Atlanta MS BI and Power BI Group Meeting on February 26th
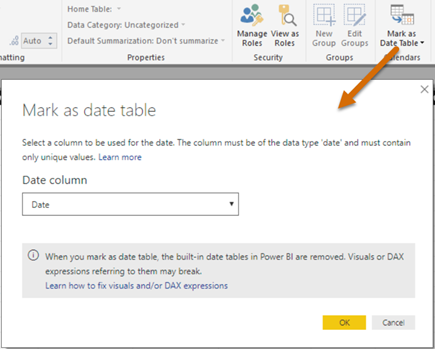
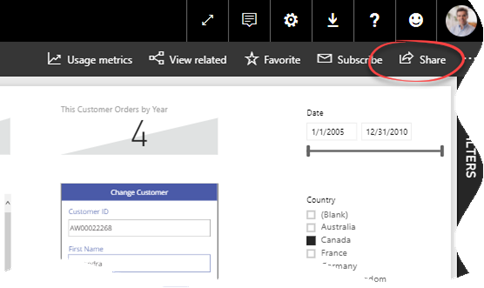
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on February 26th at 6:30 PM. Stacey Jones will explain how Power BI can integrate with other systems, such as Dynamics and Salesforce. SentryOne will sponsor the meeting. And your humble correspondent will show you two latest Power BI features: report sharing and date tables. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the group page) if you’re planning to attend.
| Presentation: |
Integrating Power BI with Dynamics and Other Solutions |
|
Level: Intermediate |
|
|
Date: |
February 26, 2018 |
|
Time |
6:30 – 8:30 PM ET |
|
Place: |
South Terraces Building (Auditorium Room) 115 Perimeter Center Place Atlanta, GA 30346 |
|
Overview: |
Microsoft has differentiated itself for many years as the company that not only sells software, but software that works well together. For example, many companies sold suites of office productivity software, but none sold software that worked as well together as Microsoft Office. We continue that legacy today with Power BI, the leading BI software in the industry, and the integration story is improving, working well with Dynamics as well as leading 3rd party software packages, such as Salesforce! |
|
Speaker: |
Stacey Jones is a Data Solutions Architect and Business Intelligence Evangelist at Microsoft’s Technology Center (MTC) in Atlanta, GA. He has 25+ years of industry experience spanning Database Administration in both Oracle and SQL Server, Database Development, Data Modeling, and most recently as a Data Architect focused in Business Intelligence. He is an industry recognized expert in database tuning, query tuning, and Business Intelligence. He has taught many classes on these subjects and has plenty of real life experience putting out database performance fires. His experience spans the health care and transportation industry. Stacey is active on LinkedIn, you can see his profile at https://www.linkedin.com/in/stacey-jones-05989124 for more information on his industry honors and awards. |
|
Sponsor: |
SentryOne, formerly SQL Sentry, enables data professionals to monitor, diagnose, and optimize server performance across physical, virtual, and cloud environments. Our software provides unparalleled insight, awareness, and control over the true source of performance issues. Headquartered in Huntersville, North Carolina, SentryOne products are sold and supported directly and through authorized resellers and partners. |
| Prototypes with Pizza | “Report sharing and Date tables” by Teo Lachev |