New “Applied DAX with Power BI” Workshop
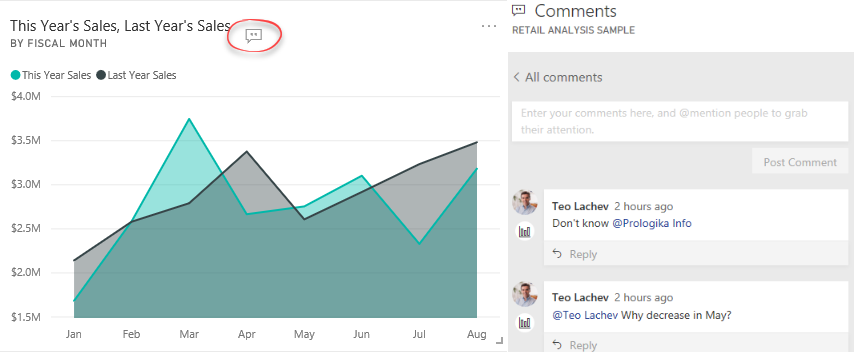
Data Analysis Expressions (DAX) is the expression language of Power BI, Power Pivot, and Analysis Services Tabular. It’s very powerful but it’s perceived as complex, requiring a steep learning curve. I’m excited to announce a new 2-day “Applied DAX with Power BI” workshop that I designed to help you become proficient with DAX. You’ll learn practical skills that will help you tackle a wide range of reporting requirements. We’ll start with DAX fundamentals, such as calculated columns and measures, and then progress to more advanced concepts, including such as context transitions, variables, filters, time intelligence, advanced relationships, row-level security, query optimization, and much more. Think of this workshop as Advanced Power BI and the next level from my “Applied Power BI” class. The target audience is data analysts and BI developers wanting to hone their DAX skills with Power BI, Power Pivot, or Tabular.
Here is my entire training catalog with a brief description and link to each course page.
| COURSE | DESCRIPTION | DURATION |
| Applied Power BI | This two-day workshop is designed to help you become proficient with Power BI and acquire the necessary skills to work with online and on-premises data, implement data models on a par with professional models created by BI pros, unlock the power of data by creating interactive reports and dashboards, and share insights with other users. No prior data modeling or reporting knowledge is assumed. Students are welcome to bring their own data to the second day of the class. | 2 |
| Applied DAX with Power BI NEW! | Data Analysis Expressions (DAX) is the expression language of Power BI, Power Pivot, and Analysis Services Tabular. It’s very powerful but it’s usually perceived as complex requiring a steep learning curve. This two-day class is designed to help you become proficient with implementing business calculations with Data Analysis Services (DAX). | 2 |
| Applied BI Semantic Model | Targeting BI developers, this intensive 5-day onsite class is designed to help you become proficient with Analysis Services and acquire the necessary skills to implement Tabular and Multidimensional semantic models. Use the opportunity to ask questions and study best practices that will help you achieve a single version of the truth by implementing scalable and secure organizational models. Bring your organizational BI to the next level by learning these two powerful BI technologies in one class! | 5 |
| Applied SQL Fundamentals | SQL Server is the most deployed and popular database today. Different types of users need to query data stored in SQL Server data structures. This 2-day instructor led course provides you with the necessary skills to query Microsoft SQL Server databases with Transact-SQL. This course starts with the basics of a SELECT statement and its syntax, and progresses to teach you how to join, aggregate, and convert data. | 2 |
| Applied Microsoft BI (End to End) | This four-day class is designed to help you become proficient with the Microsoft BI toolset and acquire the necessary skills to implement an organizational BI solution. You’ll learn how to design a star schema, use SQL Server Integration Services to transform data, and implement a Tabular semantic model. Depending on the students’ skillset, it can be customized, such as to reduce coverage of specific technologies, replace them with other topics of interest, such as Multidimensional instead of Tabular, or cover additional topics, such as Power BI or Reporting Services. | 4 |
| Applied Reporting Services | Microsoft SQL Server Reporting Services has evolved into a sophisticated reporting platform that lets you present and analyze data consistently, quickly, and reliably. This intensive 3-day class is designed to help you become proficient with Reporting Services and acquire the necessary skills to author, manage, and deliver reports. | 3 |
| Applied Analysis Services-Multidimensional | This intensive four-day class is designed to help you become proficient with Analysis Services (Multidimensional) and acquire the necessary skills to implement OLAP and data mining solutions. Learn how to build a cube from scratch. Use the opportunity to ask questions and study best practices! | 4 |
| Applied Excel and Analysis Services | If your organization have Analysis Services Multidimensional cubes or Tabular models and you want to gain valuable insights from them in Excel, then this course is for you. Designed as a step-by-step tour, this course teaches business users how to become data analysts and unlock the hidden power of data. You’ll learn how to apply the Excel desktop BI capabilities to create versatile reports and dashboards for historical and trend analysis. | 2 |
| Applied Power BI with Excel | Power BI is a suite of products for personal business intelligence (BI). It brings the power of Microsoft’s Business Intelligence platform to business users. At the same time, Power BI lets IT monitor and manage published models to track their usage, security, and estimate hardware and software resources. With Power BI, anyone can easily build personal BI models using the most popular tool – Excel and share them on premises or the cloud. | 2 |
| Applied Microsoft Visualization Tools | This two-day class is designed to help you learn the visualization tools that are included in the Microsoft Data Analytics Platform. We’ll start by exploring the Excel reporting capabilities that include pivot (PivotTable and PivotChart) and Power View reports. Then, you’ll learn how to explore data interactively with Power BI Desktop. During the second day of the class, we’ll focus on learning how to create paginated reports with Reporting Services. The class can be customized to discuss other tools, such as SSRS mobile reports or Power Map reports. | 2 |
| Applied Master Data Management | This two-day class is designed to help you become proficient with Master Data Services (MDS) and Data Quality Services (DQS). IT and business users learn how to design MDS models and extend them with business rules, attribute groups, and hierarchies. IT will learn how to integrate MDS with upstream and downstream systems and how to enforce secured access. Business users will learn how to use Excel to manage data with the tool they love most! | 2 |