A few months ago, I did an assessment for a large company that was advised by an undisclosed source that they should use their Dynamics Financials and Operations (F&O) system as a data warehouse. Recently, I came across a similar wish to use SAP as a data warehouse. I understand that people want to do more with less and shortcuts are tempting. But ERP systems can’t fulfill this purpose, and neither can other systems of record. True, these systems might have analytical features, but these features typically deliver only operational reporting. Operational reporting has a narrow view concerned with “now”, such as a report that shows customers with outstanding balances as of today. By contrast, BI is mostly concerned with historical and trend analysis.
In math, axioms are statements that are assumed to be correct without a proof. We need BI axioms and the list can start like this:
Every mid to large company shall have a centralized data repository for consolidating trusted data that is optimized for reporting. The necessary for such a repository is in a direct proportion with the number of the data sources that must be integrated (that number will increase over time) and the complexity of the data transformation. The centralized data repository is commonly referred to as a data warehouse.
Dimensional modeling shall be the methodology to design the data warehouse schema. I know it’s tempting to declare your ODS as a data warehouse, but highly normalized schemas are not suitable for reporting.
If you’re after a single version of the truth, you shall have an organizational semantic layer.
ERP systems are not a replacement for a data warehouse. Neither are data lakes and Big Data.
You shall have both organizational and self-service BI, and they should complement each other. If you lean too much toward organization BI, you’ll get a backlog of requirements. If you lean too much toward self-service BI, you’ll end up with fragmented “spreadmarts”, which is where you probably started.
Most of the BI effort should go toward organizational BI to integrate data, improve data quality, and centralize business calculations. Tools come and go but this effort shall endure.
Agile and managed self-service BI shall fill in the gaps. It should provide a feedback loop to extend organizational BI with data that the entire organization can benefit from.
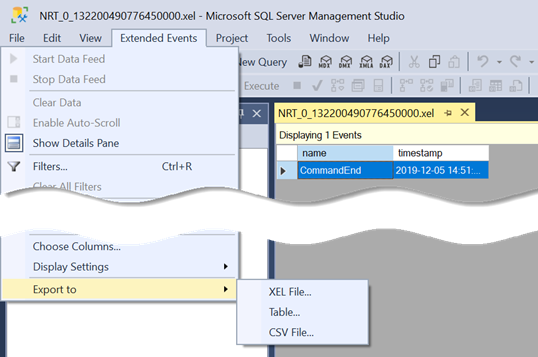
Load testing and troubleshooting Analysis Services often requires capturing a query trace. The lightweight option to do so is to create an Extended Events (xEvents) session. Let’s say you want to capture all query traffic for 24 hours. You might opt to use the SQL Server Profiler, but it’s implemented as a desktop app (there must be an active Windows session but what happens if the Profiler crashes or corporate policy logs you out?) and it may impact the performance of your production server. The recommend way is to set up an xEvents session that logs the required events (same events you see in SQL Server Profiler) to a *.xel file.
What’s not so obvious is how to analyze the file. The easiest way is to open the .xel file in SQL Server Management Studio (SSMS). You’ll see a new Extended Events menu added to the menu bar. Among other things, this menu allows you to export the trace to a SQL Server table!
What makes an xEvents session even more useful is that it allows you to correlate events. For example, for some obscure reason the Analysis Services PropertiesList info is only available in the QueryBegin event. However, capturing the QueryEnd event is good enough because it gives you all the info you need, such as the query duration, query statement, database name, etc. But what if queries come from a Power BI report via a gateway to an on-prem SSAS instance? In this case, the user identity is in the PropertiesList info because the gateway uses a trusted account to connect to SSAS. So, now you must capture QueryBegin if you want to know who sent the query. Fortunately, you can use the RequestID GUID column in the trace to correlate QueryBegin with QueryEnd to look up the username from the QueryBegin row and to add it to the QueryEnd event.
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on November 4, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Stacey Jones will present Power BI options with Python. Accelebrate will sponsor the meeting. And I will share some tips demoing the latest Power BI Desktop features, such as the new ribbon, decomposition tree and AI integration. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Integrating Power BI with Python
Date:
December 2nd, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta) 8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009
Overview:
Python is well suited for Data Science and big data professionals. It has been voted as the most popular programming language in 2019. Microsoft made big investments in open-source R and Python, especially to extend Power BI. Join this session to learn how you can integrate Python with Power BI. Learn how to use Python in these ways:
· Use Python as a data source
· Transform data
· Produce beautiful visualizations
Speaker:
Stacey Jones specializes in mentoring and guiding firms in their efforts to build a modern Data, AI & BI governance programs that empower their business with Self-Service BI and Data Science capabilities. He currently serves as the Principal Data Solutions Architect at the Atlanta Microsoft Technology Center (MTC).
Sponsor:
Don’t settle for “one size fits all” training. Choose Accelebrate, and receive hands-on, engaging training precisely tailored to your goals and audience! Our on-site training offerings range from ASP.NET training and SharePoint training to courses on ColdFusion, Java™, C#, VB.NET, SQL Server, and more. Accelebrate.com
Prototypes with Pizza
“New ribbon, decomposition tree, and AI integration in Power BI Desktop” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-11-28 08:49:492021-02-17 01:02:02Atlanta MS BI and Power BI Group Meeting on December 2nd
At Ignite 2019 Microsoft announced the public preview of large datasets in Power BI Premium. This is a significant milestone as now datasets can grow up to the capacity’s maximum memory (previously, the max size was 10 GB with P3 plan), thus opening the possibility of deploying organizational semantic models to Power BI. I consider this feature mostly suitable for organizational BI as I don’t imagine business users dealing with such large data volumes. I tested large datasets during its private preview, and I’d like to share some notes.
The Good
Today, BI developers can deploy organizational semantic models to three Analysis Services Tabular SKUs: SQL Server Analysis Services, Azure Analysis Services, and now Power BI Premium. SQL Server Analysis Services is the Microsoft on-prem offering and it aligns with the SQL Server release schedule. Traditionally, Azure Analysis Services has been the choice for cloud (PaaS) deployments. However, caught in the middle between SQL Server and Power BI, the AAS future is now uncertain given that Microsoft wants to make Power BI as your one-stop destination for all your BI needs. From a strategic perspective, it makes sense to consider Power BI Premium for deploying organizational semantic models because of the following main benefits:
Always on the latest – Both AAS and SQL Server lag in features compared to Power BI Premium. For example, composite models and aggregations are not in SQL Server 2019 and Azure Analysis Services. By deploying to Power BI, which is also powered by Analysis Services Tabular, your models will always be on the latest and greatest.
Feature parity – As I explain in my “Power BI Feature Discrepancies for Data Acquisition” blog, some Power BI features, such as Quick Insights, Explain Increase/Decrease, Power Query, are not supported with live connections to Analysis Services. By hosting your models in Power BI Premiums, these features are now supported because Power BI owns the data, just like you import data in Power BI Desktop and then publish the model.
The Bad
As a Power BI Premium feature, large datasets will require planning and purchasing a premium capacity. Given that you need at least twice the memory to fully process a model (less memory should be required if you process incrementally), you must size accordingly. For example, a 15 GB model would require at least 30 GB of memory to fully process, bringing you into the P2 plan territory. Memory is the most important constraint for Tabular. Unlike SQL Server, which doesn’t license by memory (you can add as much memory you like without paying a dime more in licensing fees), Power BI Power BI Premium plans cap the capacity memory. So, you’ll end up having a dedicated P1 or P2 plan for hosting your organizational semantic model, and another P plan(s) for self-service BI.
I’d like to see elastic scaling happening to Power BI Premium at some point in future. Instead of boxing me into a specific plan, which more than likely will be underutilized, I’d like to see Power BI Premium scaling up and down on demand. This should help lowering the cost.
The Ugly
The lack of DevOps in Power BI Premium will put another hole into your budget. Unlike SQL Server, where you pay only for production use, no special DEV or QA environments and licensing options exist in Power BI Premium. So, you must plan for additional premium capacities, such as for three separate capacities: PROD, DEV, and QA (I know of organizations that need many more DevOps environments). At this price point, even large organizations will reconsider the licensing cost of hosting their models in Power BI. How about leaving QA and DEV on prem? This would require coding for the least common denominator which defeats the benefit of deploying to Power BI Premium. You can get innovative and attempt to reduce licensing cost by purchasing Azure A plans for DEV and QA and stopping the A capacities when they are not in use, but I wonder how many organizations will be willing to go through the pain of doing this. The Cloud should make things easier, right?
Large datasets will open another deployment option for hosting organizational semantic models. This might be an attractive option for some organizations and ISVs. Others will find that staying on-prem could lower their licensing cost. Once the Power BI Premium XMLA endpoint supports write operations (promised for December 2019 in the roadmap), BI developers can use a tool of their choice, such as Tabular Editor or Visual Studio (I personally find Power BI Desktop not suitable for organizational model development, mainly because of its slow performance, lack of source control and extensibility) to develop and deploy semantic models that are always on the latest features and unifying BI on a single platform: Power BI.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-11-10 10:24:122019-11-10 10:24:12Power BI Large Datasets: The Good, the Bad, and the Ugly
Now that SQL Server 2019 is officially here, I was eager to try it out. My upgrade/reinstall experience ran into several issues that I thought might be worth sharing:
Upgrade/reinstall fails with “An error occurred for a dependency of the feature causing the setup process for the feature to fail.” With no indication what dependency failed. I solved it by extracting the iso file into a folder instead of mounting it.
Analysis Services Tabular fails to start with “An error occurred when loading the ‘ASSP’, from the file, ‘\\?\D:\MSSQLSERVER\SSAS\Data\ASSP.0.asm.xml’.” This error was caused by changing the Analysis Services Tabular default folders to another drive. It could be related to my setup, such as permissions granted to that drive. I fixed it by leaving the SQL Server and Analysis Services default folders.
The Polybase services can’t start and show perpetually “Starting” in the Windows Services applet. Consequently, the SQL Server Database Engine can’t be stopped. This was solved by enabling the TCP/IP protocol in the SQL Server Configuration Manager.
Still an open issue although not a blocker – Any right-click action in SSMS connected to Analysis Services Tabular results in a significant delay.
My wife bought a pack of replacement water filters from Amazon. It was tagged as “Amazon’s choice”. The product listing showed the manufacturer name and it had a nice product photo advertising genuine filters. Except that there were all fake, which we discovered quickly by the output water pressure. The water coming out of a filter should have lower pressure while there was no difference with the “genuine” filter as though there was no filtering going on at all. And the water had a bad aftertaste. So, we call the manufacturer. They compared the batch number from the package (manufactured in China) and found it fake. That filter could have had some Chinese poison in it and Amazon would have sold it under “Amazon’s choice”. BTW, when we reported this to Amazon, the product was listed under a different seller.
There is a lot of noise (mostly vendor-induced propaganda as previously with Big Data) around AI, ML, and other catchy flavors of predictive analytics. I have a lot of respect for Amazon and I’m sure they know a lot about ML. Yet, fake products sneak in undetected and bad people find ways to cheat the system. In fact, I don’t think that advanced analytics is needed to solve this problem. All Amazon has to do is let big name manufactures register their approved resellers on the Amazon website. If the seller is not on the list, Amazon could flash a big juicy warning for the buyer. This would be a win-win for Amazon by improving their credibility as a retailer, manufacturers, and buyers. BTW, many manufacturers don’t sell on Amazon because of the exact same reason: counterfeited products that harm the brand.
But Amazon, whose platform’s main goal appears to be making as much money as possible by “democratizing” the retail industry, doesn’t do this. I might not know much about business, but I know that trust is paramount. When corporate greed takes over and their platform tags fake products as “Amazon’s choice”, where is that trust? BTW, I was told by the Amazon’s rep is that I could have a better confidence that a product is genuine if it says that it’s “sold and distributed by Amazon”. Which makes me skeptical because it means that their warehouses must be divided in two areas: one for sold and distributed by Amazon that stores genuine products supposedly procured by Amazon and another for sold by someone else but distributed by Amazon. Somehow, I doubt they do this.
So, Amazon, apply ML to predict the probability of buying a genuine product and show me the confidence score. Perhaps, I’ll buy more…
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on November 4, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Andy Lawrence will share best practices for impactful Power BI Dashboards. CCG Analytics will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Best Practices for Impactful Power BI Dashboards
Date:
November 4, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta) 8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009
Overview:
Power BI is gaining momentum as a preferred tool for dashboards and interactive reports. Let’s revisit some best practices for dashboard development, such as:
· The importance of form and function
· Facilitating user adoption
· Mistakes that everyone makes
· Fast shortcuts for clean reports
· Hidden settings that are lifesavers
· Best Power BI updates of 2019
· Live demo of a fast dashboard build
· Questions
Speaker:
Andy Lawrence is a senior Power BI consultant at CCG Analytics and the leader of the Tampa Power BI user group. He’s a Florida native and a proud UF Gator (MBA) and USF Bull (MIS). At CCG he provides guidance on data modeling, tabular environments, azure administration, DAX writing, T-SQL and data visualization best practices. All of which he can expand upon if you have questions during his presentation.
Sponsor:
CCG specializes in deploying solutions that not only provide value to the business but are adopted by users ensuring accountability of the IT driven system. Moving beyond reporting, our Business Intelligence solutions support data governance, quality and standardization across the organization and enable stakeholders with tools like predictive analytics, user-defined alerts, data mining, what-if analysis and visually appealing dashboards.
Prototypes with Pizza
“Lineage view” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-10-31 08:11:272021-02-17 01:02:02Atlanta MS BI and Power BI Group Meeting on November 4th
Every now and then I get a question about how to secure Power BI report pages. A business analyst has created a multi-page report that requires limited access to some sensitive information in one or more report pages. I always cringe at this idea and recommend securing the data instead. That’s because report-level or dashboard-level security can be easily compromised. For example, if the user has permissions to use Analyze in Excel, they will surely bypass report security and get access to all the data. The same will happen if they use Report Builder or connect a third-party tool to the published Power BI dataset. Instead, you should apply row-level security (RLS) to protect the data. Currently, Power BI doesn’t let you secure report pages but if you must apply report or visual security, you have options:
Break the report into two set of reports: one with open access and another with “secure” pages. Share the report with the secure pages with the people who can access it or publish it to a separate workspace.
Add a hidden page-level or report-level slicer that filters on a DAX measure. The DAX measure can check the user identity using the USERPRINCIPALNAME() function, so the slicer doesn’t return any values if the interactive user is not authorized. Granted, a better (and preferred) way to achieve this could be to apply RLS but RLS will restrict data to all visuals where as a slicer can filter only selected visuals.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-10-27 17:54:212019-10-29 17:05:25Securing Power BI Report Pages
Power BI lets you filter the visual data by a measure, such as by a measure that dynamically calculates the customer’s rank. This is convenient but there are performance implications related to the way Power BI autogenerates the DAX query. If a visual has a visual-level filter on a measure, Power BI Desktop defines a variable table filter that includes all measures in the visual. In the following example, the visual filters on the IncludedInRank measure, but the filter table includes all measures in the visual:
As a result, these measures are evaluated twice: once in the filter table and twice in the main query (EVALUATE clause). This could definitely impact performance if the measures are slow to begin with. While waiting on Microsoft to provide more control over the autogenerated query, one approach to mitigate the performance impact is to use the Power BI-provided TOPN filter. In this example, instead of sorting and filtering on IncludedInRank to find the top N customers, you would apply a TOPN filter on Customer[Parent Name] based on the IncludedInRank measure. When TOPN is used, the autogenerated filter table will filter only on the measure used for TOPN, thus avoiding evaluating the rest of the measures.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-10-21 14:14:062019-10-21 14:14:06Filtering Power BI Visuals by Measure