot of course!
Building upon the previous sample, this is remarkably simple. As I mentioned in the first blog, one great LLM feature is the loose input. To make the schema generation simple, I obtained the table and column names from the Adventure Works semantic model (a *.pbix file opened in PBI Desktop) by running the following query in DAX Studio:
select Table_Name as TableName, Column_Name as ColumnName
from $SYSTEM.DBSCHEMA_COLUMNS
where column_olap_type = 'attribute' and table_name <>'$MySelectedMeasure' and table_name <> '$Parameter' and table_name <> '$DynamicMeasure'
order by table_name
This gave me the model schema in a two-column format (I had to remove the $ in front of the table name which is a relic from OLAP days where dimension names were prefixed with $). Also, notice that I haven’t included model relationships yet.
As a DAX expert, examine a Power BI data model with the following table definitions where TableName lists the tables and ColumnName lists the columns, and provide DAX query that can answer user questions based on the data model, you will think step by step throughout and return DAX statement directly without any additional explanation.
As with Text2SQL, I used a user role prompt to feed a natural question “What are the three best selling cities for the “AWC Logo Cap” product?” followed by an assistant role prompt containing the expected DAX query (noticed that I’ve made a mistake by not using a SUM function to summarize the SalesAmount column):
EVALUATE
TOPN (
3,
SUMMARIZECOLUMNS (
'DimGeography'[City],
"SalesAmount", CALCULATE('FactInternetSales'[SalesAmount], 'DimProduct'[EnglishProductName] = "AWC Logo Cap")
)
)
ORDER BY [SalesAmount] DESC
Then I started asking questions and my amazement grew as the complexity increased. Here are some samples:
What are the three best selling cities for the “AWC Logo Cap” product?
EVALUATE
TOPN (
3,
SUMMARIZECOLUMNS (
'Geography'[City],
"SalesAmount",
CALCULATE (
SUM('InternetSales'[SalesAmount]), -- notice that LLM fixed my syntax error
'Product'[ProductName] = "AWC Logo Cap"
)
),
[SalesAmount], DESC)
What was YTD sales variance for 2012 compared to last year?
— Here LLM switch to a measure definition
VAR CurrentYearSales =
CALCULATE (
SUM('InternetSales'[SalesAmount]),
'Date'[CalendarYear] = 2012,
DATESYTD('Date'[Date])
)
VAR PreviousYearSales =
CALCULATE (
SUM('InternetSales'[SalesAmount]),
'Date'[CalendarYear] = 2011,
DATESYTD('Date'[Date])
)
VAR SalesVariance = CurrentYearSales - PreviousYearSales
RETURN SalesVariance
What was the customer churn in 2012?
Now, this is impressive! To start with, LLM had to discover what a “churn” is and to figure out that it needs a date context. At its first attempt, it created an incorrect measure because the Date dimension doesn’t relate to the Customer dimension.
Relationships are important concept in Power BI semantic modeling, and they are both a blessing and a curse. Thanks to these explicit paths, the end user doesn’t need how to join tables. But they also introduce rigidity and are subject of various limitations, such as that Power BI doesn’t support diamond or closed loop relationships (interestingly, at some point Microsoft was planning to implement UI to prompt the user which path to take but this never materialized.
Let’s now tell the model about the relationships. I added the following after the Table Definitions section to enumerate a few of the model relationships.
Now running the previous query, we get a much better outcome because the measure now evaluates over the InternetSales table. It would have blown my mind if it had used CustomerID (business key) instead of CustomerKey (surrogate key) 😊
In summary, it appears that LLM can effectively assist us in writing code. The emphasis is on assist because I view the LLM role as a second set of eyes. Hey, what do you think about this problem I’m trying to solve here? LLM doesn’t absolve us from doing our homework and learning the fundamentals, nor it can compensate for improper design. While LLM might not always generate the optimum code and might sometimes fabricate, it can definitely assist you in creating business calculations, generating test queries, and learning along the way.
BTW, you can use any of the publicly available LLM apps, such as Copilot, ChatGPT, Google Gemini or Perplexity (you don’t need the sample app I’ve demonstrated) for Text2SQL and Text2DAX and probably you would obtain similar results if you give it the right prompts. I used this app because I was interested in automating the process.
One of the main goals and benefits of a semantic model is to centralize important business metrics and KPIs, such as Revenue, Profit, Cost, and Margin. In Power BI, we accomplish this by crafting and reusing DAX measures. Usually, implementing most of these metrics is straightforward. However, some might take significant effort and struggle, such as metrics that work at aggregate level. In an attempt to simplify such scenarios, the February 2024 release of Power BI Desktop includes a preview of visual calculations that I’ll review in this newsletter.
What’s a Visual Calculation?
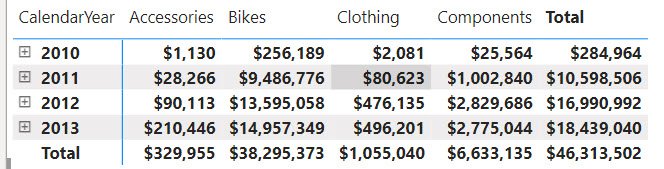
As its name suggests, a visual calculation is a visual-scoped DAX measure that works at the aggregate (visual) level. Don’t confuse the term “calculation” here with calculated columns, tables, or groups. Replace “calculation” with “measure” and you will be fine. Consider the following matrix:
Suppose you need a measure that calculates the difference between the product categories in the order they are sorted in the visual. Implementing this as a regular DAX measure is a challenge. Yet, if we had a way to work with the cells in the visual, we can easily find a way to get this to work. Ideally, this would work similar in Excel, but DAX doesn’t know about relative cell references. However, visual calculations kind of do.
Let’s right-click on the visual and select “New calculation”. Alternatively, click the visual and then click the “New calculation” ribbon button in the Home ribbon. In the visual-level DAX formula bar, enter the following formula:
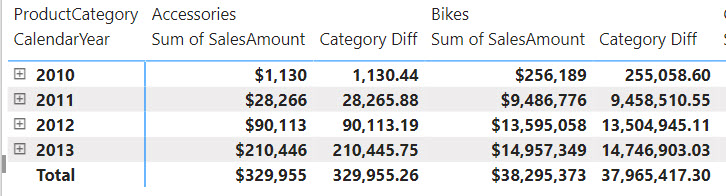
Category Diff = [Sum of SalesAmount] - PREVIOUS([Sum of SalesAmount], COLUMNS)
The Category Diff measure computes the difference between the current “cell” and the cell for the previous category. For example, for Bikes it will be $9,486,776-$28,266 (Accessories value).
The Good
As you can see, visual calculations can simplify aggregate-level metrics. Notice the use of the PREVIOUS function which is one the new DAX functions specifically designed for visual calculations. Notice also that the PREVIOUS function has additional arguments and one of them is the AXIS argument which specifies if the function should evaluate cells positionally on columns or rows. Traditional DAX functions don’t support the AXIS arguments because they are generic and not designed to operate on a visual level.
Finally, notice that visual-level formulas can only reference fields or measures placed in the visual. This is important as you’ll see later.
The Bad
Among the various limitations, the following will cause some pain and suffering:
1. You can’t export the data of a visual that has a visual calculation.
2. Drillthrough is disabled.
3. Can format visual calculations unless the visual supports it (the matrix visual does support measure formatting).
4. Can’t apply conditional formatting.
5. Can’t change sort order.
6. Can’t use field parameters.
The Ugly
The way Microsoft advertises this feature is that it is “easier than regular DAX” and performs better. My concern is that tempted by these promises, users will abuse visual calculations, such as for creating metrics that should be implemented as regular DAX measures so that any visual can benefit from them. And not before long, such users would find themselves into an Excel-like spreadmart hell which is what they tried to avoid by embracing Power BI.
I see a similar issue with DAX implicit measures, which Power BI users create by dragging a field and dropping it on a visual. I consider them a bad practice for a variety of reasons. Microsoft apparently doesn’t share the same concern (see their comments to my LinkedIn post on the same subject here). To their point, because visual calculations can only “see” fields placed in the visual, they naturally shield the user from abusing them. Let’s give it some time and see who’s right. Meanwhile, I wish this documentation article provides best practices and guidance on when to use implicit, explicit, and visual measures, including their limitations.
Visual calculations are incredibly useful but for limited scenarios. Therefore, please use these visual calculations only when regular DAX measures will not suffice. Business metrics should be centralized and should return consistent results, no matter the reporting tool or visual they are placed in. This is important for achieving the elusive single version of truth.
The February 2024 release of Power BI Desktop includes a preview of visual calculations. As its name suggests, a visual calculation is a visual-scoped DAX measure that works at the aggregate (visual) level.
The Good
Visual calculations make previously difficult tasks much easier. Consider the following matrix:
Suppose you need a measure that calculates the difference between the product categories in the order they were sorted in the visual. Implementing this as a regular DAX measure is a challenge. Yet, if we had a way to work with the cells in the visual, we can easily find a way to get this to work. Ideally, this would work similar in Excel, but DAX doesn’t know about relative references. However, visual calculations do (kind of).
Let’s right-click on the visual and select “New calculation”. In the visual-level DAX formula bar, enter the following formula:
Category Diff = [Sum of SalesAmount] - PREVIOUS([Sum of SalesAmount], COLUMNS)
The Category Diff measure computes the difference between the current “cell” and the cell for the previous category. For example, for Bikes it will be $9,486,776-$28,266 (Accessories value).
Notice the use of the PREVIOUS function which is one the new DAX functions specifically designed for visual calculations. Notice also that the PREVIOUS function has additional arguments and one of them is the AXIS argument which specifies if the function should evaluate cells positionally on columns or rows. Finally, notice that visual-level formulas can only reference fields or measures placed in the visual.
The Bad
Among the various limitations, the following will cause some pain and suffering:
1. A visual calculation effectively disables exporting the visual data.
2. Drillthrough is disabled.
3. Can format visual calculations unless the visual supports it (the matrix visual does support measure formatting).
4. Can’t apply conditional formatting.
5. Can’t change sort order.
6. Can’t use field parameters.
The Ugly
The way Microsoft advertises this feature is that it is “easier than regular DAX”. My concern is that tempted by that promise, users will start abusing this feature left and right, such as for creating visual calculations that can be better implemented as regular DAX measures, e.g. for summing or averaging values. And not before long, such users would find themselves into an Excel-like spreadmart hell which is what they tried to avoid by embracing Power BI.
Therefore, please use these visual calculations only when regular DAX measures will not suffice. Business metrics should be centralized and should return consistent results, no matter the reporting tool or visual they are placed in. This is important for achieving the elusive single version of truth.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-28 17:16:162024-03-13 16:17:07A First Look at DAX Visual Calculations: the Good, the Bad, and the Ugly
Suppose you need to calculate a percentage of grand total measure. Easy, you can use the Power BI “Show value as” without any DAX, right? Now suppose that you have 50 Table visuals and each of them require the same measure to be shown as a percentage of total. Although it requires far more clicks, “Show value as” is still not so bad for avoiding the DAX rabbit hole. But what about if you need this calculation in another measure, such as to implement a weighted average? Now, you can’t reference the Microsoft-generated field because it’s not implemented as a measure.
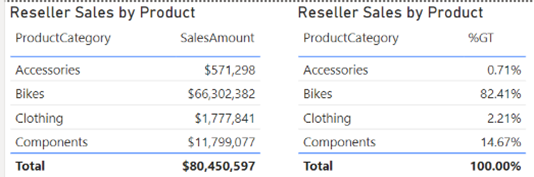
That’s exactly the scenario I faced while working on a financial report, although at the end I followed another approach to calculate the weighted average that didn’t require a percentage of total. Anyway, the question remains. Is there a way to implement a “generic” percent of grand total for a given measure that will work irrespective of what dimensions are used in a Table or Matrix visuals? Consider the following simple report.
We want to show sales as a percentage of total irrespective of what dimension(s) are used in the report. Typically, to implement percentage of total measures you’d implement a DAX explicit measure that overwrites the filter context, such as:
This measure uses the ALL function to remove the filter from the Product table to calculate the sales across any field in that table. But we want this measure to work even if fields from other tables are used as dimensions.
Enter the magical ALLSELECTED function. From the documentation, ALLSELECTED “removes context filters from columns and rows in the current query, while retaining all other context filters or explicit filters”, which is exactly what’s needed. That’s because we want to ignore the context from fields used in the visual but apply other filters, such as slicers and visual/page/report filters, and cross filtering from other visuals.
And that’s all to it except if you need a percentage of column total in a Matrix visual that has a field in the Columns bucket. In this case, ALLSELECTED will ignore not only the dimensions on rows but also dimensions on columns. Then, the net effect will be a generic measure that calculates the percent of grand total instead of column total.
By the way, if you use the “Show value as” built-in feature and capture the query behind the visual, you’ll see that Microsoft follows a rather complicated way to calculate it to handle this scenario. Specifically, the visual generates two queries, where the first computes the visual totals and the second computes the percentage of total.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-01-26 09:59:572023-01-26 09:59:57Implementing “Generic” Percent of Grand Total in DAX
DAX can get complex and humble even experienced BI developers. Since Microsoft left us without a proper debugger, here a couple of techniques that I use to debug DAX when going gets tough:
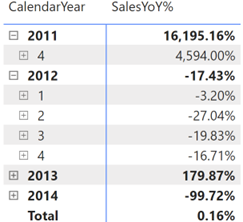
Variables – I often break down the formula in variables. As a bonus, variables make expressions easier to read and might yield performance gains. Consider the following SalesYoY% measure that calculates the variance in sales between the current period and same period last year.
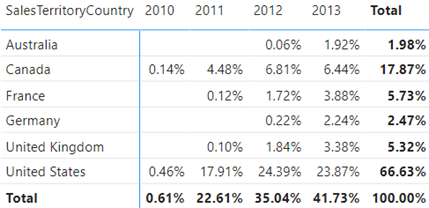
Let’s say you believe that last year’s sales look suspicious, such as the high value for 2011. You can comment the last line and return the LastYearSales variable to investigate further.
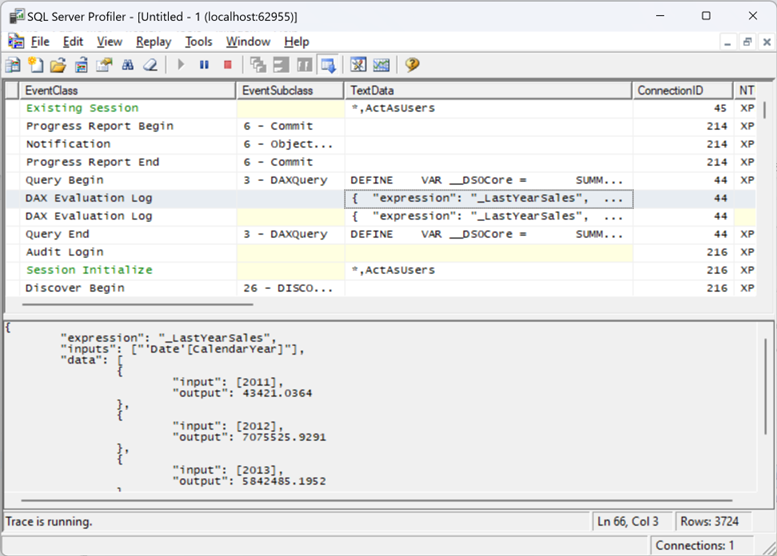
The EvaluateAndLog function – With the introduction of the EvaluateAndLog function in Power BI, Microsoft has provided us with a poor man’s debugger that can print the output of a DAX expression. For example, to investigate the last year’s sales, you can enclose it with EvaluateAndLog.
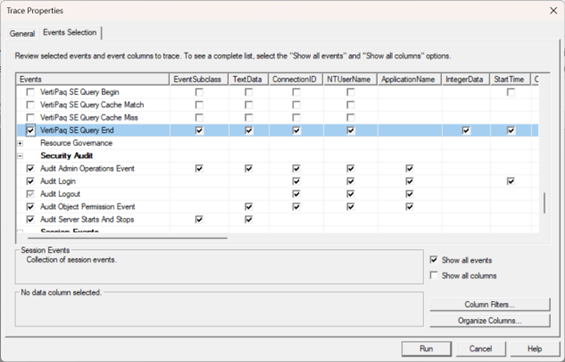
Then, you can use the SQL Server Profiler (distributed with SSMS) or the tool mentioned in the blog to see the output. I have the SQL Server Profiler registered as a Power BI Desktop external tool using the steps in this blog so that I can conviniently launch it connected to the Power BI Desktop model. Once the profiler opens, make sure to select the “DAX Evaluation Log” event.
In this case, the event outputs the last year’s sales broken by year because the visual slices the measure by years.
Usually, DAX queries execute very fast, like flashes in a gold seeker’s pan. Sometimes, however, you could end up with a massive DAX query that takes minutes if not hours. For example, a financial institution requested credit monitoring results to be evaluated overnight and saved in a relational database for fast retrieval. The query involved processing some 300+ measures for 40 million customers and took about an hour to complete. While working on optimizing the query and tracing its execution, I enabled the VertiPaq SE Query End event and was able to monitor how far the query got by seeing which measure is being processed. This was also useful to understand which measures are more expensive.
In general, the server doesn’t process measures in parallel. A measure may produce multiple storage queries, some in parallel and some sequentially. The VertiPaq SE Query End event would show the SQL-like query that the server sent to the storage engine, but usually you can easily correlate it to the DAX formula of the measure being processed. Thanks to the performance enhancements Microsoft is making, such as horizontal fusion, multiple measures may be coalesced into the same storage operation, and therefore a query with multiple measures might yield parallelism or could be sequential. On the other hand, there is plenty of parallelism within a Vertipaq query.
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, June 6th, at 6:30 PM ET. For more details and sign up, visit our group page.
Presentation:
How Power Query Thinks: Taking the Mystery Out of Streaming and Query Folding
How does Power Query produce the table data your expressions ask it to output? Query folding is one key concept—where behind the scenes, part or all of your M code may be rewritten into the data source’s native query language then offloaded to the source for execution. Streaming, though perhaps a less familiar term, is even more fundamental, as it describes how table data (as well as list and binary data) flows between functions in M.
Understand these concepts, and you’ll be better positioned to write more efficient mashups, debug problems and avoid unexpected variability in results. Join this session to learn about these key concepts—in a nutshell, to learn about How Power Query Thinks when you ask it to produce table data!
Speaker:
Author of the Power Query M Primer Series, an in-depth dive into the Power Query language, Ben Gribaudo is a seasoned architect, developer and data engineer.
Prototypes without Pizza
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-06-02 11:33:052022-06-02 11:33:54Atlanta MS BI and Power BI Group Meeting on June 6th (How Power Query Thinks)

 When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!
When it comes to Generative AI and Large Language Models (LLMs), most people fall into two categories. The first is alarmists. These people are concerned about the negative connotations of indiscriminate usage of AI, such as losing their jobs or military weapons for mass annihilation. The second category are deniers, and I must admit I was one of them. When Generative AI came out, I dismissed it as vendor propaganda, like Big Data, auto-generative BI tools, lakehouses, ML, and the like. But the more I learn and use Generative AI, the more credit I believe it deserves. Because LLMs are trained with human and programming languages, one natural case where they could be helpful are code copilots, which is the focus of this newsletter. Let’s give Generative AI some credit!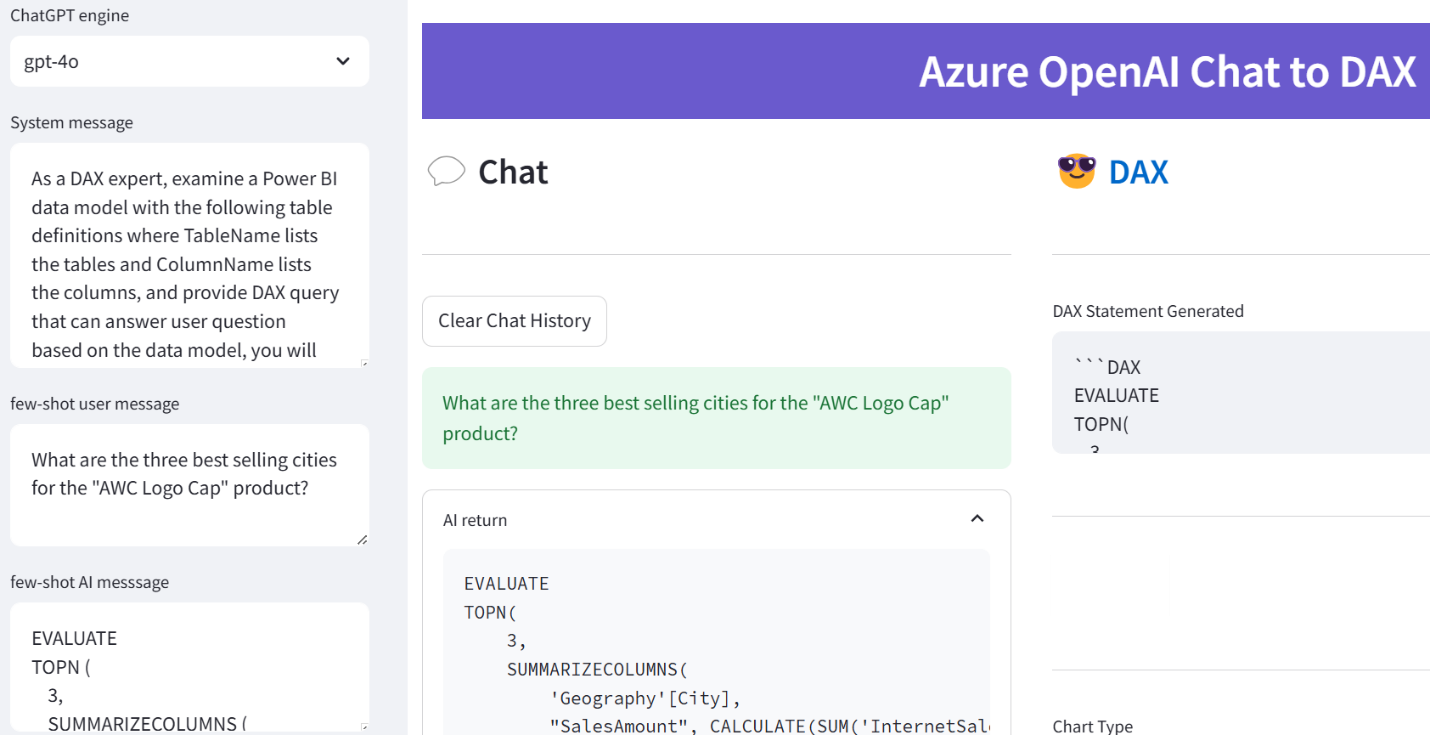

 One of the main goals and benefits of a semantic model is to centralize important business metrics and KPIs, such as Revenue, Profit, Cost, and Margin. In Power BI, we accomplish this by crafting and reusing DAX measures. Usually, implementing most of these metrics is straightforward. However, some might take significant effort and struggle, such as metrics that work at aggregate level. In an attempt to simplify such scenarios, the February 2024 release of Power BI Desktop includes a preview of
One of the main goals and benefits of a semantic model is to centralize important business metrics and KPIs, such as Revenue, Profit, Cost, and Margin. In Power BI, we accomplish this by crafting and reusing DAX measures. Usually, implementing most of these metrics is straightforward. However, some might take significant effort and struggle, such as metrics that work at aggregate level. In an attempt to simplify such scenarios, the February 2024 release of Power BI Desktop includes a preview of