SQL Server and 20 Cores Limit
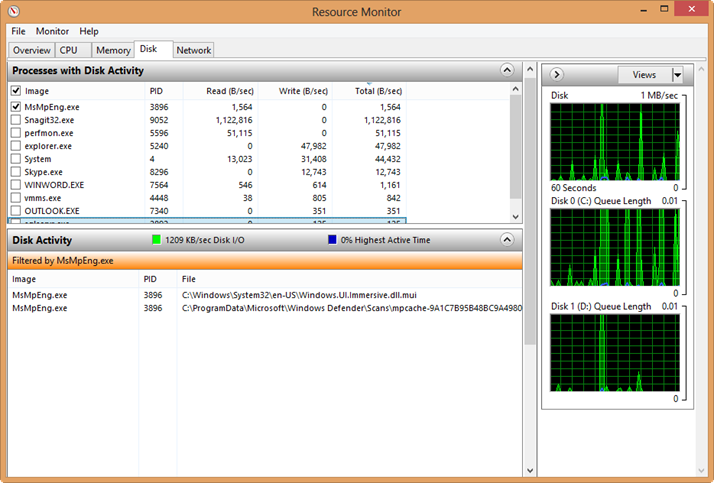
Scenario: You execute a SQL Server 2012 task that uses parallelism, such as index rebuild or a query on a server with more than 20 cores running SQL Server 2012 Enterprise Edition. In the Windows Task Manager, you observe that the task uses only 20 cores. We discovered this scenario during a rebuild of a columnstore index. To confirm this further, you examine the SQL Server log and notice that a similar message is logged when the SQL Server instance starts:
“SQL Server detected 8 sockets with 4 cores per socket and 4 logical processors per socket, 32 total logical processors; using 20 logical processors based on SQL Server licensing. This is an informational message; no user action is required.”
Explanation: More than likely, you have upgraded to SQL Server 2012 from SQL Server 2008 R2 under Software Assurance. Microsoft created a special SKU of Enterprise Edition to support this scenario with the caveat that this SKU limits an instance to using only 20 processor cores (or 40 CPU threads if hyperthreading is enabled). If this level of parallelism is not enough, the only solution is to switch to the Enterprise Edition SKU that is licensed per core and purchase a license that covers as many cores as needed. Once you obtain the new license key, you can upgrade your SQL Server instance:
Setup.exe /q /ACTION=editionupgrade /INSTANCENAME=MSSQLSERVER /PID=<PID key for new edition>” /IACCEPTSQLSERVERLICENSETERMS