Atlanta MS BI and Power BI Group Meeting on November 4th
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on November 4, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Andy Lawrence will share best practices for impactful Power BI Dashboards. CCG Analytics will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
| Presentation: | Best Practices for Impactful Power BI Dashboards |
| Date: | November 4, 2019 |
| Time | 6:30 – 8:30 PM ET |
| Place: | Microsoft Office (Alpharetta) 8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009 |
| Overview: | Power BI is gaining momentum as a preferred tool for dashboards and interactive reports. Let’s revisit some best practices for dashboard development, such as:
· The importance of form and function · Facilitating user adoption · Mistakes that everyone makes · Fast shortcuts for clean reports · Hidden settings that are lifesavers · Best Power BI updates of 2019 · Live demo of a fast dashboard build · Questions |
| Speaker: | Andy Lawrence is a senior Power BI consultant at CCG Analytics and the leader of the Tampa Power BI user group. He’s a Florida native and a proud UF Gator (MBA) and USF Bull (MIS). At CCG he provides guidance on data modeling, tabular environments, azure administration, DAX writing, T-SQL and data visualization best practices. All of which he can expand upon if you have questions during his presentation. |
| Sponsor: | CCG specializes in deploying solutions that not only provide value to the business but are adopted by users ensuring accountability of the IT driven system. Moving beyond reporting, our Business Intelligence solutions support data governance, quality and standardization across the organization and enable stakeholders with tools like predictive analytics, user-defined alerts, data mining, what-if analysis and visually appealing dashboards. |
| Prototypes with Pizza | “Lineage view” by Teo Lachev |



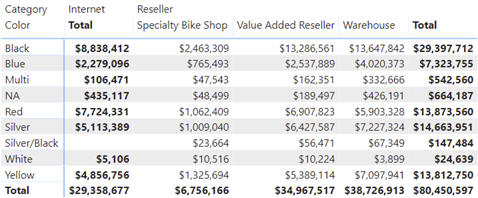
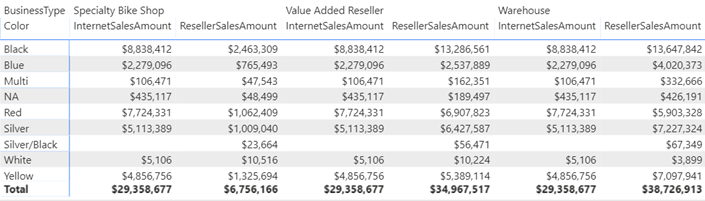
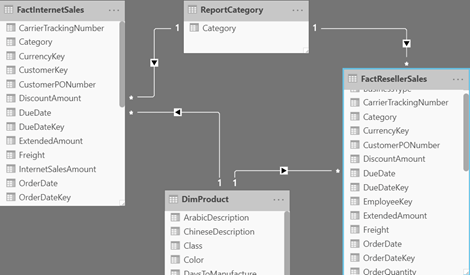

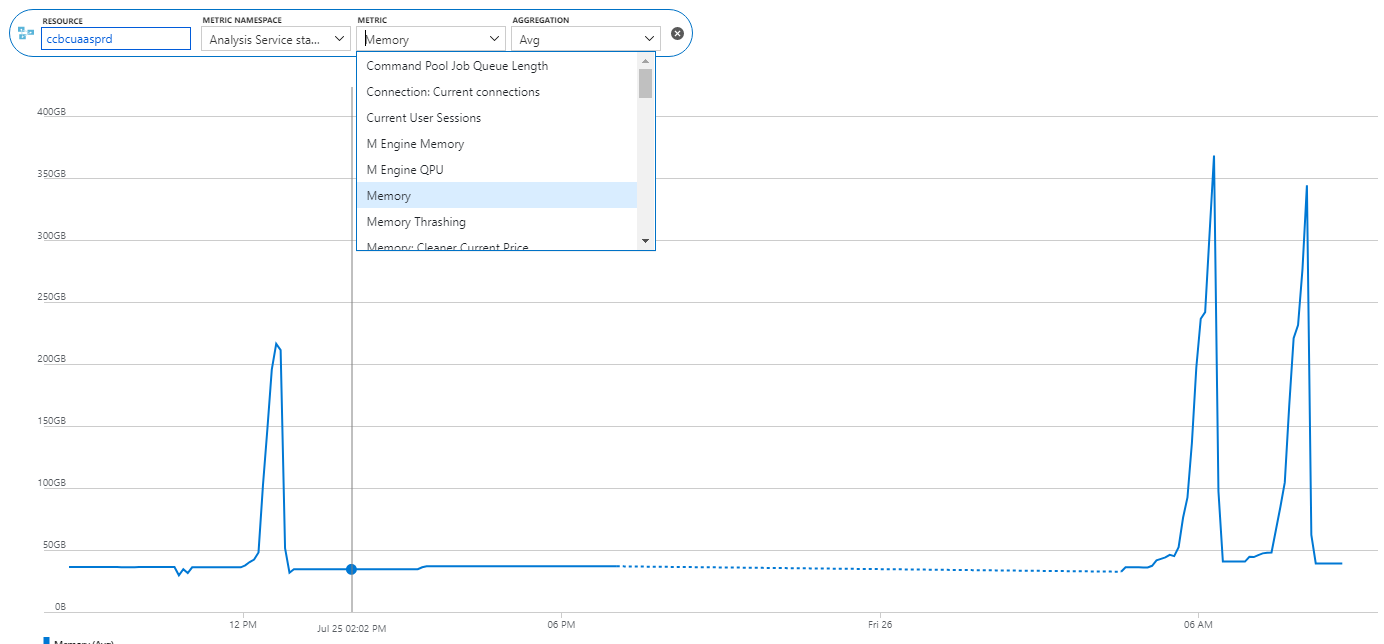
 After learning how to model the data properly (the most important skill), DAX would be the next hurdle in your self-service or organizational BI journey. You won’t get far in Microsoft BI without DAX. This letter shares a tip on how to identify DAX performance bottlenecks by using a recent feature in Power BI called Performance Analyzer.
After learning how to model the data properly (the most important skill), DAX would be the next hurdle in your self-service or organizational BI journey. You won’t get far in Microsoft BI without DAX. This letter shares a tip on how to identify DAX performance bottlenecks by using a recent feature in Power BI called Performance Analyzer. Before I get to Performance Analyzer, I’m excited to announce my latest book:
Before I get to Performance Analyzer, I’m excited to announce my latest book: