If Microsoft Fabric was the Statue of Liberty, the inscription would be “Give me your data”. Fabric is obsessed with owning the data when it makes sense and when it doesn’t. As I wrote before, this pattern was probably borrowed from Palantir and to align Fabric with the push for “modern” medallion architectures. Or, to establish a permanent dependency on Fabric…
In this newsletter, I make a case that Fabric should support better data virtualization that goes beyond creating shortcuts to files.
Auto-replicating data to Fabric
To satisfy the Fabric data appetite and facilitate data ingestion into OneLake, Fabric offers two primary options that don’t require explicit ETL: mirroring and shortcut transformations.
Mirroring targets a growing number of relational and non-relational database engines. Although described as “easy-to-use”, mirroring could prove challenging to set up in real life. For example, in one case, the client simply refused to set up mirroring from Google BigQuery because of the requirement to grant excessive permissions. In another case, we are still trying to figure out why mirroring doesn’t work from Azure SQL MI configured on private network. Not to mention that mirroring even from Microsoft SQL SKUs has limitations, such as historical temporal tables can’t be mirrored.
This leaves with the second option: shortcut transformations. They target a subset of file formats (not databases). Like mirroring, Fabric polls periodically the shortcut target folder and synchronizes the data in OneLake Delta tables. These transformations could be useful to provide convenient access to this data from Fabric workloads, such as to access reference data a business user maintains in an Excel spreadsheet in a Fabric Data Warehouse. On the downside, data must be exported and saved as files.
OneLake Shortcuts
Yet, many scenarios could be addressed by simply accessing the data where it is. In other words, by data virtualization. As it stands, Fabric has limited file-based data virtualization capabilities with OneLake shortcuts. OneLake shortcuts shouldn’t be confused with the shortcut transformations mentioned before. OneLake shortcuts are read-only pointers to external files. These shortcuts are typically listed in the unmanaged section of OneLake (the Files folder). OneLake shortcuts don’t import the data in Delta tables. How are they useful then? The main thought is to conveniently share data between teams, workspaces, or domains, workloads, without moving it.
As an exception to the rule, if the OneLake shortcut points to a Delta table, such as OneLake or elsewhere, or Iceberg table, the shortcut still doesn’t copy the data but exposes it as OneLake Delta table. This lets you utilize Delta-specific features, such as a DirectLake semantic model without moving the data. I find this inspiring to imagine a simplified data integration in a world where one day other vendors could embrace standard file formats.
What about databases?
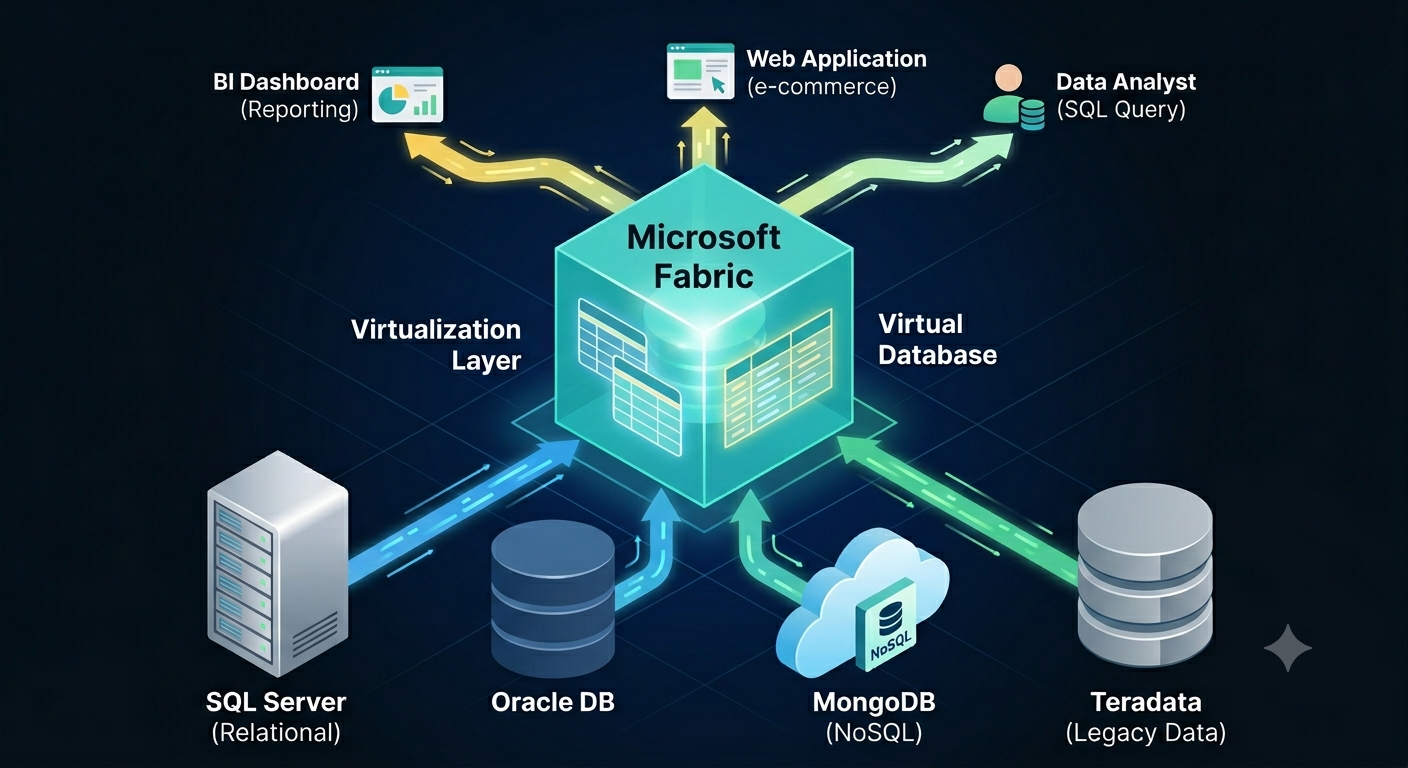
Based on experience, a typical company has 90+ percent of its data in relational databases or connectable non-file sources, such as REST APIs and SFTP servers. In my opinion, mirroring these (sometimes huge) datasets into a file-based, pseudo-relational lakehouse rarely makes sense. Wouldn’t be nice to have shortcuts to tables in these sources and then shape and get the data you need instead of writing ETL? And even better, run cross-database queries? Wouldn’t this be a great Fabric differentiator compared to other vendors?
Since time immemorial, SQL Server has been supporting linked servers and heterogenous joins across databases. Then PolyBase was supposed to replace linked servers and be the Microsoft answer to broader data virtualization. Alas, both technologies didn’t make it to Fabric. Linked servers are available only in on-prem SQL Server and with limited support in Azure SQL MI. Polybase was relegated to the on-prem SQL Server.
I think it’s time Fabric to fulfil its zero-copy promise and say “Let me connect the dots, don’t move that data”.
At Ignite in November, 2025, Microsoft introducedFabric IQ. I noted to go beyond the marketing hype and check if Fabric IQ makes any sense. The next thing I know, around the holidays I’m talking to an enterprise strategy manager from an airline company and McKinsey consultant about ontologies. In this newsletter I share my thoughts of FabricIQ based on my initial evaluation. Let’s start with what ontology is and how Fabric IQ uses it to integrate your enterprise data.
Ontology – A branch of philosophy, ontology is the study of being that investigates the nature of existence, the features all entities have in common, and how they are divided into basic categories of being. In computer science and AI, ontology refers to a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
What is Fabric IQ?
According to Microsoft, Fabric IQ is “a unified intelligence platform developed by Microsoft that enhances data management and decision-making through semantic understanding and AI capabilities.” Clear enough? If not, if you view Fabric as Microsoft’s answer to Palantir’s Foundry, then Fabric IQ is the Microsoft equivalent of Palantir’s Foundry Ontology, whose success apparently inspired Microsoft.
Therefore, my unassuming layman definition of Fabric IQ is a metadata layer on top of data in Fabric that defines entities and their relationships so that AI can make sense of and relate the underlying data.
For example, you may have an organizational semantic model built on top of an enterprise data warehouse (EDW) that spans several subject areas. And then you might have some data that isn’t in EDW and therefore outside the semantic model, such as HR file extracts in a lakehouse. You can use Fabric IQ as a glue that bridges that data together. And so, when the user asks the agent “correlate revenue by employee with hours they worked”, the agent knows where to go for answers. This screenshot shows how you can define such relationships between two entities.
Following this line of thinking, Microsoft BI practitioners may view Fabric IQ as a Power BI composite semantic model on steroids. The big difference is that a composite model can only reference other semantic models while Fabric IQ can span data in multiple formats.
The Good
Palantir had a head start of a decade or so compared to Microsoft Fabric, but yet even in its preview stage, I like a thing or two about Fabric IQ from what I’ve seen so far:
Its oncology can span Power BI semantic models (with caveats explained in the next section), powered by best-in-class technology. As I mentioned before, this allows you to bridge all the business logic and calculations you carefully crafted in a semantic model to the rest of your Fabric data estate.
Fabric IQ integrates with other Microsoft technologies, such as real-time intelligence (eventhouses), Copilot Studio, Graph. This tight integration turns Fabric into a true “intelligence platform,” reducing duplicated logic, one-off models, and maintenance while enabling multi-hop reasoning and real-time operational agents.
Democratized and no-code friendly – Visual tools allow business users to build and evolve the ontology, lowering barriers compared to more engineering-heavy alternatives. Making it easy to use has always been a Microsoft strength.
Groundbreaking semantics for AI Agents: Fabric IQ elevates AI from pattern-matching to true business understanding, allowing agents to reason over cascading effects, constraints, and objectives—leading to more reliable, auditable decisions and automation.
Compared to Palantir, I also like that Fabric OneLake has standardized on an open Delta Parquet format and embraced data movements tools Microsoft BI pros and business users are already familiar with, such as Dataflows and pipelines, to bring data in Fabric and therefore Fabric IQ.
The Bad
I hope some of these limitations will be lifted after the preview but:
Only DirectLake semantic models are accessible to AI agents. Import and DirectQuery models are not currently supported for entity and relationships binding. Not only does this limitation rule out pretty much 99.9% of the existing semantic models, but it also prevents useful business scenarios, such as accessing the data where it is with DirectQuery instead of duplicating the data in OneLake.
No automatic ontology building – It requires cross-functional agreement on business definitions, workshops, and governance—labor-intensive for organizations without mature semantic models. I hope Microsoft will simplify this process like how Purview has automated scans.
Risk of overhype vs. delivery gap – We’ve seen this before when new products got unveiled with a lot of fanfare, only to be abandoned later.
The Ugly
OneLake-centric dependency. Except for shortcuts to Delta Parquet files which can be kept external, your data must be in OneLake. What about these enterprises with investments in Google BigQuery, Teradata, Snowflake, and even SQL Server or Azure SQL DB? Gotta bring that data over to OneLake. Even shortcut transformations to CSV, Parquet, JSON files in OneLake, S3, Google Cloud Storage, will copy the data to OneLake. By contrast, Palantir has limited support for virtual tables to some popular file formats, such as Parquet, Iceberg, Delta, etc.
What happened to all the investments in data virtualization and logical warehouses that Microsoft has made over years, such as PolyBase and the deprecated Polaris in Synapse Serverless? What’s this fascination with copying data and having all the data in OneLake? Why can’t we build Fabric IQ on top of true data virtualization?
Which is where I was thinking that semantic models with DirectQuery can be used as a workaround to avoid copying data over from supported data sources, but alas Fabric IQ doesn’t like them yet.
Summary
Microsoft Fabric IQ is a metadata layer on top of Fabric data to build ontologies and expose relevant data to AI reasoning. It will be undoubtedly appealing to enterprise customers with complex data estates and existing investments in Power BI and Fabric. However, as it stands, Fabric IQ is OneLake-centric. Expect Microsoft to invest heavily in Fabric and Fabric IQ to compete better with Palantir.
Telegraph sang a song about the world outside
Telegraph road got so deep and so wide
Like a rolling river…
The Telegraph Road, Dire Straits
At Ignite in November, 2025, Microsoft introducedFabric IQ. I noted to go beyond the marketing hype and check if Fabric IQ makes any sense. The next thing I know, around the holidays I’m talking to an enterprise strategy manager from an airline company and McKinsey consultant about ontologies.
Ontology – A branch of philosophy, ontology is the study of being that investigates the nature of existence, the features all entities have in common, and how they are divided into basic categories of being. In computer science and AI, ontology refers to a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
So, what better way to spend the holidays than to play with new shaky software?
What is Fabric IQ?
According to Microsoft, Fabric IQ is “a unified intelligence platform developed by Microsoft that enhances data management and decision-making through semantic understanding and AI capabilities.” Clear enough? If not, if you view Fabric as Microsoft’s answer to Palantir’s Foundry, then Fabric IQ is the Microsoft equivalent of Palantir’s Foundry Ontology, whose success apparently inspired Microsoft.
Therefore, my unassuming layman definition of Fabric IQ is a metadata layer on top of data in Fabric that defines entities and their relationships so that AI can make sense of and relate the underlying data.
For example, you may have an organizational semantic model built on top of an enterprise data warehouse (EDW) that spans several subject areas. And then you might have some data that isn’t in EDW and therefore outside the semantic model, such as HR file extracts in a lakehouse. You can use Fabric IQ as a glue that bridges that data together. And so, when the user asks the agent “correlate revenue by employee with hours they worked”, the agent knows where to go for answers.
Following this line of thinking, Microsoft BI practitioners may view Fabric IQ as a Power BI composite semantic model on steroids. The big difference is that a composite model can only reference other semantic models while Fabric IQ can span data in multiple formats.
The Good
Palantir had a head start of a decade or so compared to Microsoft Fabric, but yet even in its preview stage, I like a thing or two about Fabric IQ from what I’ve seen so far:
Its oncology can span Power BI semantic models (with caveats explained in the next section), powered by best-in-class technology. As I mentioned before, this allows you to bridge all the business logic and calculations you carefully crafted in a semantic model to the rest of your Fabric data estate.
Fabric IQ integrates with other Microsoft technologies, such as real-time intelligence (eventhouses), Copilot Studio, Graph. This tight integration turns Fabric into a true “intelligence platform,” reducing duplicated logic, one-off models, and maintenance while enabling multi-hop reasoning and real-time operational agents.
Democratized and no-code friendly – Visual tools allow business users to build and evolve the ontology, lowering barriers compared to more engineering-heavy alternatives. Making it easy to use has always been a Microsoft strength.
Groundbreaking semantics for AI Agents: Fabric IQ elevates AI from pattern-matching to true business understanding, allowing agents to reason over cascading effects, constraints, and objectives—leading to more reliable, auditable decisions and automation.
Compared to Palantir, I also like that Fabric OneLake has standardized on an open Delta Parquet format and embraced data movements tools Microsoft BI pros and business users are already familiar with, such as Dataflows and pipelines, to bring data in Fabric and therefore Fabric IQ.
The Bad
I hope some of these limitations will be lifted after the preview but:
Only DirectLake semantic models are accessible to AI agents. Import and DirectQuery models are not currently supported for entity and relationships binding. Not only does this limitation rule out pretty much 99.9% of the existing semantic models, but it also prevents useful business scenarios, such as accessing the data where it is with DirectQuery instead of duplicating the data in OneLake.
No automatic ontology building – It requires cross-functional agreement on business definitions, workshops, and governance—labor-intensive for organizations without mature semantic models. I hope Microsoft will simplify this process like how Purview has automated scans.
Risk of overhype vs. delivery gap – We’ve seen this before when new products got unveiled with a lot of fanfare, only to be abandoned later.
The Ugly
OneLake-centric dependency. Except for shortcuts to Delta Parquet files which can be kept external, your data must be in OneLake. What about these enterprises with investments in Google BigQuery, Teradata, Snowflake, and even SQL Server or Azure SQL DB? Gotta bring that data over to OneLake. Even shortcut transformations to CSV, Parquet, JSON files in OneLake, S3, Google Cloud Storage, will copy the data to OneLake. By contrast, Palantir has limited support for virtual tables to some popular file formats, such as Parquet, Iceberg, Delta, etc.
What happened to all the investments in data virtualization and logical warehouses that Microsoft has made over years, such as PolyBase and the deprecated Polaris in Synapse Serverless? What’s this fascination with copying data and having all the data in OneLake? Why can’t we build Fabric IQ on top of true data virtualization?
Which is where I was thinking that semantic models with DirectQuery can be used as a workaround to avoid copying data over from supported data sources, but alas Fabric IQ doesn’t like them yet.
Summary
Microsoft Fabric IQ is a metadata layer on top of Fabric data to build ontologies and expose relevant data to AI reasoning. It will be undoubtedly appealing to enterprise customers with complex data estates and existing investments in Power BI and Fabric. However, as it stands, Fabric IQ is OneLake-centric. Expect Microsoft to invest heavily in Fabric and Fabric IQ to compete better with Palantir.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2025-12-27 16:09:382026-01-08 16:36:39First Look at Fabric IQ: The Good, The Bad, and The Ugly
If Microsoft Fabric is in your future, you need to come up with a strategy to get your data in Fabric OneLake. That’s because the holy grail of Fabric is the Delta Parquet file format. The good news is that all Fabric data ingestion options (Dataflows Gen 2, pipelines, Copy Job and notebooks) support this format and the Microsoft V-Order extension that’s important for Direct Lake performance. Fabric also supports mirroring data from a growing list of data sources. This could be useful if your data is outside Fabric, such as EDW hosted in Google BigQuery, which is the scenario discussed in this newsletter.
Avoiding mirroring issues
A recent engagement required replicating some DW tables from Google BigQuery to a Fabric Lakehouse. We considered the Fabric mirroring feature for Google BigQuery (back then in private preview, now in public preview) and learned some lessons along the way:
1. 400 Error during replication configuration – Caused by attempting to use a read-only GBQ dataset that is linked to another GBQ dataset, but the link was broken.
2. Internal System Error – Again caused by GBQ linked datasets which are read-only. Fabric mirroring requires GBQ change history to be enabled on tables so that it can track changes and only mirror incremental changes after first initial load.
3. (Showstopper for this project) The two permissions that raised security red flags are bigquery.datasets.create and bigquery.jobs.create. To grant those permissions, you must assign one of these BigQuery roles:
• BigQuery Admin
• BigQuery Data Editor
• BigQuery Data Owner
• BigQuery Studio Admin
• BigQuery User
All these roles grant other permissions, and the client was cautious about data security. At the end, we end up using a nightly Fabric Copy Job to replicate the data.
Fabric Copy Job Pros and Cons
The client was overall pleased with the Fabric Copy Job.
Pros
250 million rows replicated in 30-40 seconds!
You can have only one job to replicate all tables in Overwrite mode.
In the simplest case, you don’t need to create pipelines.
Cons
The Copy Job is work in progress and subject to various limitations.
No incremental extraction
You can’t mix different load options (Append and Overwrite) so you must split tables in separate jobs
No custom SQL SELECT when copying multiple tables
(Bug) Lost explicit column bindings when making changes
Cannot change the job’s JSON file
The user interface is clunky and it’s difficult to work with
No failure notification mechanism. As a workaround: add Copy Job to data pipeline or call it via REST API
Summary
In summary, the Fabric Google BigQuery built-in mirroring could be useful for real-time data replication. However, it relies on GBQ change history which requires certain permissions. Kudos to Microsoft for their excellent support during the private preview.
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “Are you modern yet?” and “Data Lakehouse: The Good, the Bad, and the Ugly”) but a recent assessment inspired to me write about this topic again. This newsletter advocates a hybrid and cautionary approach for data integration to avoid overdoing data lakes and warns about pitfalls of over-staging source data to files. It recommends instead following the “Discipline at the core, flexibility at the edge” methodology with emphasis on implementing enterprise data warehouse and organizational semantic models.
Data Lake Overstaging
How did the large vendor attempt to solve these horrible issues? Modern Data Warehouse (MDM) architecture of course. Nothing wrong with it except that EDW and organizational semantic model(s) are missing and that most of the effort went into implementing the data lake medallion architecture where all the incoming data ended up staged as Parquet files. It didn’t matter that 99% of the data came from relational databases. Further, to solve a data change tracking requirement, the vendor decided to create a new file each time ETL runs. So even if nothing has changed in the source feed, the data is duplicated should one day the user wants to go back in time and see what the data looked like then. There are of course better ways to handle this that doesn’t even require ETL, such as SQL Server temporal tables, but I digress.
At least some cool heads prevailed and the Silver layer got implemented as a relational ODS to serve the needs of home-grown applications, so the apps didn’t have to deal with files. What about EDW and organizational semantic models? Not there because the project ran out of budget and time. I bet if that vendor got hired today, they would have gone straight for Fabric Lakehouse and Fabric premium pricing (nowadays Microsoft treats partners as an extension to its salesforce and requires them to meet certain revenue targets as I explain in “Dissolving Partnerships“), which alone would have produced the same outcome.
What did the vendor accomplish? Not much. Nor only didn’t the implementation address the main challenges, but it introduced new, such as overcomplicated ETL and redundant data staging. Although there might be good reasons for file staging (see the second blog above), in most cases I consider it a lunacy to stage perfect relational data to files, along the way losing metadata, complicating ETL, ending up serverless, and then reloading the same data into a relational database (ODS in this case).
I’ve heard that the vendor justified the lake effort by empowering data scientists to do ML one day. I’d argue that if that day ever comes, the likelihood (pun not intended) of data scientists working directly on the source schema would be infinitely small since more than likely they would require the input datasets to be shaped in a different way which would probably require another ETL pipeline altogether.
Better Data Staging
I don’t subject my clients to excessive file staging. My file staging litmus test is what’s the source data format. If I can connect to a server and get in a tabular (relational) format, I stage it directly to a relational database (ODS or DW). However, if it’s provided as files (downloaded or pushed, reference data, or unstructured data), then obviously there is no other way. That’s why we have lakes.
Fast forward a few years, and your humble correspondent got hired to assess the damage and come up with a strategy. Data lakes won’t do it. Lakehouses and Delta Parquet (a poor attempt to recreate and replace relational databases) won’t do it. Fabric won’t do it and it’s too bad that Microsoft pushes Lakehouse while the main focus should have been on Fabric Data Warehouse, which unfortunately is not ready for prime time (fortunately, we have plenty of other options).
What will do it? Going back to the basics and embracing the “Discipline at the core, flexibility at edge” ideology (kudos to Microsoft for publishing their lessons learned). From a technology standpoint, the critical pieces are EDW and organizational semantic models. If you don’t have these, I’m sorry but you are not modern yet. In fact, you aren’t even classic, considering that they have been around for long, long time.
“Where are the prophets, where are the visionaries, where are the poets To breach the dawn of the sentimental mercenary” “Fugazi”, Marillion
I’ve written in the past about the dangers of blindly following “modern” data architectures (see my posts “Are you modern yet?” and “Data Lakehouse: The Good, the Bad, and the Ugly”) but here we go again. Once upon a time, a large company hired a large Microsoft partner to solve a common and pervasive challenge. Left on their own, departments have set up their own data servers, thus creating data silos leading to data duplication and inconsistent results.
How did the large vendor attempt to solve these horrible issues? Modern Data Warehouse (MDM) architecture of course. Nothing wrong with it except that EDW and organizational semantic model(s) are missing and that most of the effort went into implementing the data lake medallion architecture where all the incoming data ended up staged as Parquet files. It didn’t matter that 99% of the data came from relational databases. Further, to solve a data change tracking requirement, the vendor decided to create a new file each time ETL runs. So even if nothing has changed in the source feed, the data is duplicated should one day the user wants to go back in time and see what the data looked like then. There are of course better ways to handle this that doesn’t even require ETL, such as SQL Server temporal tables, but I digress.
At least some cool heads prevailed and the Silver layer got implemented as a relational ODS to serve the needs of home-grown applications, so the apps didn’t have to deal with files. What about EDW and organizational semantic models? Not there because the project ran out of budget and time. I bet if that vendor got hired today, they would have gone straight for Fabric Lakehouse and Fabric premium pricing (nowadays Microsoft treats partners as an extension to its salesforce and requires them to meet certain revenue targets as I explain in “Dissolving Partnerships“), which alone would have produced the same outcome.
What did the vendor accomplish? Not much. Nor only didn’t the implementation address the main challenges, but it introduced new, such as overcomplicated ETL and redundant data staging. Although there might be good reasons for file staging (see the second blog above), in most cases I consider it a lunacy to stage perfect relational data to files, along the way losing metadata, complicating ETL, ending up serverless, and then reloading the same data into a relational database (ODS in this case).
I’ve heard that the vendor justified the lake effort by empowering data scientists to do ML one day. I’d argue that if that day ever comes, the likelihood (pun not intended) of data scientists working directly on the source schema would be infinitely small since more than likely they would require the input datasets to be shaped in a different way which would probably require another ETL pipeline altogether.
I don’t subject my clients to excessive file staging. My file staging litmus test is what’s the source data format. If I can connect to a server and get in a tabular (relational) format, I stage it directly to a relational database (ODS or DW). However, if it’s provided as files (downloaded or pushed, reference data, or unstructured data), then obviously there is no other way. That’s why we have lakes.
Fast forward a few years, and your humble correspondent got hired to assess the damage and come up with remediation. Data lakes won’t do it. Lakehouses and Delta Parquet (a poor attempt to recreate and replace relational databases) won’t do it. Fabric won’t do it and it’s too bad that Microsoft pushes Lakehouse while the main focus should be Fabric Data Warehouse, which unfortunately is not ready for prime time (but we have plenty of other options).
What will do it? Going back to the basics and embracing the “Discipline at the core, flexibility at edge” ideology (kudos to Microsoft for publishing their lessons learned). From a technology standpoint, the critical pieces are EDW and organizational semantic models. If you don’t have these, I’m sorry but you are not modern yet. In fact, you aren’t even classic, considering that they have been around for long, long time.
So, keep on implementing these medallion lakes to keep my consulting pipeline full. Drop a comment how they work for you.
Previously, I discussed the pros and cons of Microsoft Fabric OneLake and Lakehouse. But what if you have a data lake already? Will Fabric add any value, especially if your organization is on Power BI Premium and you get Fabric features for free (that is, assuming you are not overloading your capacity resources)? Well, it depends.
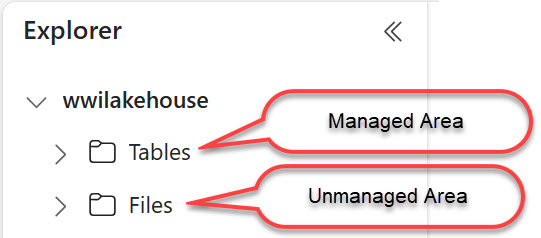
Managed Area
A Fabric lakehouse defines two areas: managed and unmanaged. The managed area (Tables folder) is exclusively for Delta/Parquet tables. If you have your own data lake with Delta/Parquet files, such as Databricks delta lake, you can create shortcuts to these files or folders located in ADLS Gen 2 or Amazon S3. Consequently, the Fabric lakehouse would automatically register these shortcuts as tables.
Life is good in the managed area. Shortcuts to Delta/Parquet tables open interesting possibilities for data virtualization, such as:
Your users can use the Lakehouse SQL Analytics endpoint to join tables using SQL. This is useful for ad-hoc analysis. Joins could also be useful so users can shape the data they need before importing it in Power BI Desktop as opposed to connecting to individual files and using Power Query to join the tables. Not only could this reduce the size of the ingested data, but it could also improve refresh performance.
Users can decide not to import the data at all but build semantic models in Direct Lake mode. This could be very useful to reduce latency or avoid caching large volumes of data.
Unmanaged Area
Very few organizations would have lakes with Delta Parquet files. Most data lakes contain heterogeneous files, such as text, Excel, or regular Parquet files. While a Fabric lakehouse can create shortcuts to any file, non Delta/Parquet shortcuts will go to the unmanaged area (Files folder).
Life is miserable in the unmanaged area. None of the cool stuff you see in demos happens here because the analytical endpoint and direct lake modes are not available. A weak case can still be made for data virtualization that shortcuts bring data readily available to where business users collaborate in Power BI: the Power BI workspace.
But what can the user do with these unmanaged shortcuts? Not much really. Power BI Desktop doesn’t even expose them when you connect to the lakehouse. Power BI dataflows Gen2 do give the user access to the Files folder so potentially users can create dataflows and transform data from these files.
Of course, the tradeoff here is that you are adding dependencies to OneLake which could be a problem should one day you decide to part ways. Another issue could be that you are layering Power BI security on top of your data lake security.
Oh yes, users can also load Parquet and CSV files to Delta tables by right-clicking a folder or a file in the Unmanaged area, and then selecting Load to Tables (New or Existing). Unfortunately, as it stands, this is a manual process that must be repeated when the source data changes.
Imagined Unmanaged Data Virtualization
This brings me to the two things that I believe Microsoft can do to greatly increase the value proposition of “unmanaged” data virtualization:
Extend load to table to the most popular file formats, such as JSON, XML, and Excel. Or, at least the ones that Polybase has been supporting for years. Not sure why we have to obsess with Delta Parquet and nothing else if Microsoft is serious about data virtualization.
Implement automatic synchronization to update the corresponding Delta table when the source file changes.
If these features are added, throwing Fabric to the mix could become more appealing.
In summary, Microsoft Fabric has embraced Delta Parquet as its native storage file format and has added various features that targets it. Unfortunately none of these features extend to other file formats. You must evaluate pros and cons when adopting Fabric with existing data lakes. As it stands, Fabric probably wouldn’t add much business value for data virtualization over file formats other than Delta Paquet files. As Fabric matures, new scenarios might be feasible to justify Fabric integration and dependency.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-13 14:19:362024-03-20 12:55:54What Can Fabric Do For My Lake?
Atlanta BI fans, please join us for the next meeting on Monday, September 11th, at 6:30 PM ET. Shabnam Waston (BI Consultant and Microsoft MVP) will introduce us to the Lakehouse engine in Microsoft Fabric. Shabnam will also sponsor the meeting. Your humble correspondent will help you catch up on Microsoft BI latest. For more details and sign up, visit our group page.
PLEASE NOTE A CHANGE TO OUR MEETING POLICY. WE HAVE DISCONTINUED ONLINE MEETINGS VIA TEAMS. THIS GROUP MEETS ONLY IN PERSON. WE WON’T RECORD MEETINGS ANYMORE. THEREFORE, AS DURING THE PRE-PANDEMIC TIMES, PLEASE RSVP AND ATTEND IN PERSON IF YOU ARE INTERESTED IN THIS MEETING.
Presentation: Introducing Lakehouse in Microsoft Fabric
Delivery: Onsite
Date: September 11th
Time: 18:30 – 20:30 ET
Level: Beginner to Intermediate
Food: Sponsor wanted
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
VENUE
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Join this session to learn about Lakehouse architecture in Microsoft Fabric. Microsoft Fabric is an end-to-end big data analytics platform that offers many capabilities including data integration, data engineering, data science, data lake, data warehouse, and many more, all in one unified SaaS model. In this session, you will learn how to create a lakehouse in Microsoft Fabric, load it with sample data using Notebooks/Pipelines, and work with its built-in SQL Endpoint as well as its default Power BI dataset which uses a brand-new storage mode called Direct Lake.
Speaker: Shabnam Watson is a Business Intelligence consultant, speaker, blogger, and Microsoft Data Platform MVP with 20+ years of experience developing Data Warehouse and Business Intelligence solutions. Her work focus within the Microsoft BI Stack has been on Analysis Services and Power BI and most recently on Azure Synapse Analytics. She has worked across several industries including Supply Chain, Finance, Retail, Insurance, and Health Care. Her areas of interest include Power BI, Analysis Services, Performance Tuning, PowerShell, DevOps, Azure, Natural Language Processing, and AI. She is a regular speaker and volunteer at national and local user groups and conferences. She holds a bachelor’s degree in computer engineering and a master’s degree in computer science.
Sponsor: Shabnam Watson
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-09-05 17:01:182023-09-05 17:01:18Atlanta Microsoft BI Group Meeting on September 11th (Introducing Lakehouse in Microsoft Fabric)
There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our Atlanta Power BI Group and you can find the recording here (I have to admit we could have done better job with the recording quality, but we are still learning in the post-COVID era).
What’s Data Lakehouse
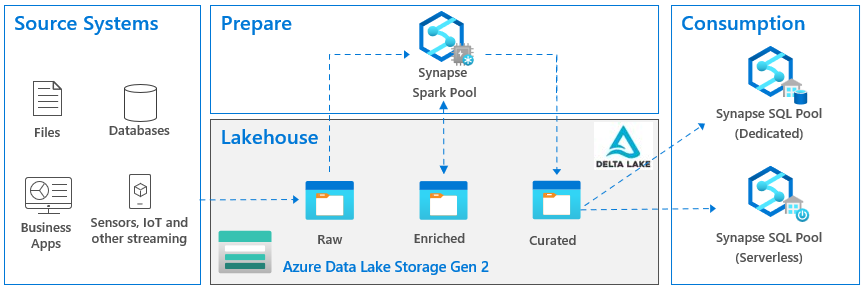
According to Databricks which are credited with this term, a data lakehouse is “a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.” It other words, it’s a hybrid between a relational data warehouse and a data lake. Sounds great, right? Visualizing this in Microsoft parlor, the last incarnation of the lakehouse architecture that I came across looks like this:
The Good
I’m sure that many large companies or companies with complex data integration needs could benefit from a similar architecture. As I said many times, staging data to a lake is a good thing when you must deal with files. For example, some cloud vendor that hasn’t matured enough to give direct access to your data, could decide to push files instead (I described a similar scenario in this blog). A “network share” on steroids, the data lake is the best place to store files. A good question here and the one I personally struggled with would be “what if the data comes from relational databases or from REST APIs?” Should you stage that data in a data lake as files before it flows into the data warehouse? A wise consultant’s answer here would be “it depends”. Here are some good reasons when this might make sense.
Stage data first – For some, a large ISV company (see related newsletter here), had to integrate data from many databases with similar but not the same schema. They preferred to stage the data to a data lake and figure out the integration “mess” caused my schema discrepancies and data quality later.
A glorified archive – For example, in case you want to reload the data, you can do it from the lake in the case where the source systems truncate data. However, my personal preference to address this scenario would be to stage the data into a relational Operational Data Store (ODS), especially in the case where changes must be tracked. In a nutshell, if I’m given a choice between a file or relational database, I’d go with the latter.
Synapse – If you decide to host your data warehouse in a Synapse dedicated SQL pool and use Azure Data Factory (ADF) to load the data, ADF will stage the data to Azure Data Lake Service (ADLS) anyway to load it faster into Synapse. Another good thing for Synapse here is that you can use Synapse Serverless to query that data using SQL which might come handy (I share some “serverless” lessons learned here).
Data science – There are some good reasons why data scientists prefer files instead of loading the data from a relational database. Or so I was told (I’m not a data scientist).
Uniformity – If your organization prefers a uniform data flow path despite the additional effort, inconvenience, and redundancy, then this might make sense. Then despite the source data type (structured or unstructured), all data follows the same ingestion pipeline. Just make sure to hire more ETL developers.
Outside these considerations, when you can connect directly to the data source, staging data to files is probably overkill as files are notoriously difficult to deal with.
The Bad
Now let’s look at the so-called zones in the lake: raw, enriched and curated, sometimes also referenced as bronze, silver, and gold. The idea here is to enrich the staged data. So, the raw zone has the staged data 1:1 as in the source. Then let’s say a data scientist needs some enrichment, and we spin more ETL to add a bunch of columns to some file. And then Business needs to reference the data that might require more enrichment. So, into the ETL rabbit hole we go again.
The problem is that many people take this architecture verbatum, whether it makes sense or not. A question came from the audience during Patrick’s presentation “What data do we add to these zones?” How do we know when it’s time to move to the next zone? And the answer here is that these zones are just a recommendation that someone has come up with. A large organization might benefit from them. But in most cases in my opinion spinning more and more ETL and moving data around just so that you follow some vendor’s best practices, makes no sense. And should you stage the data 1:1 from the source? In some cases, like the Get Data First aforementioned scenario, it might make sense. But in most cases, it would be much more efficient to stage the data in the shape you need it, which may necessitate joining multiple tables at the source (by the way, a relational server is the best place to handle joins).
The omni-presence of Synapse in such architectural diagrams is questionable at least. As I stated in another newsletter, like a red giant star, Synapse seems to engulf everything in its path in order to increase its value potential. But Synapse shouldn’t be a default choice for most organizations. It’s rather expensive and has limitations, such as lacking important T-SQL features.
Finally, Spark/Databricks that orchestrates the data preparation with Python or some other custom code since all the toolset you get is a notebook with a blinking cursor. What happened to low code, no code approach? More ETL developers to the rescue…
The Ugly
The omnipresence of the delta lake regardless if it makes sense or not. I’m sure that some scenarios for staging changing data into a lake, such as IoT streaming, will benefit greatly from a delta lake. But it shouldn’t be a default recommendation. The moment we introduce a delta lake, our tool choice becomes rather restricted because of the file format. On ETL side of things, for example, you must use data flows with Azure Data Factory (I’d personally favor ELT over data flows). And to read the data, you must provision either a Spark cluster or Synapse Serverless. So, complexity increases together with cost while data accessibility decreases.
UPDATE 05/28/2023 Microsoft Fabric embraced the delta format as the its native storage but provides more options, including Power Query dataflows and Azure Data Factory copy activity, to load data. All Fabric services save and read data from the delta lake and you don’t have to provision anything.
And if you go with Databricks (credited for inventing the delta lake too), they are far more ambitious . They want to replace RDBMs for OLAP (OLTP won’t work with a delta lake for performance reasons). We’ve seen similar claims before and how they ended. Another question came from the audience during the presentation was if a lakehouse can deliver the same performance as a relational database. One house must be redundant, right? True, after rewriting their software, Databricks can deliver some decent performance (they even claim to be the world’s fastest “data warehouse” although only one other vendor submitted results to that specific benchmark). James Serra (Data & AI Solution Architect at Microsoft), whose excellent blog discusses these topics in detail, recently gave our group a presentation and said that anyone he knows of that has tried replacing a relational data warehouse with a data lake, has failed. Enough said.
What’s a best practice? A best practice to me is adopting the most efficient way to achieve something without sacrificing too much flexibility for what might be thrown at you in the future. To me, a lakehouse as a replacement for a relational data warehouse or as a default staging area is as big of a hype as Big Data was, with all the vendor propaganda surrounding it to buy stuff you don’t need. Large organizations with complex integration needs might benefit from the lakehouse architecture shown above. However, most companies could save a lot of implementation, maintenance, and licensing costs by simplifying it and judicially introducing pieces when it makes sense.
Please join us for the next meeting on Monday, March 6th, at 6:30 PM ET. Leo Furlong (Senior Solutions Architect at Databricks) will share their point of view on why “the best data warehouse is a lakehouse.” For more details and sign up, visit our group page.
PLEASE NOTE THAT OUR IN-PERSON MEETING LOCATION HAS CHANGED! WE STRONGLY ENCOURAGE YOU TO ATTEND THE EVENT IN PERSON FOR BEST EXPERIENCE. ALTERNATIVELY, YOU CAN JOIN OUR MEETINGS ONLINE VIA MS TEAMS. WHEN POSSIBLE, WE WILL RECORD THE MEETINGS AND MAKE RECORDINGS AVAILABLE AT HTTPS://BIT.LY/ATLANTABIRECS. PLEASE RSVP ONLY IF COMING TO OUR IN-PERSON MEETING.
Presentation: The Semantic Lakehouse: Power BI and Databricks
Date: March 6th
Time: 18:30 – 20:30 ET
Place: Onsite and online
Level: Intermediate
Food: Food and drinks will be available for this meeting
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
Overview: The team from Databricks will come and share their point of view on why “the best data warehouse is a lakehouse.” We’ll go over lakehouse 101, when you might (or might not!) need a lakehouse, some best practices for operating a BI solution with Databricks, and walk through a demo highlighting how PowerBI’s and Databricks’ SQL capabilities complement each other.
Speaker: Leo Furlong, Senior Solutions Architect at Databricks Leo is a seasoned data and analytics professional with 15 years of consulting experience building Data Warehousing and BI solutions using SQL Server, Power BI, and Azure technologies prior to joining Databricks in 2021. As an Atlanta native, Leo is a Georgia Tech and Georgia State grad and lives in the Smyrna/Vinings area with his 4 kids and 4 dogs.
Sponsor: Databricks
Prototypes with Pizza: Power BI Latest with Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2023-03-03 15:37:022023-03-03 15:37:02Atlanta MS BI and Power BI Group Meeting on March 6th (The Semantic Lakehouse: Power BI and Databricks)


 I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “
I’ve written in the past about the dangers of blindly following “modern” data architectures (see the “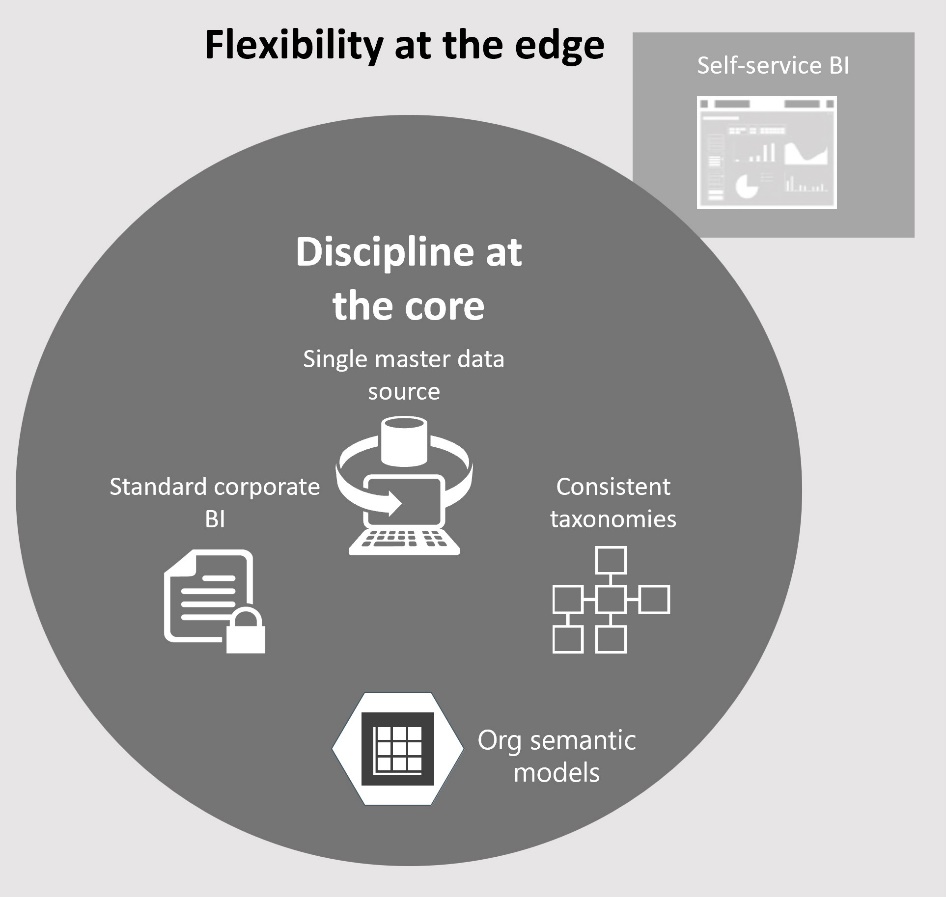

 There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our
There has been a lot of noise surrounding a data lakehouse nowadays, so I felt the urge to chime in. In fact, the famous guy in cube, Patrick LeBlanc, gave a great presentation on this subject to our