A scheduled SSIS job that executes a massive DAX query to an on-prem Tabular server (Power BI can also generate this error) one day decided to throw an error “Source: “Microsoft OLE DB Provider for Analysis Services.” Hresult: 0x80004005 Description: “MdxScript(Model) (2020, 98) Calculation error in measure ‘Account Snapshot'[Average utilisation % of all CR active current accounts last 3 months]: The result of a conversion or arithmetic operation is either too large or too small.” At least we know the offending measure, but which row is causing the error? The query requests some 300+ measures for 120 million customers, so I thought someone might find the troubleshooting technique useful. Let’s ignore what the measure does for now except mentioning that it performs a division of two other measures.
We can use the DAX ISERROR function to check if a measure throws an error. So, the first step is to wrap the measure with ISERROR and execute the query for all customers.
EVALUATE
FILTER (
CALCULATETABLE (
ADDCOLUMNS (
VALUES ( 'Customer'[Customer Registry ID] ),
"x", ISERROR ( [Average utilisation % of all CR active current accounts last 3 months] )
),
FILTER ( VALUES ( 'Date'[Date] ), 'Date'[Date] = DATEVALUE ( "2022-10-14" ) )
),
[x]
)
The query uses the ADDCOLUMNS function to add the measure so that it’s evaluated for each customer as of the date when the job ran. Make sure to add dependent measures that references the measure in the error description. ISERROR will return TRUE if the measure throws an error. The final step is to wrap CALCULATEDTABLE with FILTER that returns only the offending customer(s) where the measure is TRUE.
Using this technique, I’ve managed to narrow the error to data quality issues concerning large negative credit limits for some customers. BTW, the Tabular engine raises this error when converting a double precision floating point number to an integer, but the former is out of range of valid integer numbers.
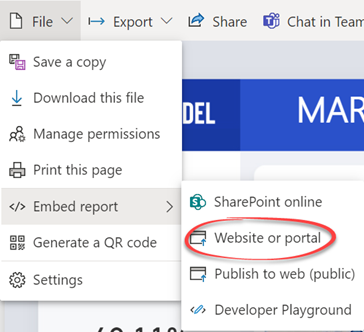
This question pops up over and over. What’s the easiest way to embed a Power BI or paginated report hosted in Power BI Service in an internal portal, such as a custom site developed by your team or on-prem SharePoint Server, so internal users can see all reports in one place? Use the “Embed report” feature that will give you a link or iframe code that you can readily add to the portal without any coding (notice that there is a SharePoint Online option because SharePoint Online has a special webpart for this purpose).
Will you get a single sign-on (SSO) so that the interactive user credentials automatically flow to Power BI? Nope. To the best of my knowledge, Power BI doesn’t support single sign-on even if your organization has extended its active directory to Azure, but let me know if you have found a workaround. The first time the user opens a Power BI report in the browser session, the user will get prompted to enter credentials. Then the user won’t be asked to authenticate when viewing subsequent reports in the browser session because the authentication token will be cashed in the browser session. The browser can also mitigate the issue by saving the user credentials until the password changes.
What if you want to avoid the prompt under any circumstance? Write code and use Power BI Embedded. Down the custom code rabbit hole we go… The upside is that you’ll get more control over the embedded reports thanks to the Power BI JavaScript library, such as if you want to replace the Filter Pane with your filtering mechanism.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-10-12 12:18:312022-10-12 12:18:31Embedding Power BI Reports in Internal Portals
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, October 3rd, at 6:30 PM ET. Tom Huguelet (Lucient) will present a real-world case study and the challenges involved in bringing a Power BI application from initial Excel-based POC to an ISV platform that auto-provisions for new clients, using Power BI Embedded Azure Premium Capacity. For more details and sign up, visit our group page.
Presentation:
Auto-provision embedded report delivery for your customers
In this session we’ll look at a real-world case study and the challenges involved in bringing a Power BI application from initial Excel-based POC to an ISV platform that auto-provisions for new clients, using Power BI Embedded Azure Premium Capacity.
We will cover:
• Initial Business Case and Project Team
• Testing Embedded in a Sandbox Environment (Authentication)
• Enabling User-Customized Experiences in Embedded
• Using REST APIs for automatic Provisioning
• Lessons learned and challenges encountered
Speaker:
Tom Huguelet has been engaged in using Business Intelligence, and Dashboards & Analytics to enable Corporate Performance Management since 1999. While coming from a technological background, Tom has always focused on the people and process aspects of how Business Intelligence can create positive changes within an organization. In his role as a Practice Director, he leads and mentors technical teams as well as advises business stakeholders on how to build the cross-disciplinary teams necessary to be successful with Business Intelligence. Tom holds several Microsoft certifications including Microsoft Certified Trainer, is a frequent speaker at industry events, has co-authored 3 books on SQL Server and Data Warehousing, and helped start a BI Roundtable group in Chicago.
Prototypes without Pizza
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-09-29 11:59:152022-09-29 11:59:15Atlanta MS BI and Power BI Group Meeting on October 3rd (Auto-provision embedded report delivery for your customers)
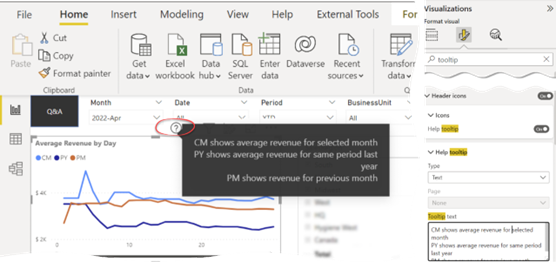
Want to display a visual-left hint to perplexed users that explains what your visual is supposed to reveal? Like me, you’ve probably missed the handy Power BI help tooltips feature that allows you to pop up some helpful text for each visual. On the Format tab of the visualization pane, expand the Help Tooltip section, and enter the text. Then, a question mark glyph shows up in the visual header when the user hovers. Besides showing static text, you could alternatively redirect the user to a report page that could provide more context.
Unfortunately, the tooltip tip can’t be expression-based due to a long-standing and overdue Power BI limitation that only a small set of properties that can be bound to measures.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-09-25 17:24:362022-10-07 16:19:46Power BI Visual Help Tooltips
BI implementation shortcuts are tempting and disguise themselves as cost-effective. True, you can slap a Power BI dataset on top of your data (the cornerstone of self-service BI), but most BI implementations will greatly benefit from a datamart, irrespective of the propaganda of self-service BI vendors. I explain the benefits of datamarts vs Power BI datasets directly on data sources in my blog “Datasets vs. Datamarts”. This newsletter discusses a newly released Power BI feature that attempts to simplify the implementation of datamarts by business users.
Understanding Datamarts
Let’s define a datamart as a centralized repository for hosting clean and trusted data that is typically organized in a star schema, i.e. as a set of fact tables and dimension (lookup) tables. BI pros would typically host a datamart in a relational database. Nowadays, a cloud-based datamart, such as a datamart hosted in Azure SQL Database, Azure SQL Managed Instance, or Azure Synapse, is the norm. Once the datamart schema is designed, a BI pro would use a professional tool, such as Azure Data Factory (ADF) to load the datamart periodically, such as once every night.
As Microsoft announced here, Power BI datamarts are mean to democratize datamart implementations by business users. In my opinion, this is yet another premium feature, spearheaded with great vision and effort, but questionable practical value. In a nutshell, a Power BI datamart is a combo of Power BI Premium and a Microsoft-hosted Azure SQL Database aiming to simplify the implementation of a departmental datamart.
The Good
Unlike other vendors, such as Domo and their proprietary and overly expensive stack, Microsoft has decided to go with somewhat open solution consisting of tools that Power BI users already know: Power Query, Power BI Desktop (for the first time some of its modeling features, such as relationships and DAX measures, made it to the cloud), and SQL Server. Microsoft provisions the database for you although surrounds it with some red tape (more on this in a moment). Thus, a business users aiming for “no code, low code” experience will whip out Power Query dataflows that populate the database and then build a model (dataset) directly in Power BI Service. Obviously, the main goal is to simplify the experience as much as possible where all the action happens online.
It’s nice that Microsoft chose hosting the data in a SQL database instead of a “lakehouse”. Apparently, they learned some painful lessons from Power Query CDM folders. The database size is up to 100 GB which is not bad at all. I also like that some Power BI modeling features finally made it to Power BI Service, but unfortunately only in the confines of the datamart feature.
The screenshot below shows how a business user can use Power Query dataflow to transform and save the data into a Power BI datamart.
The Bad
From the announcement, “Best of all, IT doesn’t have to worry about getting all data into centrally governed data sources, thus providing discipline at the core and flexibility at the edge.” I failed to see how this will provide “discipline at the core” – a tenant that Microsoft learned from their own pain points after tilting too much toward self-service BI. I’ve also seen statements online that business users don’t have to “consult with IT anymore” when implementing datamarts. Really? What happened to managed self-service BI? I’m sure IT will be thrilled having corporate data in Microsoft-owned databases that they can’t manage and queries running amuck and consuming precious premium resources. Luckily, the admin portal has a switch to control who can create these datamarts. I hope at least we have a BYO (bring your own) database feature at some point.
The elastic Azure SQL database that Microsoft provisions is read-only, meaning that you can’t extend it. I’m a big fan of pushing calculations as much upstream as possible to SQL Server, such as by implementing SQL views, but we can’t do that. Instead, we would use Power Query (what else of course) for all data transforms. But I have serious reservations against Power Query dataflows – a tool that is known to cause performance issues without providing any troubleshooting and maintenance insights.
The Ugly
Do we really need this feature? I would argue that what was really needed was extending Power Query with “destinations” where the user can specify where the data would land. If that was implemented, IT could selectively let business users augment the infrastructure set up by IT with self-service ETL (more than likely temporary) that sinks the data into an IT-sanctioned database.
Further, it would have gotten us out of another proprietary mess that forces dataflows to save their output into CDM folders that make sense only to Microsoft (see my “Power BI Dataflows vs ADF Mapping Data Flows” blog for the gory details). Want to save dataflow data somewhere else? For now, you must use Power BI datamarts because this is the only way you can have your data in a (Microsoft-provided) relational database and nowhere else.
Conclusion
Recently, an enterprise client decided to migrate all self-service Alteryx flows to IT-governed ADF pipelines. More than likely, Power BI datamarts will be heading in that direction. Be very careful about any pure self-service features, as you might find yourself in a bigger mess that you tried to solve.
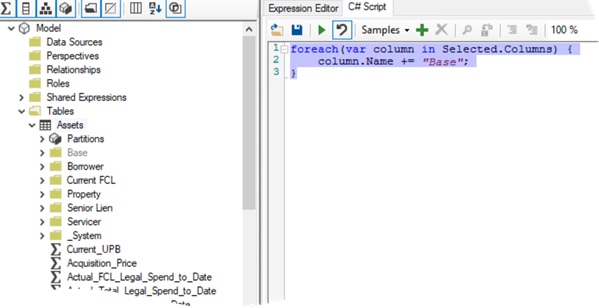
Scenario: You need to rename many columns in a Power BI table. Usually, I rename measure-related columns with “Base” suffix and hide them, and then I create explicit measures. Since renaming one column at the time is no fun, you’re looking for an automated solution. Having heard about the Tabular Editor scripting feature, you’re tempted to whip out a script like this:
You select all columns that must be renamed, run the script, and it appears to work (make sure to enable the Power BI experimental feature in the Tabular Editor Preferences before you run the script since otherwise nothing will happen)! You save the changes, the columns show up with the new names in Power BI Desktop, and you’re about to call it a successful day. But then when you refresh the table, you get greeted with an error that the column already exists and can’t be added, and the refresh operation fails.
Solution: In Power BI Desktop, tables always have a Power Query behind them. The rename operation requires a step in that query for every column that’s renamed.
Therefore, instead of using a Tabular Editor script to rename table columns, add a Renamed Column step to the table query, such as the code below. Unlike columns, you can use a Tabular Editor script to batch-rename measures because they are not physical columns and don’t require a RenameColumns step in Power Query.
Tip: You can use replace and vertical selection features in Microsoft Word to “automate” the code in that step.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-09-16 12:32:562022-09-16 12:37:25Batch Renaming Columns in Power BI Tables
Scenario: You use SSIS to load data for on-prem BI solution. As a last step of the ETL pipeline, you want to refresh a Power BI dataset. There’s quite a bit of misinformation on the Internet about how to do this, hence this blog.
Solution: If the dataset is hosted in Power BI Pro workspace, the only way is to use the Power BI REST APIs and there are some good examples out there using PowerShell or Microsoft Automate flows. However, if the dataset is hosted in a Premium-per-user (PPU) or Premium workspace, you can use the SSIS built-in Analysis Services Processing Task. And, no, you don’t need third-party components.
An unattended process can authenticate against Power BI using either a Power BI-licensed account or service principal. I couldn’t get service principals to work with Power BI datasets. More than likely, this is because the service principal needs to be added as an Analysis Services administrator, but we can’t do with Power BI (we can with Azure Analysis Services though). And so, the only option is to use a Power BI regular account (email and password). However, your organization probably uses multi-factor authentication (MFA) to secure access to cloud services. Because the SSIS process will run unattended, no one will be on a lookout to plug in the authentication code. Therefore, you must harass your helpful system administrator to provide you with a user account that is not enabled for MFA.
And so, the steps are:
Provision a dedicated account in Azure Active Directory. Ideally, the account should have a password that doesn’t expire.
Assign the account (or the AAD Security group it belongs to as a best practice) the Contributor (or higher Power BI role) to the workspace where the dataset resides.
On your dev machine, install both the 32-bit and 64-bit versions of the latest Analysis Services MSOLAP providers. You need the 32-bit provider to test in Visual Studio because VS refuses to go 64-bit. However, if you run the package under SQL Agent, you’d need the 64-bit provider.
In Visual Studio, add a connector to the SSIS project that uses SSIS MSOLAP100 Analysis Services provider, which is just a wrapper on top of the SSAS native MSOLAP provider. Configure the connector to connect to the XMLA dataset endpoint (you can copy it from the dataset settings in Power BI Service).
Configure the SSIS connector to use the “Use a specific user name and password” and plug in the credentials of the dedicated account you configured in step 1.
Gotchas: For some obscure reason, the “Test Connection” button might generate an error, but the processing task should work. Unlike what you might believe, the “Allow saving password” option doesn’t persist the password for security reasons. So, you either need to use an SSIS configuration or retype the password if you close and reopen Visual Studio. Once you deploy the SSIS project to the Integration Services catalog and schedule it with the SQL Agent, make sure to update the connector’s connection string to store the password inside the SQL Agent task.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-09-05 15:52:172022-09-05 15:55:22Refreshing Power BI Datasets from SSIS
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, September 12th, at 6:30 PM ET. Shabnam Watson (Microsoft MVP) will discuss how to reduce the dataset refresh time with incremental refresh policies and how to implement tables with hybrid storage. For more details and sign up, visit our group page.
Incremental Refresh makes it possible for Power BI to handle large datasets by partitioning the data into segments and making refreshes faster, more reliable, and less resource intensive.
Hybrid tables, a new addition, can be easily configured for a table with Incremental Refresh to enable different storage modes for its different partitions. This allows historical data to load into Power BI’s memory (import) for super-fast query performance and to leave the most recent data in the backend (DirectQuery) for near real time results.
Speaker:
Shabnam Watson is a Microsoft Data Platform MVP and Business Intelligence consultant with 20 years of experience developing Data Warehouse and Business Intelligence solutions. She has worked across several industries including Supply Chain, Finance, Retail, Insurance, and Health Care. Her areas of interest include Power BI, Analysis Services, Performance Tuning, PowerShell, DevOps, Azure, Natural Language Processing, and AI. Her work focus within the Microsoft BI Stack has been on Analysis Services and Power BI. She is a regular speaker and volunteer at national and local user groups and conferences. She holds a bachelor’s degree in Computer Engineering, a master’s degree in Computer Science, and a Certified Business Intelligence Professional (CBIP) certification by The Data Warehouse Institute (TDWI).
Prototypes without Pizza
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-09-05 11:40:392022-09-05 11:40:39Atlanta MS BI and Power BI Group Meeting on September 12th (Incremental Refresh and Hybrid Tables in Power BI)
BI practitioners, myself included, have been following the Kimbal tenets for dimensional schema design for years. In fact, it’s a second nature to dimensionalize every BI project the “proper” way. You identify fact tables, grain, dimensions, etc. Dimensions of course would have surrogate keys – your insurance against weird things happening down the road, such as tracking Type 2 changes, unreliable business keys, acquisitions, and what not. Of course, there are downsides. A lot of time is spent on the dimension design – regular dimensions, junk dimensions, mini dimensions… Your ETL process must load these dimensions. And there are dependencies. You can’t just truncate and reload a dimension because the surrogate keys in the fact tables will be invalidated.
But here comes a project that throws everything off. Don’t you love projects like these? I’m designing a data warehouse solution for small financial company, where I model financial loans. The wrinkle is that each loan has hundreds of attributes (the original source table actually has 4,500 fields!), including many dimension-like two-pair attributes, such as Loan Type and Loan Type Description. The number of loans is not big and can fit into an Excel spreadsheet. Where do you draw the line for dimensions here? You could identify “important” dimensions, such as these that require historical change tracking, such as Loan Status, Loan Type, etc. and leave the rest of the descriptors in the fact table. Or you could take the approach that I’m considering of leaving all attributes in the fact table, so that the Loan subject area consists of a LoanSnapshot accumulating snapshot table and Date dimension. Ta da – no dimensions besides Date!
What about conformed dimensions should other fact tables, such as LoanBudget, pop up later, like mushrooms on a rainy day? Well, then we can decouple the affected attributes and manufacture a dimension on the fly by simply adding a SQL view with SQL DISTINCT. And, yes, we will be relying on the business keys (no surrogate keys) for the joins. Unless there is a good reason to use surrogate keys, in which case we’d have to spin off more ETL.
Don’t get me wrong. Most projects will benefit from “properly” dimensionalizing the schema and often the dimension candidates, such as Product, Customer, Organization, Geography, are easy to spot. But sometimes, such as in the case of smaller and simpler businesses, this might be overkill and an ad-hoc and agile perspective might be preferable. It will save you tremendous effort and it’s not the end of the road should things get more complicated. Just don’t be a methodology stickler!
Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, August 1st, at 6:30 PM ET. We’ll have two presentations by 3Cloud. For more details and sign up, visit our group page.
Presentation:
1. “Power BI Meets Programmability – TOM, XMLA, and C#” by Kristyna Hughes
2. “Automation Using Tabular Editor Advanced Scripting” by Tim Keeler
Power BI Meets Programmability – TOM, XMLA, and C#
Tune in to learn how to programmatically add columns and measures to Power BI data models using TOM, XMLA, and C#! XMLA is a powerful tool available in the online Power BI service that allows report developers to connect to their data model and adjust a variety of entities outside the Power BI Desktop application. Combined with a .NET application, this can be a powerful tool in deploying changes to your Power BI data models programmatically.
Automation Using Tabular Editor Advanced Scripting
See examples of how advanced scripting in Tabular Editor can be used to automate the creation of DAX measures, calculation groups, and provide insights into your model while reducing development time and manual effort.
Speaker:
Kristyna Hughes’s experience includes implementing and managing enterprise-level Power BI instance, training teams on reporting best practices, and building templates for scalable analytics. Currently, Kristina is a data & analytics consultant at 3Cloud and enjoy answering qualitative questions with quantitative answers. Check out my blog at https://dataonwheels.wordpress.com/ and connect on LinkedIn https://www.linkedin.com/in/kristyna-hughes-dataonwheels/
Tim Keeler is a data analytics professional with over 17 years of experience developing cost-to-serve models, business intelligence solutions, and managing teams of other data professionals to help organizations achieve their strategic objectives. Check my blog at https://www.linkedin.com/in/tim-keeler-32631912/
Prototypes without Pizza
Power BI Latest
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2022-07-25 08:01:432022-07-25 08:01:43Atlanta MS BI and Power BI Group Meeting on August 1st (Power BI Automation)