Atlanta BI fans, please join us in person for the next meeting on Monday, April 1st at 6:30 PM ET. Aravinth Krishnasamy (Principal Architect at Ecolab) will provide an end-to-end overview of Microsoft Fabric real-time analytics capabilities. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Presentation: Real-Time Analytics with Microsoft Fabric: Unlocking the Power of Streaming Data
Delivery: In-person
Date: April 1, 2024
Time: 18:30 – 20:30 ET
Level: Beginner/Intermediate
Food: Pizza and drinks
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Microsoft BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: This session will provide an end-to-end overview of Microsoft Fabric Real-Time Analytics capabilities. We will go over the following topics:
1. Introduction to Real-Time Analytics: Overview of the platform and its capabilities
2. Data Ingestion: How to ingest data from various streaming sources into Fabric
3. Data Analysis & Visualization: How to analyze and visualize data using Real-Time Analytics and Power BI
4. Use Cases: Real-world use cases for Real-Time Analytics.
Speaker: Aravinth Krishnasamy is a Principal Architect at Ecolab, where he focuses on business intelligence, data warehousing and advanced analytics applications. Aravinth holds numerous technical certifications and has over 18 years of IT experience.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-26 11:50:102024-03-26 11:50:10Atlanta Microsoft BI Group Meeting on April 1st (Real-Time Analytics with Microsoft Fabric: Unlocking the Power of Streaming Data)
Previously, I discussed the pros and cons of Microsoft Fabric OneLake and Lakehouse. But what if you have a data lake already? Will Fabric add any value, especially if your organization is on Power BI Premium and you get Fabric features for free (that is, assuming you are not overloading your capacity resources)? Well, it depends.
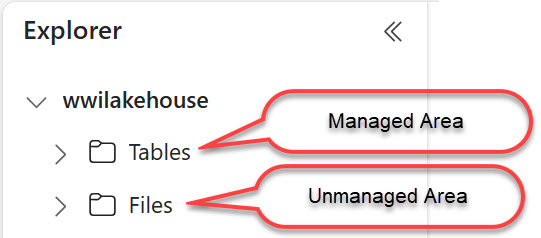
Managed Area
A Fabric lakehouse defines two areas: managed and unmanaged. The managed area (Tables folder) is exclusively for Delta/Parquet tables. If you have your own data lake with Delta/Parquet files, such as Databricks delta lake, you can create shortcuts to these files or folders located in ADLS Gen 2 or Amazon S3. Consequently, the Fabric lakehouse would automatically register these shortcuts as tables.
Life is good in the managed area. Shortcuts to Delta/Parquet tables open interesting possibilities for data virtualization, such as:
Your users can use the Lakehouse SQL Analytics endpoint to join tables using SQL. This is useful for ad-hoc analysis. Joins could also be useful so users can shape the data they need before importing it in Power BI Desktop as opposed to connecting to individual files and using Power Query to join the tables. Not only could this reduce the size of the ingested data, but it could also improve refresh performance.
Users can decide not to import the data at all but build semantic models in Direct Lake mode. This could be very useful to reduce latency or avoid caching large volumes of data.
Unmanaged Area
Very few organizations would have lakes with Delta Parquet files. Most data lakes contain heterogeneous files, such as text, Excel, or regular Parquet files. While a Fabric lakehouse can create shortcuts to any file, non Delta/Parquet shortcuts will go to the unmanaged area (Files folder).
Life is miserable in the unmanaged area. None of the cool stuff you see in demos happens here because the analytical endpoint and direct lake modes are not available. A weak case can still be made for data virtualization that shortcuts bring data readily available to where business users collaborate in Power BI: the Power BI workspace.
But what can the user do with these unmanaged shortcuts? Not much really. Power BI Desktop doesn’t even expose them when you connect to the lakehouse. Power BI dataflows Gen2 do give the user access to the Files folder so potentially users can create dataflows and transform data from these files.
Of course, the tradeoff here is that you are adding dependencies to OneLake which could be a problem should one day you decide to part ways. Another issue could be that you are layering Power BI security on top of your data lake security.
Oh yes, users can also load Parquet and CSV files to Delta tables by right-clicking a folder or a file in the Unmanaged area, and then selecting Load to Tables (New or Existing). Unfortunately, as it stands, this is a manual process that must be repeated when the source data changes.
Imagined Unmanaged Data Virtualization
This brings me to the two things that I believe Microsoft can do to greatly increase the value proposition of “unmanaged” data virtualization:
Extend load to table to the most popular file formats, such as JSON, XML, and Excel. Or, at least the ones that Polybase has been supporting for years. Not sure why we have to obsess with Delta Parquet and nothing else if Microsoft is serious about data virtualization.
Implement automatic synchronization to update the corresponding Delta table when the source file changes.
If these features are added, throwing Fabric to the mix could become more appealing.
In summary, Microsoft Fabric has embraced Delta Parquet as its native storage file format and has added various features that targets it. Unfortunately none of these features extend to other file formats. You must evaluate pros and cons when adopting Fabric with existing data lakes. As it stands, Fabric probably wouldn’t add much business value for data virtualization over file formats other than Delta Paquet files. As Fabric matures, new scenarios might be feasible to justify Fabric integration and dependency.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-13 14:19:362024-03-20 12:55:54What Can Fabric Do For My Lake?
Rounding up the wisdom from the inscriptions of the Apollo Temple (see the Nothing in Excess and Know Thyself posts), the last known famous inscription was “Make a pledge and trouble is at hand.” Although the original intention was lost in time, it’s believed that this inscription instructs us to understand our limits so we don’t overpromise.
Fast forward to modern data analytics, I remember how Microsoft Power BI started less than 10 years ago with the grand promise to democratize BI to the masses. One would believe that AI would be an essential ingredient to fulfill that promise. To its credit, Power BI includes various built-in and useful ML features, such as Analyze Increase/Decrease (my favorite), Decomposition Tree, Key Influencers, Get Insights, and Q&A.
It’s surprising to me though that Fabric copilots are an ultra premium feature as they require at least P1 or its Fabric equivalent of F64 capacity with a price tag of $8,600 per month. As such, they will be an option only for large organizations that can afford this budget. Apparently, Microsoft sees copilots as the cherry on top of the Fabric pie that will commit undecided customers to premium spending. What happened to democratization and increased productivity? Domains of the rich?
I can’t try the Fabric copilots because they aren’t available even with Fabric Trial. But judging from the demos Microsoft provided, I’m not that impressed with them anyway. They all seem poor code generators on top of the Microsoft OpenAI service.
I remember how Q&A and natural interfaces were supposed to revolutionize data analytics. Now I don’t know of anyone using Q&A, but it can certainly produce exciting demos. As another footnote to Gartner-inspired grand visions, Fabric copilots will probably follow the same fate with a faster acceleration because of their hefty price tag.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-03-11 13:09:152024-03-12 14:17:35Make a Pledge and Trouble is at Hand: Microsoft AI and Fabric Copilots
The February 2024 release of Power BI Desktop includes a preview of visual calculations. As its name suggests, a visual calculation is a visual-scoped DAX measure that works at the aggregate (visual) level.
The Good
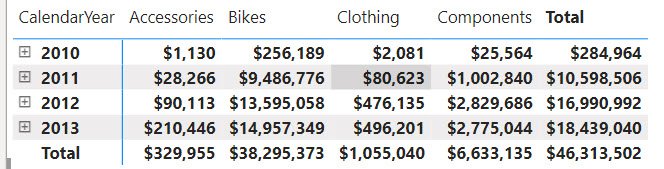
Visual calculations make previously difficult tasks much easier. Consider the following matrix:
Suppose you need a measure that calculates the difference between the product categories in the order they were sorted in the visual. Implementing this as a regular DAX measure is a challenge. Yet, if we had a way to work with the cells in the visual, we can easily find a way to get this to work. Ideally, this would work similar in Excel, but DAX doesn’t know about relative references. However, visual calculations do (kind of).
Let’s right-click on the visual and select “New calculation”. In the visual-level DAX formula bar, enter the following formula:
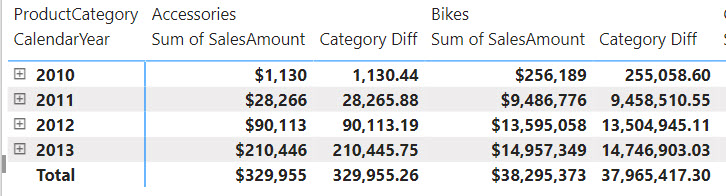
Category Diff = [Sum of SalesAmount] - PREVIOUS([Sum of SalesAmount], COLUMNS)
The Category Diff measure computes the difference between the current “cell” and the cell for the previous category. For example, for Bikes it will be $9,486,776-$28,266 (Accessories value).
Notice the use of the PREVIOUS function which is one the new DAX functions specifically designed for visual calculations. Notice also that the PREVIOUS function has additional arguments and one of them is the AXIS argument which specifies if the function should evaluate cells positionally on columns or rows. Finally, notice that visual-level formulas can only reference fields or measures placed in the visual.
The Bad
Among the various limitations, the following will cause some pain and suffering:
1. A visual calculation effectively disables exporting the visual data.
2. Drillthrough is disabled.
3. Can format visual calculations unless the visual supports it (the matrix visual does support measure formatting).
4. Can’t apply conditional formatting.
5. Can’t change sort order.
6. Can’t use field parameters.
The Ugly
The way Microsoft advertises this feature is that it is “easier than regular DAX”. My concern is that tempted by that promise, users will start abusing this feature left and right, such as for creating visual calculations that can be better implemented as regular DAX measures, e.g. for summing or averaging values. And not before long, such users would find themselves into an Excel-like spreadmart hell which is what they tried to avoid by embracing Power BI.
Therefore, please use these visual calculations only when regular DAX measures will not suffice. Business metrics should be centralized and should return consistent results, no matter the reporting tool or visual they are placed in. This is important for achieving the elusive single version of truth.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-28 17:16:162024-03-13 16:17:07A First Look at DAX Visual Calculations: the Good, the Bad, and the Ugly
Atlanta BI fans, please join us in person for the next meeting on Monday, March 4th at 6:30 PM ET. The famous Patrick LeBlanc (Guy in the Cube) will take a deep dive into the Microsoft Fabric ecosystem, from Lakehouse to Warehouses and Power BI, ensuring you can make informed decisions about your data processing needs. Your humble correspondent will help you catch up on Microsoft BI latest. CloudStaff.ai will sponsor the event. For more details and sign up, visit our group page.
Presentation: Navigating Microsoft Fabric – Choosing the Right Workload for Your Needs
Delivery: In-person
Date: March 4
Time: 18:30 – 20:30 ET
Level: Beginner/Intermediate
Food: Pizza and drinks
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Microsoft BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: As businesses transition to the cloud and leverage advanced analytics, understanding the nuances of data infrastructure becomes paramount. Microsoft Fabric offers a suite of powerful tools designed to handle various data workloads, but the key to harnessing its full potential lies in understanding which tool to use and when. This session provides a deep dive into the Microsoft Fabric ecosystem, from Lakehouse to Warehouses and Power BI, ensuring that participants can make informed decisions about their data processing needs. We’ll also look at current limitations that will help guide you.
Speaker: Patrick LeBlanc is a currently a Principal Program Manager at Microsoft and a contributing partner to Guy in a Cube. Along with his 15+ years’ experience in IT he holds a Master of Science degree from Louisiana State University. He is the author and co-author of five SQL Server books. Prior to joining Microsoft, he was awarded Microsoft MVP award for his contributions to the community. Patrick is a regular speaker at many SQL Server Conferences and Community events.
Sponsor: CloudStaff.ai
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-27 08:11:522024-02-27 08:11:52Atlanta Microsoft BI Group Meeting on March 4th (Navigating Microsoft Fabric – Choosing the Right Workload for Your Needs)
In my last post, I talked about the lessons learned from the ancient Greeks. The second inscription on the temple of Apollo in Delphi was “Nothing in Excess.” Yet, inspired to be modern and embracing vendor’s propaganda, it’s my experience that companies tend to overdo their data architectures. I talked about this in this newsletter. Another excellent resource that could help you strike a balance is the James Serra’s latest book “Deciphering Data Architectures.” I was privileged to know James Serra for a while, have him multiple times present to our Atlanta BI Group, and be an early reviewer of this book.
Besides consolidating the wealth of information from his excellent blog, James took a vendor-neutral approach to various patterns. Each pattern describes the architecture followed by pros and cons analysis.
After all, the right architecture and “best practice” is what works for you given your specific circumstances and restrictions. Nothing more, nothing less. And you’ll still be “modern”, whatever that means.
How do I personally avoid excess in my data architectures? By keeping them simple. Although there are exceptions when it makes sense, the general tenants for most implementations are:
Stage only the data I need instead of staging all source tables. Yes, this requires joining tables at the source, which is what the relational databases are designed to do (usually that’s the source).
If the data is hosted in relational databases, stage directly to the cloud data warehouse and bypass intermittent staging to a lake. In general, I hate working with files.
If the data is provided as files, such as reference data or source data downloaded or uploaded as files, stage it to a data lake.
Avoid REST APIs of cloud vendors like the plague unless there is no other way.
Do incremental data extraction when necessary (e.g. above a few million rows) and possible.
Embrace the ELT pattern.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-09 17:22:082024-02-14 16:51:40Nothing in Excess: Deciphering Data Architectures by James Serra
Last year my wife and I did a tour of Greece, and we had a blast. Greece, of course, is the place to go if you are interested in ancient history and the origin of democracy. One of the places we visited was Delphi. The ancient Greeks believed it to be the center of the universe. Now not much was left of it except lots of ruins and imagination. But back then it was magnificent. People from all over the world would come to consult with the Oracle of Delphi. She delivered her prophecies from the temple of Apollo, which had three inscriptions, with one of them being “Know thyself”. The practical benefit for the oracle was that if you believed her cryptic prophecy wasn’t fulfilled then your interpretation was wrong. Therefore, the problem was in you because you didn’t know yourself.
How does this translate into BI? I see clients overly excited about Microsoft Fabric/Power BI Premium, believing that bundling features will solve all their issues. But knowing your organization, ask yourself if your users would use all these features to justify the premium price. A case in point: Power BI source control via workspace Git integration: a feature that appear to be created from developers for developers. Kristyna Hughes did a great presentation for our Atlanta BI Group on Monday covering how developers can take the most of this feature.
Given the self-service focus of Power BI, however, I doubt that data analysts would subject themselves to learning Azure DevOps, Visual Studio Code, and Git CI/CD. Yet, Power BI source control has been in demand since the beginning with the most common ask – the ability to roll back changes.
Here is my take to simplify Power BI source control for regular users:
Power BI Premium/PPU/Fabric clients
If you are on Power BI Premium, set up a branch for each workspace that you want to put under source control, and configure the workspaces for Git integration.
Let business users publish changes as usual.
Periodically and as a part of the change management process, the workspace admin approves the changes and commits them to source control. I hope one day Power BI would transparently commit changes to Git as Azure Data Factory does it, without requiring explicit synchronization. Meanwhile, the admin must manually commit.
Someone privileged to Azure DevOps would need to roll back changes if needed. Again, I hope one day history review, compare, and roll back will be baked in Power BI.
Power BI Pro clients
Once this feature is generally available, embrace Power BI Desktop projects.
When significant changes are made, back up report and model.bim json files to some location, such as OneDrive which has built-in version control.
Replace the project files when you need to roll back changes. Again, this “poor man” source control emphasizes simplicity and saves premium licenses.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-02-08 14:40:172024-02-08 14:40:17Know Thyself: Power BI Source Control
Atlanta BI fans, please join us for the next meeting on Monday, February 5th at 6:30 PM ET. Note that this will be an online meeting via MS Teams and non-Atlanta BI fans are also welcome. Kristyna Hughes (Senior Consultant with 3Cloud) will show us how to implement source control for Power BI reports. Your humble correspondent will help you catch up on Microsoft BI latest. For more details and sign up, visit our group page.
Presentation: Power BI – Time to Git CI/CD
Delivery: Online
Date: February 5
Time: 18:30 – 20:30 ET
Level: Intermediate
Food: NA
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Microsoft BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Overview: As report developers, requirements for reports are constantly evolving which leads the reports themselves to change. However, inevitably, there will be one party who uses that report and was unaware of changes. They may request a list of changes or want that report rolled back to a previous version. With git, we can provide a list of changes and roll back to any version requested.
Taking a page from application developers, Power BI developers can now develop reports in branches and merge changes using git and Azure DevOps! If half those words are new to you and you’re looking for a better way to manage version history, come to this session! We will go through the basics of git including what branches are, how to use them, and some best practices while working with git. Git has a few tricks that we will go through as well like fetching a branch, in-line comparisons, and pulling to avoid merge conflicts. Don’t worry, we will also touch on how to resolve merge conflicts as well as how to avoid them. After the basics of git, we’ll walk through how to use git with Power BI workspaces and Azure DevOps.
Speaker: Kristyna Hughes is a senior data & analytics consultant at 3Cloud. Her experience includes implementing and managing enterprise-level Power BI instance, training teams on reporting best practices, and building templates for scalable analytics. Passionate about participating and growing the data community, she enjoys co-writing on Data on Wheels (dataonwheels.com) and has co-founded Data on Rails (dataonrailsblog.com). She also is a co-organizer for Lexington Data Technology Group and co-host of Wednesday Lunch & Learns on YouTube with Chris Wagner.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-01-29 13:22:112024-01-29 13:23:19Atlanta Microsoft BI Group Meeting on February 5th (Power BI – Time to Git CI/CD)
Last year around this time, I went to Antarctica on an expedition ship. Although I got my fair share of icebergs, whales, and penguins, I found it interesting to reproduce some of the experience of the first explorers. On our way back, we got it pretty rough crossing the Drake passage. 80% of the passengers succumbed to sea sickness. There was a huge swell during the night. The next day the captain told us that we faced some 10-meter waves. It felt like a bad roller coaster ride. Yet, the explorers did it. On wooden ships with no stabilizers and communication. Not knowing where they were going and with a high probability that they won’t survive!
What does this have to do BI? The remote connection is that 20 years ago a small group from Microsoft was set up to create a new reporting tool that was code-named “Rosetta” and later became known as SQL Server Reporting Services (SSRS). They took a brave new approach and soon SSRS wiped out the established reporting tools, and together with Analysis Services and SQL Server, became one of the pillars of Microsoft BI. SSRS open new possibilities and certainly changed my career. Kudos to the SSRS team and human spirit!
Atlanta BI fans, please join us for the next meeting on Monday, January 8th, at 6:30 PM ET. Eric Flamm will review paginated (SSRS) reports in Power BI. Your humble correspondent will help you catch up on Microsoft BI latest. For more details and sign up, visit our group page.
Presentation: Getting Started with Power BI Paginated Reports
Delivery: In-person
Date: January 9
Time: 18:30 – 20:30 ET
Level: Beginner
Food: TBD
Agenda:
18:15-18:30 Registration and networking
18:30-19:00 Organizer and sponsor time (events, Power BI latest, sponsor marketing)
19:00-20:15 Main presentation
20:15-20:30 Q&A
Venue
Improving Office
11675 Rainwater Dr
Suite #100
Alpharetta, GA 30009
Overview: Power BI Paginated Reports are the successor to SQL Server Reporting Services reports (although SSRS is still part of the SQL Server BI Stack). Using the same RDL (report definition language) as SSRS, Power BI Paginated Reports enable report developers to create “pixel-perfect” reports with complete control over item placement, pagination, row and column grouping and subtotals, etc. In this demo-centric session, we’ll use Power BI Report Builder on the desktop to design reports using datasets from local sources as well as Azure databases. We’ll look at parameterization and custom expressions and publish our report to the Power BI service. If time permits, we’ll take a look at building paginated reports in the online service, a capability Microsoft released last year.
Speaker: Eric is an independent Business Intelligence consultant, serving a range of clients including service and manufacturing enterprises, startups, and non-profit organizations. His practice includes SQL Server-based projects as well as Excel, Office Automation, and the occasional Microsoft Access project. Eric works with the Atlanta PASS Chapter as the webmaster and has volunteered with SQL Saturday Atlanta since the first event (SQL Saturday #13). Recently, he has presented to SQL Saturday Atlanta, SQL Saturday Chicago, Atlanta Code Camp, the Atlanta Power BI chapter, and the Kennesaw (GA) Amazon Web Services Meetup group.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2024-01-02 13:24:012024-01-02 13:27:46Atlanta Microsoft BI Group Meeting on January 9th (Getting Started with Power BI Paginated Reports)