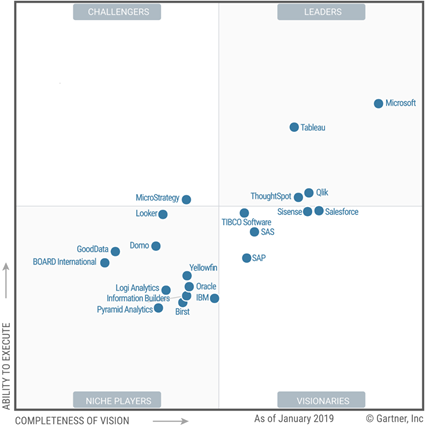
The 2019 Gartner Quadrant for Analytics and BI Platforms is out and Microsoft BI aficionados like your humble correspondent have all the reasons to rejoice. Say whatever you want about Gartner but the quadrant is a great testimonial for Power BI and I think the highest score was overdue. Microsoft still has tons of work on the visualization side of things but I’m glad that Gartner recognized the business value of Power BI which exceeds by far any other BI tool on the market. A few comments on the cautions in the report:
Differences in on-premises and cloud service with Azure cloud only – This is about the discrepancies between Power BI and Power BI Report Server which I discussed last year. Revisiting this, I’d like to know how many customers have complained. In my practice, I don’t see much interest in Power BI Report Server for deploying Power BI reports as everyone wants to be in the cloud.
Integration of Mode 1 and Mode 2 – This is the same “caution” as last year which is already covered by the first caution so I’m not sure why it’s reiterated. “With Power BI, Microsoft has mainly focused on requirements for Mode 2 (agile, self-service) analytics. On-premises SQL Server Reporting Services meets the needs of Mode 1”. I think Gartner will be happy once the SSRS integration is fully baked in Power BI Premium.
Multiple products – Kind of repeated from last year by phrased somewhat differently “Although the core of Power BI is a self-contained product, Microsoft’s roadmap spans multiple products.” So, the same comment. I don’t see a problem with having multiple products if they can integrate. Especially given that some are free, such as PowerApps and Flow with O365. The reason why they are separate products is that they don’t apply to BI only. And which BI vendor has flow, business apps, predictive models, in the same product? Not to mention that other vendors don’t have anything more than just a reporting tool.
Perhaps, the next most difficult thing after getting to the top is remaining on the top. Will Microsoft sustain the Power BI leader position or gradual attrition and shifting priorities will let smaller and more agile vendors dethrone it?
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-02-14 16:32:272019-02-15 15:42:202019 Gartner Magic Quadrant for Analytics and Business Intelligence Platforms
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on February 4th, Monday at 6:30 PM at the Microsoft office in Alpharetta. The main presentation will be “Azure Data Lake for First Time Swimmers” by Samara Soucy from Innovative Architects. Julies Smith will do us Prototypes with Pizza on “Python Fuzzy Wuzzy for Master Data Identity Mapping”. Innovative Architects will sponsor the event. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the group page) if you’re planning to attend.
Presentation:
Azure Data Lake for First Time Swimmers
Date:
February 4, 2019, Monday
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009
Overview:
Data Lake may be the hot new way to store data for reporting, but it can be scary if you’ve never dealt with one. If you have no idea what a data lake is, have no fear! You will get an intro to the concept of data lake and what scenarios you should be considering it as your platform. From there you’ll get to see how Azure Data Lake Analytics and U-SQL allow developers and data professionals to create compelling analytics with data that previously was difficult to work with.
Speaker:
Samara is a Microsoft Certified Specialist in C#. Working in both web and data, she has experience in a wide variety of technologies including JS, .Net, SQL, Analysis Services, and Power BI. Working with Innovative Architects as a Software Develoment Consultant, she uses that knowledge to plug into whatever part of their system needs additional expertise.
Sponsor:
Innovative Architects specializes in solving business problems around business intelligence, data management, e-commerce, portals & collaboration, custom application engineering and business process and integration. https://innovativearchitects.com/
Prototypes with pizza
“Python Fuzzy Wuzzy for Master Data Identity Mapping” by Julie Smith
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-01-30 07:41:262021-02-17 01:01:59Atlanta MS BI and Power BI Group Meeting on February 4th
xVelocity (the storage engine behind Tabular, Power BI and columnstore indexes) is an in-memory columnar database, and it’s such it’s not suitable for detail-level reports, such as transaction-level reports. I wrote about performance implications with xVelocity and detail-level reporting here and here. In general, the lower the report grain and the more columns you add to the report (customer first name, last name, invoice number, etc.), the slower the performance will be as more and more columns would need to be scanned and cross-joined.
A recent Tabular project brought another twist. Most measures (about 250 total) were produced on top of a biggish snapshot table (250 million rows) and Customer table (12 million rows). As a best practice, base measures were created with common filters and then other measures would piggy back on the base measures like Russian dolls. It’s a best practice because if you must change a filter, you need to change only the base measures. For example, a [Number of Open Accounts] measure would filter the snapshot to find how many open accounts the customer has. Then, a [Number of Open Accounts: Banks] would apply another filter:
[Number of open accounts ever] (‘Creditor'[Subscriber Segment] = “Bank”)
Then, a web app will let the end user specify the customer identifiers and send a DAX query to the model to request all the 250 measures. The client complains that the query takes a long time and there isn’t much difference in the query execution for one customer or 100. To Microsoft credit, had the measures have the same filter, a “fusion cache” (introduced I believe in 2016 under “super DAX”) would kick in to reduce queries to the storage engine. For example, if the query requests SalesAmount, OrderQuantity, and other measures and they all have the same filters, this fusion cache will cache queries to the storage engine and help with the query execution. But the cache doesn’t work if measures have different filters irrespective if their definitions are nested or not. Consequently, each measure sends a separate query to the storage engine. So, if the query requests 100 measures for one customer, the storage engine will be queried 100 times and the 250 million snapshot table will be scanned 100 times for that one customer even if there are only a few transactions for that customer. This is a terribly inefficient way!
The first thing a database developer would do to solve this straight in SQL is to create a temporary table to extract the data for the selected customers before calculating the measures. But Tabular is not SQL Server. It would be great if at some point, it could introduce a caching mechanism to let the developer copy a subset of “rows” in the cache (in this case, extract rows from the Account Snapshot for the selected customers), and then transparently redirecting the snapshot queries to the cache (like how Power BI aggregations work today).
As things stand today, one way you can reduce the query execution time is to eliminate large joins. In this case, the DAX query filters the Customer table because some measures are produced from other tables. But you can split the query into multiple queries for the different tables and then apply the customer filter directly on the table bypassing the Customer table. So, instead of:
In this case, eliminating the Account Snapshot -> Customer join resulted in 50% improvement in the query execution time.
But you should also consider using the right tool for the job at hand and for detail-level reports this could be a relational database which reads data by rows and not columns.
I taught my Applied Power BI class last week to a group of smart data analysts. All of them were knowledgeable of T-SQL, which they have been using extensively for years to shape and transform the data and produce SSRS, Qlik and now Power BI reports. They haven’t previously used Power Query, but they liked my overview of its features. However, they were rightfully confused when to use T-SQL, Power Query, or DAX. Starting with the data source and moving up the chain, Power BI lets you use expressions in:
Data source (custom SQL Query, SQL view)
Power Query
DAX calculated columns
DAX measures (the uppermost level)
My advice is to invest time and learn all these capabilities. When you have diverse skills, you can use the best tool for the task at hand.
Although is hard to generalize as every data transformation is different, I recommend you shape the data as upstream (closer to the data source) as possible. So, if you are familiar with T-SQL and that’s your primary data source, then use T-SQL. As one of the Microsoft best products, SQL Server has been enjoying 30 years of continuous improvements. Not only can you apply the skills you already have, but you will gain in performance when you use T-SQL and delegate data crunching to SQL Server which is what it’s designed to do. You can also benefit from the rich data manipulation features of T-SQL. These are the same reasons why I favor the ELT (Extract, Load and Transform) pattern in organizational BI solutions instead of SSIS data flow transforms. And if you find T-SQL lacking in features, Power Query can supplement it nicely, such as to fill down missing values, quickly unpivot data, or apply fuzzy lookup.
When you connect to data sources that don’t support SQL, such as flat files or Excel, the next natural place is Power Query to shape and transform the data. The choice between Power Query and DAX calculated columns is a tricky one and typically involves a compromise between performance and skill set. In many cases, you’ll find that a custom column can be implemented both in Power Query and DAX calculated columns. In general, if performance is OK, use Power Query, which is further upstream than DAX calculated columns. As a bonus, your data model will see the custom columns as regular columns and compress them equally well. Consider DAX calculated columns (one level up Power Query) when:
You must use DAX features that Power Query lacks, such as ranking.
When Power Query transforms lead to long data refresh times, such as a lookup between two large tables.
Finally, while custom columns can be often implemented in any of the first three layers, DAX measures are unique, and they typically can be implemented in DAX only. For example, if you need the expression to reflect the end user filter selection, you must use a DAX measure because only DAX measures are evaluated at run time and can access runtime conditions, such as values from filters and slicers.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-01-20 11:51:072019-01-20 16:32:07T-SQL, Power Query, or DAX?
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on January 7th, Monday at 6:30 PM at the Microsoft office in Alpharetta. The main presentation will be “Predictive Analytics with Power BI”. I’ll walk you through the existing Power BI features for predictive analytics. Mark Tabladillo will show you exiting AI features that are coming up soon. CDATA will sponsor the event and do us a 15-min demo of their Power BI connector. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the main page) if you’re planning to attend.
Presentation:
Predictive Analytics with Power BI
Date:
January 7, 2019, Monday
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009
Overview:
Predictive analytics, also known as data mining, machine learning, and artificial intelligence (AI), is an increasingly popular requirement. Fortunately, you don’t have to be a data scientist to benefit from machine learning in Power BI. This session is organized in two parts:
Part 1 – We will revisit the existing machine learning features in Power BI, including Quick Insights, Explain Increase/Decrease, linear forecasting, integration with R and Python.
Part 2 – We will look at exciting new features that are coming up in near future, such as integration with Azure ML and Cognitive Services, and automated machine learning.
Speaker:
Mark Tabladillo Ph.D. is a data scientist at Microsoft. His career has focused on industry application of advanced analytics, using a variety of analytics tools including SAS, SQL Server Analysis Services, Cortana Intelligence (including Microsoft R Server and Microsoft Machine Learning Services), R, and Python. He was a founding member of the Atlanta Microsoft BI User’s Group in 2010.
Through his Atlanta-based company Prologika (https://prologika.com), a Microsoft Gold Partner in Data Analytics, Teo Lachev helps organizations make sense of their most valuable asset: their data. Teo has authored and co-authored several bestselling books on organizational and self-service data analytics, and he has been leading the Atlanta Microsoft BI and Power BI group since he founded it in 2010. Teo has been a Microsoft Most Valued Professional (MVP) Data Platform since 2010.
Sponsor:
CData Software is a leading provider of data access and connectivity solutions. We specialize in the development of Drivers and data access technologies for real-time access to on-line or on-premise applications, databases, and Web APIs. Our drivers are universally accessible, providing access to data through established data standards and application platforms such as ODBC, JDBC, ADO.NET, OData, SSIS, BizTalk, Excel, etc.
https://cdata.com
Prototypes with Pizza
“TBD”
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-01-02 09:08:562021-02-17 01:01:59Atlanta MS BI and Power BI Group Meeting on January 7th
I’m excited to announce the fourth edition of my Applied Microsoft Power BI book! When the original book was published in January 2016, it was the first Power BI book at that time and it had less than 300 pages. Since then, I helped many companies adopt or transition to Power BI and taught hundreds of students. It’s been a great experience to witness the momentum surrounding Power BI and how the tool matured over time. As a result, the book got thicker too and it now stands at 500 pages. However, I believe what’s more important is that this book provides systematic, yet dependent, view by showing what Power BI can do for four types of users (business users, analysts, pros, and developers).
This is the only Power BI book that gets annual revisions to keep it up to date with this ever changing technology! Because I had to draw a line somewhere, Applied Microsoft Power BI (4th edition) covers all features that are in preview or released by December 2018. As with my previous books, I’m committed to help my readers with book-related questions and welcome all feedback on the book discussion forum on the book page. While you are there, feel free to check out the book resources (sample chapter, front matter, and more). I also encourage you to follow my blog at https://prologika.com/blog and subscribing to my newsletter at https://prologika.com to stay on the Power BI latest.
Bring your data to life for the forth time! Keep on reading, learning, and Happy New Year!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-12-31 08:34:392018-12-31 23:50:43Applied Power BI Book (4th Edition)
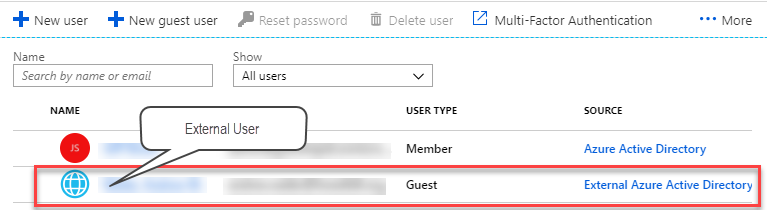
Power BI lets you share content directly with external users for B2B and B2C scenarios. When the benefits of this sharing option outweigh its limitations (read-only reports, requiring Azure AD federated access, per-user licensing, rendering the report inside Power BI), this is the easiest way to share Power BI content with an external party. However, the documentation, which is otherwise excellent, doesn’t explain the steps required to allow the external user to see only a subset of data when you have a dataset configured for data (RLS) security.
Granting access to an external user to a dataset configured for data security is like the proverbial chicken and egg problem. To grant access to the report, you need to share the report with the user, but you can’t add the user to the security role because the user is not provisioned yet. Hence, you’ll first share a non-sensitive report with the user before you share the actual report.
Create an organizational workspace. I recommend you create a v2 workspace for the benefits I outlined in my “Power BI Sharing Is Getting Better” blog.
In Power BI Desktop, import some sample data that is OK for the end user to see. Create a simple report for testing. A dataset is required because for some obscure reason, Power BI will prevent you from sharing an empty report that doesn’t have a dataset. Publish the Power BI Desktop file to powerbi.com.
Share the non-sensitive report with the external user. At this point, if you examine the user account in Azure Active Directory in the Azure Portal (portal.azure.com), it will show that the user is invited.
When the user gets the email, clicks the link, and navigates the prompts, the user will be eventually added to your tenant’s Active Directory and will show as Guest in the External Azure Active Directory source.
Now you can assign a Power BI Pro license to this user in the Azure Portal. Remember that unless you are on Power BI Premium, any form of sharing requires a Power BI Pro license. One gotcha here is that the Azure Portal might refuse assigning a Power BI Pro license with the following error “License cannot be assigned to a user without a usage location specified.” To fix this horrible issue, go to Azure Active Directory (Users tab), click the external user, click Edit in the Settings section in the user profile, and then use the “Usage location” drop-down to select the country where the user is located.
At this point, the external user is added to your tenant’s active directory and covered by Power BI Pro license. Next, publish the actual Power BI Desktop file with the sensitive report you want to share. This file should have a role that applies a row filter to one or more tables to enforce data security in a multi-tenant dataset. Once the file is published to powerbi.com, go to the dataset Security setting and add the external user to the role by typing the user’s email.
The last step is to share the report with the external user.
TIP: If you have a lot of external users, consider assigning them to a security group so you can grant access to the group instead of individual emails. Also, instead of sharing individual reports and dashboards, use Apps to grant access to the security groups. Note that as I explained in the “Power BI Sharing Is Getting Better” blog, currently you can’t assign viewers as members of the workspace. You must use either dashboard/report sharing or apps.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-12-28 15:59:532018-12-28 15:59:53Power BI External Users and Data Security
Happy Holidays! I hope you’re enjoying this special time of the year. According to Gartner, “poor data quality is hitting organizations where it hurts – to the tune of $15 million as the average annual financial cost in 2017″. Data integration is another huge challenge, you know it and I know it. Microsoft hopes that Power BI dataflows will help data analysts tackle these issues and dataflows are the subject of this newsletter. But before I give you my opinion about this newcomer, I’m excited to announce the availability of the fourth edition of my “Applied Microsoft Power BI” book – the only Power BI book that it’s updated every year to keep it up with the ever-changing world of Power BI and the Microsoft Data Platform! The book is making slowly its way to the retailers and it should be available on Amazon in the first days of 2019.
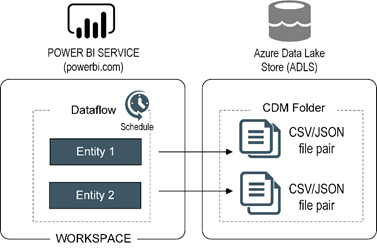
What’s a dataflow?
I’m sure that by now you’ve heard about Power Query – a tool that is integrated with Power BI Desktop to help the data analyst clean and shape the data. The issue with the Power Query though is that it’s tightly coupled with Power BI Desktop while data integration challenges sometimes need to be solved at a larger scale. Think of dataflows as “Power Query in the Cloud”. Dataflows is to self-service BI what ETL is to Power BI pros.
A dataflow is a collection of Power Query queries, also known as entities, and it lives in a Power BI organizational workspace.
For example, if I want to stage data from Salesforce, I can create a dataflow with as many entities as Salesforce tables I want to stage. Unlike Power Query, which can only output to a table in a data model, a dataflow saves its output as a pair of a CSV file (data) and JSON file (metadata) in a Microsoft provided data lake store.
So, for the BI pros who are familiar with SSIS projects for ETL, think of a dataflow as a project and queries as SSIS packages. Just like you can deploy an SSIS project and schedule it to run at a specific time, you can schedule a dataflow, and this will execute all its queries.
The Good
There is a lot to like about dataflows. I can think of two primary self-service scenarios that can benefit from dataflows:
Data staging – Many organizations implement operational data stores (ODS) and staging databases before the data is processed and loaded in a data warehouse. As a business user, you can use data-flows for a similar purpose. For example, one of our clients is a large insurance company that uses Microsoft Dynamics 365 for customer relationship management. Various data analysts create data models from the same CRM data, but they find that refreshing the CRM data is time consuming. Instead, they can create a dataflow to stage some CRM entities before importing them in Power BI Desktop. Even better, you could import the staged CRM data into a single dataset or in an organizational semantic model to multiple data copies and duplicating business logic.
Certified datasets – One way to improve data quality and promote better self-service BI is to prepare a set of certified common entities, such as Organization, Product, and Vendor. A data steward can be responsible for designing and managing these entities. Once in place, data analysts can import the certified entities in their data models.
There is a solid architecture, vision, and investments behind dataflows. You create dataflows using a tool that you’re already familiar with: Power Query. If you know Power Query, you know dataflows. Microsoft has provided the data lake storage and pricing is included in Power BI Pro/Power BI Premium. So, you have everything you need to get started with dataflows today. Ingesting the dataflow output is very fast too because you import CSV files.
The Bad
My blog on same subject started with positioning as I was left with the impression from watching the MS presentations that Microsoft encourages business users to consider dataflows for any data integration task, from data staging to loading data warehouses and even replacing data warehouses and ETL (heard that vibe before?) But Matthew Roche clarified that “dataflows don’t replace data warehouses and ETL any more than Power BI desktop replaces a full set of BI pro tools. Dataflows complement these pro tools, and enable users who are not BI pros to fill in more gaps in a BI solution, similar to other Power BI capabilities. Although dataflows mean that self-service users can do more without help, the same patterns still apply”. So, consider this if you hear a different propaganda and use the right tool for task at hand.
You need Power BI Premium to realize the full potential of dataflows. For some obscure reason, features like linked and computed entities are not available in Power BI Pro. I wonder how many customers will feel pushed to go Power BI Premium as more and more features are only available there. I don’t mind scalability and performance related features but incremental refresh and linked entities?
Lastly, the CSV output is both a blessing and a curse. True, ingestion is fast, but text files are not a relational database. Business users can’t make direct changes to the staged data. Further, the only option is to import the dataflow output in Power BI as DirectQuery is not available for text files.
The Ugly
As dataflows stand today (in preview), you (almost) can’t access directly the output generated by dataflows. This precludes the continuum between self-service and organizational worlds. For example, IT might need to import a certified dataset into a data warehouse. But you can only connect to a dataflow in Power BI Desktop because the CSV files are not directly accessible. True, Power BI Premium lets you bring your own data lake storage (currently a preview feature), but a better option in my opinion was to provide access to the raw data in both Power BI Pro and Premium given that this is your data lake and your data.
If you have used SSRS, you know that paginated reports are very customizable, and you can make almost any property expression-based. Power BI is yet to deliver expression-based properties to change settings based on runtime condition, such as to change the font style based on the actual value or user selection. Currently, there are two places where you can use a DAX measure for expression-based formatting of colors:
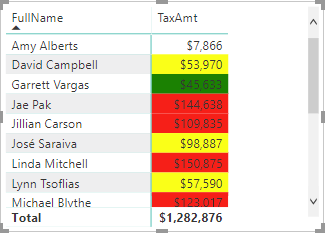
Conditional formatting
You can use a DAX measure to change the fore color or background color when you apply conditional formatting to cells in Table and Matrix reports. To do so, when you configure the conditional formatting settings, choose the Field Value option. In the following report, I used a DAX measure to format the TaxAmount field with the following formula:
Although the measure defines three bands of colors, which you can do by just using rules, it can also check additional runtime conditions, such as what field is used on the report or what value the user has selected in a slicer. You can also specify custom colors by using the hex triplet notation, such as #00AA09.
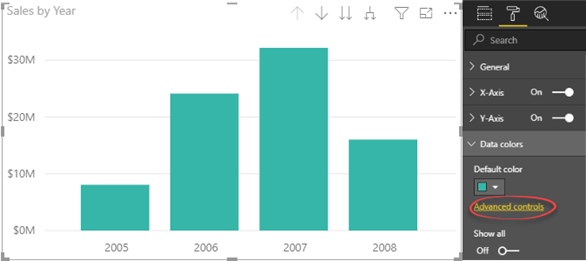
Chart data colors
Some charts with single data series, such as column and bar charts, support “Advanced controls” in the “Data colors” section of the Format tab in the Visualizations pane. This link brings you to the same window that you use to configure conditional formatting and you can use the “Field value” option to choose a DAX measure.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-12-15 15:34:062018-12-15 15:35:32Expression-based Formatting in Power BI
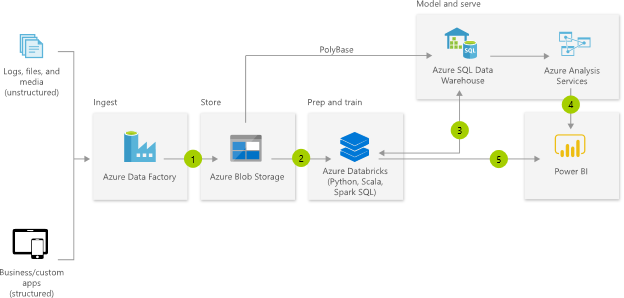
If you’re a BI architect responsible for designing Azure-based cloud BI solutions and you’re not following the James Serra’s blog, you’re missing a lot. Previously an independent consultant and MVP, James works now as a Big Data/Data Warehouse Evangelist at Microsoft. I can’t agree more with his latest blog “Should I load structured data into my data lake?”
We’ve heard a lot lately about what the “modern” data warehouse architecture should look like from Microsoft and other vendors. Here is the diagram taken from, you guessed it, the Microsoft Modern Data Warehouse page.
The problem is that many organizations take this diagram verbatim when it makes sense and when it doesn’t. For example, a client exports data from on-premises relational databases to text files in Azure Data Lake, only to load it later in a cloud data warehouse. To my observation that this is redundant and pointless, they answered that I shouldn’t deemphasize the “whole Big Data” architecture should one day their users decide to do machine learning. To my observation that should this moment arrive, data scientists will benefit more if the data is readily accessible in a relational database, they said that it contradicts what Microsoft recommended.
Of course, this “modern” architecture makes a lot of sense to the vendor (it’s a nice and perpetual revenue stream) or the consulting partner (the more stuff, the higher the bill) but more than likely is an overkill for you. Here are the most common issues I see organizations making on their BI journey to the cloud:
Excessive data movement – The more you move the data, the more problems. You know it and I know it. Data quality issues, latency, maintenance and endless troubleshooting, etc. In another case, I saw a Cosmos DB sneaked in between, just in case there is too much structure in the source data.
Architecture “gold plating” – A classic example, which the diagram perpetuates, is Azure SQL Data Warehouse. If you have a few million rows of data in your data center, would you buy Teradata? Of course, you wouldn’t! Now, just because you can afford the monthly premium for Azure SQL Data Warehouse, why would you go for an MPP platform? Not to mention that more than likely you’d have to redo your entire ETL if you are migrating from premises as there is still no T-SQL parity. I wouldn’t even consider Azure SQL Data Warehouse for workloads less than 1 TB. And not even then because a semantic model will probably do the heavy lifting. And on ETL, where Microsoft recommends ADF, read my thoughts on it here.
Migrating to the cloud to save cost – No vendor would let its cloud (or whatever) alternative cannibalize another offering. For me, your primary goal for migrating to the cloud should be not cost savings but reliability and convenience. Try to get your IT department to promise SLA or promise anything for that matter. Or provision a VM in minutes? Cost alone, more than likely you’ll spend more moving to the cloud, especially if you go PaaS. For example, a client found that their bill went up astronomically because each BI PaaS offering (Database Engine, Analysis Services, ETL, Power BI) has its own pricing compared to covering all of these with a single SQL Server EE license in their data center. The “modern” architecture above could easily run $50,000/mo which is what a perpetual SQL Server EE license will cost you but over years.
They asked a famous writer one day when he knows that the manuscript is done, and he said when there is nothing more to take out. This principle should apply to BI architectures too. What can you take out to meet the business requirements without overcomplicating? It does cost a lot to be “modern”.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-11-28 21:51:382018-11-29 08:22:56Are You Modern Yet?



 Happy Holidays! I hope you’re enjoying this special time of the year. According to
Happy Holidays! I hope you’re enjoying this special time of the year. According to