Implementing “Generic” Percent of Grand Total in DAX
Suppose you need to calculate a percentage of grand total measure. Easy, you can use the Power BI “Show value as” without any DAX, right? Now suppose that you have 50 Table visuals and each of them require the same measure to be shown as a percentage of total. Although it requires far more clicks, “Show value as” is still not so bad for avoiding the DAX rabbit hole. But what about if you need this calculation in another measure, such as to implement a weighted average? Now, you can’t reference the Microsoft-generated field because it’s not implemented as a measure.
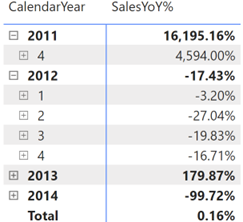
That’s exactly the scenario I faced while working on a financial report, although at the end I followed another approach to calculate the weighted average that didn’t require a percentage of total. Anyway, the question remains. Is there a way to implement a “generic” percent of grand total for a given measure that will work irrespective of what dimensions are used in a Table or Matrix visuals? Consider the following simple report.
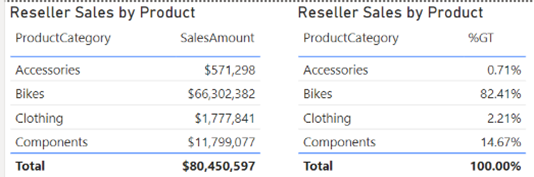
We want to show sales as a percentage of total irrespective of what dimension(s) are used in the report. Typically, to implement percentage of total measures you’d implement a DAX explicit measure that overwrites the filter context, such as:
% SalesAmount = VAR _TotalSales = CALCULATE(SUM(ResellerSales[SalesAmountBase]), ALL('Product')) RETURN DIVIDE (ResellerSales[SalesAmount], _TotalSales)
This measure uses the ALL function to remove the filter from the Product table to calculate the sales across any field in that table. But we want this measure to work even if fields from other tables are used as dimensions.
Enter the magical ALLSELECTED function. From the documentation, ALLSELECTED “removes context filters from columns and rows in the current query, while retaining all other context filters or explicit filters”, which is exactly what’s needed. That’s because we want to ignore the context from fields used in the visual but apply other filters, such as slicers and visual/page/report filters, and cross filtering from other visuals.
And so, the formula becomes:
% SalesAmount = VAR _TotalSales = CALCULATE(SUM(ResellerSales[SalesAmountBase]), ALLSELECTED()) RETURN DIVIDE (ResellerSales[SalesAmount], _TotalSales)
And that’s all to it except if you need a percentage of column total in a Matrix visual that has a field in the Columns bucket. In this case, ALLSELECTED will ignore not only the dimensions on rows but also dimensions on columns. Then, the net effect will be a generic measure that calculates the percent of grand total instead of column total.
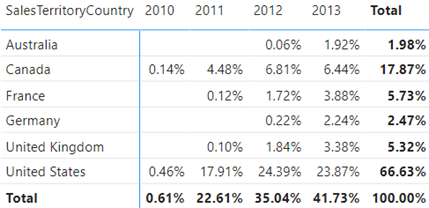
By the way, if you use the “Show value as” built-in feature and capture the query behind the visual, you’ll see that Microsoft follows a rather complicated way to calculate it to handle this scenario. Specifically, the visual generates two queries, where the first computes the visual totals and the second computes the percentage of total.