A First Look at Microsoft Fabric: The Good, the Bad, and the Ugly
“May you live in interesting times” – Chinese proverb
Microsoft Fabric is upon us with a grand fanfare. You can get a good overview of its vision and capabilities by watching the Microsoft Fabric Launch Digital Event (Day 1) and Microsoft Fabric Launch Digital Event (Day 2) recordings. Consultants and experts are extolling its virtues and busy fully aligning with Microsoft. There is a lot of stuff going on in Fabric and I’m planning to cover the technologies I work with and care about in more detail in future posts as Microsoft reveals more what’s under the kimono. This post is about my overall impression on Fabric, in an attempt to cut through the dopamine and adrenaline-infused marketing hype. As always, please feel free to disagree and provide constructive criticism.
The Good
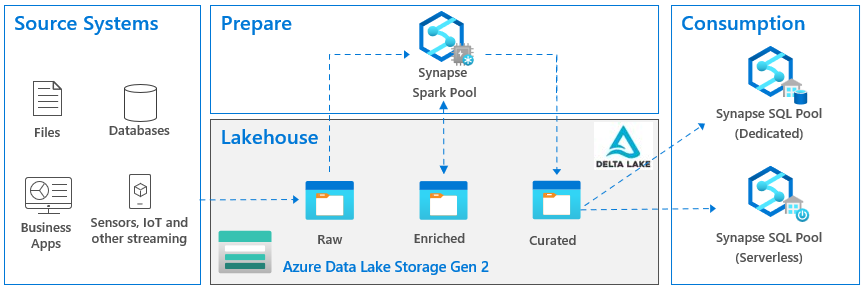
Let’s just say that after 30 years working with Microsoft technologies, I’m very, very skeptical when I hear loaded terms, like “revolutionary”, “one-something”, “never has been done before”, etc. We all witnessed impressive launches for products that wouldn’t last a year. But it looks like this time Microsoft got their act together and put something that may pass the test of time and that I could recommend or use to help clients. As a starter, I’m glad that we’ve finally settled on a common and open storage (delta and Parquet) after years of experimenting with proprietary and open formats (CDM folders anyone?). This common storage has several advantages, including accessibility, portability, and virtualization.
I also like very much that Microsoft doesn’t enforce or propel a specific architecture or data flow pattern. If you want a lakehouse, sure you can have it. Care about medallion file organization? Sure, you can do that. Don’t want a lakehouse but data warehouse if you don’t deal with files and you don’t like a notebook with a blinking cursor? Not a problem. Want to skip staging data as files to the lake and load it directly in the warehouse? Fine. This is very different approach than other vendors take, such as to promote data warehousing on top of lakehouses and/or rule out relational databases whatsoever (read my thoughts on this here).
It’s obvious that a gigantic effort has taken place to unify and in same cases rewrite products, such as Analysis Services and Synapse Data Warehouse, to adhere to this new platform and vision. Basically, Fabric is the focal point of decades of hard work from all Microsoft teams involved in analytics to at least make a complicate data estate easy to access and manage.
The Bad
Going back to the presentation and my skepticism, I wish Microsoft could dialed down on some promises, like “one copy” of data. Anyone who has implemented a data warehouse of a decent complexity knows that data duplication is necessary. Data exists in the source systems, needs to be staged, and then transformed. Right there we have three copies. True, virtualization might help us avoid some data movement scenarios, such as accessing data directly in S3 buckets or importing in a Power BI dataset (for most companies a few extra minutes for refreshing datasets is not an issue).
Speaking of companies, it’s clear that Fabric (and presenters in the videos) targets the needs of large organizations with complex integration scenarios. But for most organizations “Big Data” is a few million rows and most common integration task is analyzing data from one or multiple ERPs. Should they care about Fabric? I guess it would really depend on its value proposition and budgets, but Fabric pricing hasn’t been announced yet. If Fabric is not available in PPU (Premium Per User), it probably would be dead on arrival for smaller organizations, as they can get modern analytics by spending less than $200/month on infrastructure excluding Power BI per-user licenses.
Finally, although presenters highlighted avoiding vendor lock-in as one of the major benefits of Fabric, you’re going to put all your eggs in one basket: Power BI/Fabric. Making Power BI a one-stop destination for analytics makes of course a lot of sense to Microsoft and increases its revenue potential (nothing wrong with revenue if it brings value). But for you Fabric would be a long-term commitment and you better make sure you avoid Microsoft-proprietary features as much as you can, such as Power Query dataflows and Azure Factory dataflows, should one day you decide to divest from Fabric, Power BI, or even Azure. Otherwise, you might find yourself in a similar situation as this client who had to migrate hundreds of Alteryx flows.
The Ugly
Confusion has descended upon the BI land after Microsoft throws and abandons products left and right. In fact, the Fabric documentation has sections to help you choose product, such as Lakehouse, New Synapse data warehouse, Power BI datamart (that one is easy, stay away from it especially if you plan to adopt Fabric). Should we add Synapse Dedicated Pools and Azure SQL Database to the comparison table?
Further, rewriting these engines means that we must go back to square one and wait for features. For example, the new Synapse data warehouse lacks so many T-SQL features and outside my plans for any near-term projects. Just when I thought Synapse SQL dedicated pools were caching up on T-SQL parity, someone moved my cheese… Well, good things happen to those who wait, so let’s give Fabric a year or so.
Other Fabric related posts:
- Fabric OneLake: The Good, the Bad, and the Ugly
- Fabric Lakehouse: The Good, the Bad, and the Ugly
- Fabric Warehouse: The Good, the Bad, and the Ugly
- Fabric Data Integration: The Good, the Bad, and the Ugly
- Fabric Semantic Modeling: The Good, the Bad, and the Ugly
- A First Look at Microsoft Fabric: Recap