Tips for Configuring Azure Data Factory Alerts
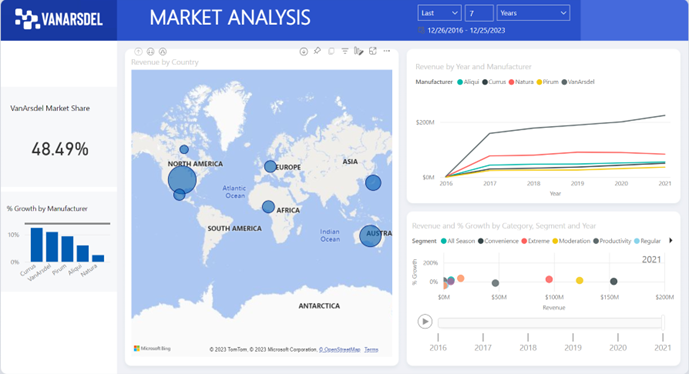
Alerting is an important monitoring task for any ETL process. Azure Data Factory can integrate with a generic Azure event framework (Azure Monitor) which makes it somewhat unintuitive for ETL monitoring. You can set up and change the alerts using the ADF Monitoring hub.
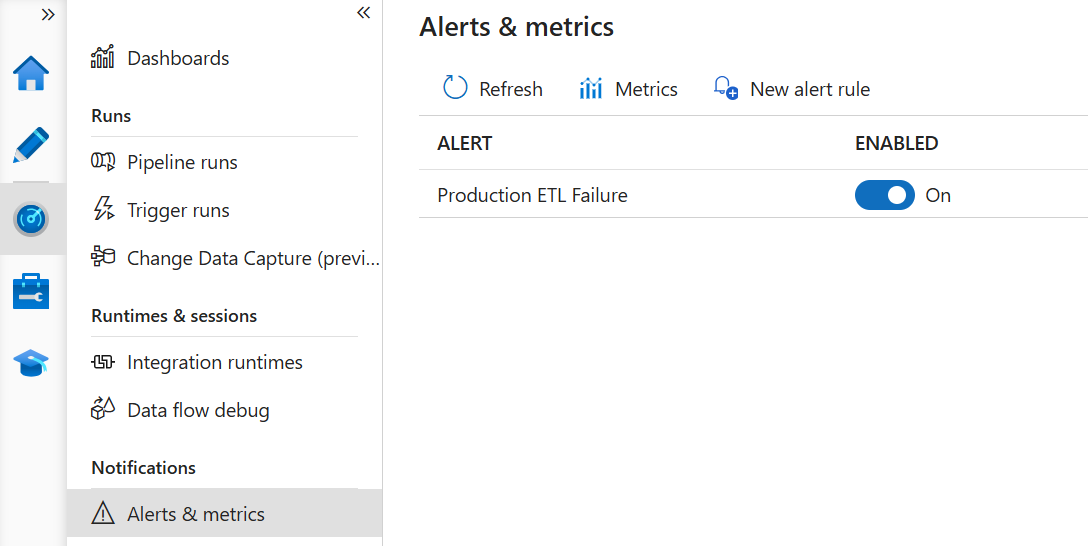
You might find the following tips useful for setting up an ADF alert:
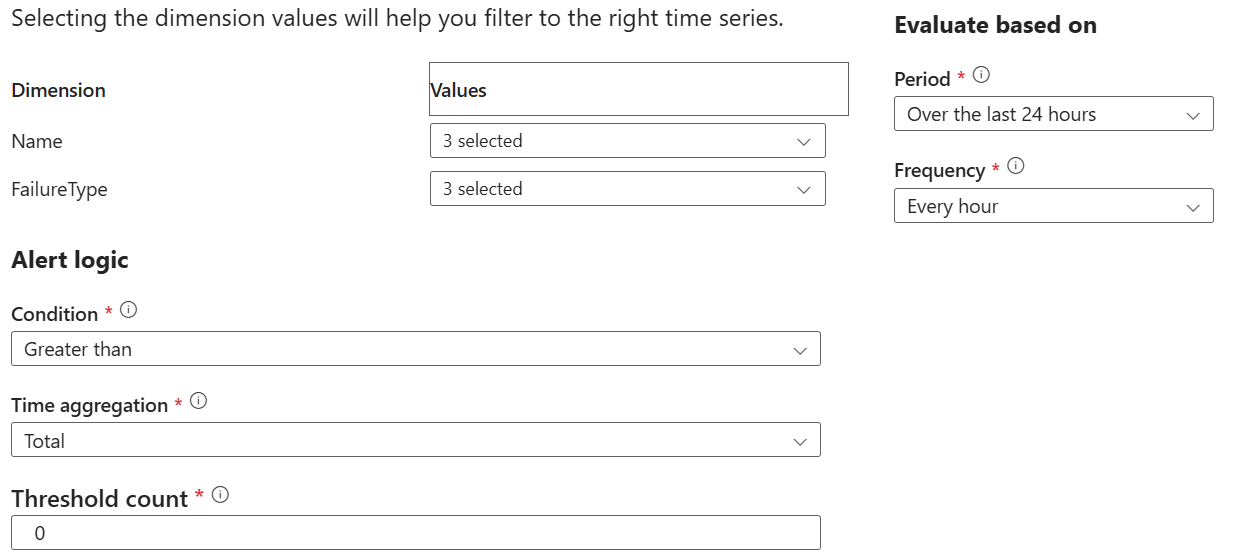
- Dimension – I like to nest pipelines where a master pipeline starts dimension and fact master pipelines, which in turn execute unit pipelines, such as a loading a dimension table. This allows me to restart ETL at any level. In the Dimension dropdown (nothing to do with DW dimensions), I select all such master pipelines because if an error is triggered downstream, it will bubble up to the master.
- Failure Type – I select all failure types.
- Condition – I configure the alert to be generated as soon as one failure occurs.
- Period – This is a tricky one. It specifies over what period the threshold failure count will be evaluated. Let’s say you schedule the ETL process nightly at 12 AM. If you specify a value lower than 24 hours, let’s say 6 hours, Azure Monitor will check for failures every 6 hours. If ETL fails at say 12:15 AM, you will get the alert the next time Azure Monitor runs as you should. But then, after it checks in another 6 hours and finds no failure, it will send a notification that the failure is resolved, while probably it’s not. Therefore, I set the period to 24 hours. Obviously, this will be an issue if ETL runs weekly but 24 hours is the longest period supported.
- Frequency – I set this to the longest frequency of 1 hour as it doesn’t make sense to check frequently for failures if the process runs once in a day. With this setup, the threshold count will be evaluated every hour for each 24-hour cycle.