Power BI Embedded, Service Principals, and SSAS
Power BI Embedded supports two ways that your custom app can authenticate to Power BI using a trusted account: master account (the original option) and more recently service principle. Service principal authentication is preferred because it doesn’t require storing and using credentials of a Power BI Pro account. Configuring the service principal and embedding reports with imported data is easy. Not so much with embedding reports connected to on-prem Analysis Services models, mainly because of documentation gaps. Here are some notes you might find useful that I harvested from a recent engagement.
-
Unlike what the documentation states that only SSAS models with RLS requires it, you must grant the service principal ReadOverrideEffectiveIdentity permission. Otherwise, the service principal can’t delegate the user identity to the gateway. So, the gateway admin must call the Gateways – Add Datasource User API.
TIP: Don’t write code but use the documentation page to call the API (isn’t this nice!). Construct the body to look like this:
{
“identifier”: “3d9b93c6-7b6d-4801-a491-1738910904fd“,
“datasourceAccessRight”: “ReadOverrideEffectiveIdentity”,
“principalType”: “App”
}
What the API page doesn’t tell you is what you need to use for the identifier in the request body. Your first attempt might be to use ApplicationID, but you’ll get greeted with error ” DMTS_PrincipalsAreInvalidError”. Instead, you must use the object id (in Azure portal, go to the app registration, and then click the app name in the “Managed Application in local directory” property).
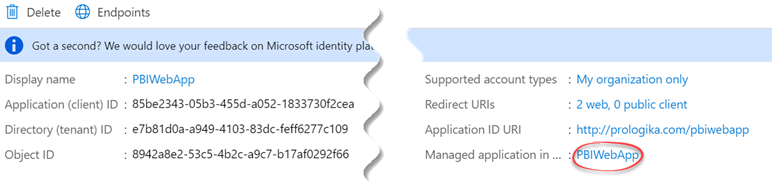
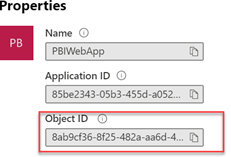
Then, on the next page, copy Object ID.
- Once the permission is granted, your custom app must construct an effective identity, such as by using this code. Notice you need to get to the report dataset to check how it’s configured. The GetDatasetByIdInGroup API requires the workspace identifier. The code assumes that the dataset is in the report’s workspace. If you need to embed reports connected to shared datasets which reside in other workspaces, you have a problem because the workspace id is not available in the report object. The best way your app can address this might be to maintain a reference map for these reports (reportId, workspaceId). I hope Microsoft changes the GetDatasetByIdInGroup to not require a workspace (not sure why is needed at all with guids).
- var dataset = client.Datasets.GetDatasetByIdInGroup(WorkspaceId, report.DatasetId);
- var IsEffectiveIdentityRequired = dataset.IsEffectiveIdentityRequired;
- var IsEffectiveIdentityRolesRequired = dataset.IsEffectiveIdentityRolesRequired;
- GenerateTokenRequest generateTokenRequestParameters = null;
- if (!(bool)IsEffectiveIdentityRequired)
- // reports with imported data that don’t require RLS
- {
- // Generate Embed Token for reports without effective identities.
- generateTokenRequestParameters = new GenerateTokenRequest(accessLevel: “view”);
- }
- else
- // reports connecting to RLS datasets and Analysis Services
- {
- var identity = new EffectiveIdentity(“<replace with the interactive user email, e.g. john@acme.com>”,
- new List<string> { report.DatasetId });
- var roles = “”; // if you want the user to evaluated as a member of a certain RLS role, replace with a comma-delimited list of roles
- if (!string.IsNullOrWhiteSpace(roles))
- {
- var rolesList = new List<string>();
- rolesList.AddRange(roles.Split(‘,’));
- identity.Roles = rolesList;
- }
- // Generate Embed Token with effective identities.
- generateTokenRequestParameters = new GenerateTokenRequest(accessLevel: “view”,
- identities: new List<EffectiveIdentity> { identity });
-
}
Notice that in line 16, your app must pass a valid Windows login to Analysis Services because behind the scenes the gateway will be append EffectiveUserName to the connection string.
 If “XMLA” doesn’t ring a bell especially in the context of Power BI, it stands for Extensible Markup Language for Analysis. Still puzzled? It’s the protocol of Analysis Services (Multidimensional and Tabular). So, when an Excel or Power BI sends a query to a cube, it’s encoded according the XMLA specification (an XML-based format). And, the XMLA endpoint is the web service endpoint that Analysis Services listens for upcoming requests.
If “XMLA” doesn’t ring a bell especially in the context of Power BI, it stands for Extensible Markup Language for Analysis. Still puzzled? It’s the protocol of Analysis Services (Multidimensional and Tabular). So, when an Excel or Power BI sends a query to a cube, it’s encoded according the XMLA specification (an XML-based format). And, the XMLA endpoint is the web service endpoint that Analysis Services listens for upcoming requests.