If you haven’t done so, watch the “Power BI and the Future for Modern and Enterprise BI” presentation from the Business Applications Summit (July 22-24) to find where Microsoft is bringing Power BI in the next few months.
Power BI Service Scale and Adoption
19M data models hosted
58M monthly publish to web views
8M+ report and dashboard queries/hour
Power BI a top 10 fastest growing skill according to Upwork
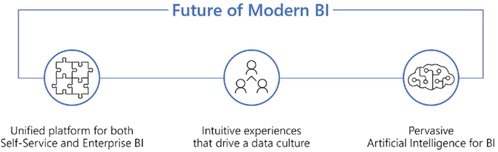
Microsoft will extend Power BI by investing in three main areas:
Unified platform for both self-service and enterprise BI
Intuitive experience that drive a data culture
Pervasive Artificial Intelligence for BI
Here are most important forthcoming near-future features across these three areas:
Unified platform for both self-service and enterprise BI
Make Power BI Desktop a better tool for larger models — new diagram view with perspectives, multi-select fields to set common properties (it’s about time to have this feature), display folders as in SSAS
Aggregations – Ability to define aggregations as we can do in SSAS MD. The demo showed an impressive response time for summarized views on top of a 1 trillion row dataset.
Dataflows – dataflows refer to what was announced as “datapools” and Common Data Model for Analytics (review my comments here).
Modernized Visualizations pane (delivered in July 2018 release)
Report wallpaper (delivered in July 2018 release)
Out of box themes
Visual headers (delivered in July 2018 release)
Snap visual with other visuals
Expression-based formatting for every property in the Visualizations pane – This is huge and my users would rejoice to have more control over report properties!
Excel-like pivot tables
Export to PDF – most voted feature will finally be delivered
Pervasive Artificial Intelligence for BI
Quick Insights on right-click
Natural questions with suggestions
Quick insights inside natural questions results
Integration with Python – Connector and custom visuals like R
Sentiment analysis
Integration with Microsoft Cognitive Services – The demo showed the model deducing that the images of air conditioners in a hotel are broken
Better integration with Azure Machine Learning Studio
An impressive list of features indeed!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-07-28 14:05:362021-02-17 01:02:03Power BI News from the Microsoft Business Applications Summit
The July 2018 preview of Power BI Desktop delivers two killer preview features that solidify the Power BI position as the best data modeling tool for personal BI on the market. First, Microsoft relaxes the Power BI relationship limitations by letting you create M:M joins between two tables. Second, you can now create a composite (hybrid) data model with different storage modes, such as from an SQL Server database configured for DirectQuery and from an imported text file. Without reiterating the documentation, here are some important notes to keep in mind based on my pre-release testing.
The Good
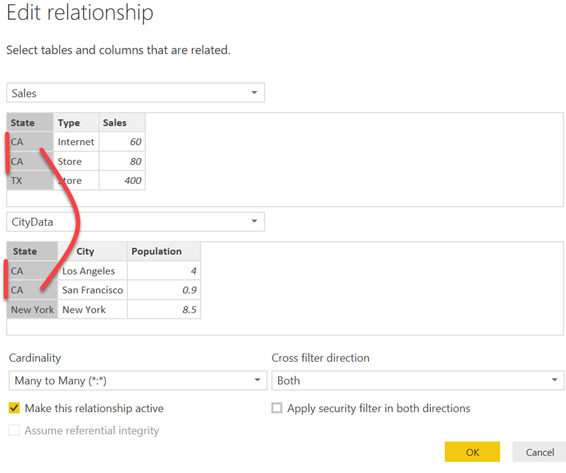
M:M relationships remove a limitation that Power BI had since its Power Pivot days which is that one of the tables (the dimension or lookup table) must have a primary key: a field that uniquely identifies every row in the table. Now you can create a M:M relationship without requiring a bridge table, such as between two fact tables, as the screenshot shows. In this case, the Sales[State]-CityData[State] relationship is M:M because CA appears multiple times in each table. Previously, if you have attempted to create this relationship you would get an error message that the State field on the one side of the relationship is not unique.
The new M:M feature paves the way for supporting more flexible schemas but bear in mind that other relationship limitations, such as redundant paths and close-loop relationship are still not allowed. It also doesn’t mean that you shouldn’t follow best data modeling practices, such as star schemas.
For example, Power BI would disallow an active M:M relationship between ResellerSales and InternetSales fact tables if they’re joined to the same (conformed) dimensions. That’s because as it stands Power BI still doesn’t have a user interface to prompt the end user which path to take so it deactivates the relationship when it discovers a conflict.
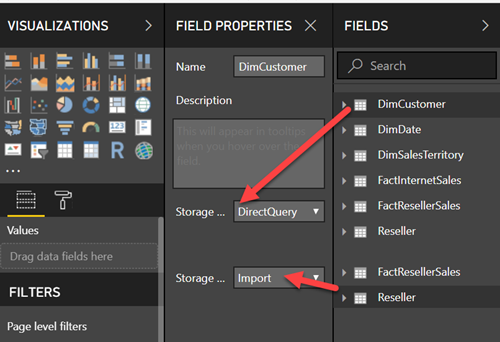
Perhaps, a more important enhancement is ability to create data models with mixed storage modes which are referred to as “composite” models. Just two weeks ago I taught a Power BI class and the client disappointed that they can’t join SAP HANA and SQL Server in DirectQuery mode within the same Power BI model. That’s because previously DirectQuery was limited to single database. Now you can!
Composite models enable the following data acquisition options:
Combine multiple databases from the same server in DirectQuery.
Combine multiple data sources configured for DirectQuery
Implement a hybrid storage model that combines a data source with imported data with another data source configured for DirectQuery.
Combine a DirectQuery table with imported table from the same data source, such in the case where you prefer most tables to be imported but some in DirectQuery for real-time analysis.
Of course, DirectQuery is a double-edge sword. It lets you avoid importing data and eliminate latency, but performance depends on the data source so be careful. Aggregations (slated for later this year) could mitigate DirectQuery performance issues by letting you summarize data at a higher level.
The Bad
DirectQuery limitations continue to exist, including:
Imported tables can’t be converted to DirectQuery and when attempting to do so, you’ll get an error “Imported tables can’t be converted to DirectQuery”. The reverse scenario, however, is supported. If the data source is DirectQuery, you can convert some tables to import data.
DirectQuery can’t return more than 1 million rows. This has been a long standing DirectQuery limitation (documented here). Consider a DimCustomer table (from same or different source) that joins FactSales configured for DirectQuery and you request a report that shows sales by customer. At a certain (undisclosed by Microsoft) point it becomes inefficient to send the entire customer list to the WHERE clause of the FactSales direct query. Instead, the query would group FactSales at the Customer field used for the join, and then locally aggregate the results. However, if that query exceeds 1 million, then this would result in the query failing.
Only a subset of data sources, such as popular relational databases and “fast” databases, support DirectQuery. I hope Microsoft extends DirectQuery to more data sources, such as Excel files and text files.
You can’t pass parameters to custom SQL SELECT statement or stored procedure, such as to pass the value that the user selects in a slicer to a stored procedure configured for DirectQuery.
Composite models add a new twist to relationships. When combining two data sources in DirectQuery (or mixed) storage mode, Power BI converts all joins between the two data sources to be of M:M cardinality, irrespective of the actual cardinalities involved. According to Microsoft, this design was due to implementation challenges and the need to preserve performance. Although this isn’t a big issue, semantically I’d prefer the join cardinality to reflect the data cardinality. For example, if I join a DimCustomer table from SQLServerA with FactResellerSales from SQLServerB, the join cardinality should be 1:M. However, it’s not possible to configure 1:M for heterogeneous joins. Consequently, it’s not possible to validate the data is indeed 1:M and the RELATED DAX function won’t work. Microsoft believes that the cardinalities of the two end points are unimportant, the key difference between this type of relationship and the existing relationships is that it only supports cross-filtering, but not other semantics like RELATED function and blank rows from RI violation.
The Ugly
Power BI has always supported three data acquisition options: Import, DirectQuery, and Live Connection (multidimensional data sources only). You might have noticed that when you connect Power BI Desktop to Analysis Services, you’d see that the Data tab and Relationship tab are not available. That’s because Power BI morphs into a presentation layer to AS and passes through DAX queries. Unfortunately, as I explained in my blog “Power BI Feature Discrepancies for Data Acquisition“, Power BI treats DirectQuery and Live Connection data sources as second-class citizens and disables certain features.
Back to composite models, regretfully they don’t apply to multidimensional models: Analysis Services (MD and Tabular), Power BI datasets, and SAP HANA. In other words, a single Power BI desktop file is still limited to connecting to a single multidimensional database. I hope that Microsoft lifts this limitation at some point because it’s not uncommon to create a self-service model that needs to combine data from an organizational semantic model in DirectQuery and some other data source (imported or DirectQuery).
Composite models and M:M relationships are important new enhancements that bring even more flexibility to the Power BI data architecture. M:M relationships allows you to support more flexible schemas. Although old and new limitations exist, composite models lets you implement models with mixed storage modes to enable interesting data integration scenarios.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-07-23 17:14:422018-07-30 22:34:33Power BI Composite Models: The Good, The Bad, The Ugly
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on Monday, July 30th at 6:30 PM at the Microsoft office in Alpharetta (our regular venue room is being renovated). If you haven’t been at the new MS office, prepare to be impressed! Scott Fairbanks from CCG will show you how to create a tailored user experience with Power BI. Your humble correspondentwill demonstrate Power BI killer features that will be announced at the Microsoft Business Applications Summit tomorrow. CCG will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the main page) if you’re planning to attend.
Presentation:
How to Create a Tailored End User Experience with Power BI
Level: Intermediate
Date:
July 30th, 2018
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900 Alpharetta, GA 30009
Overview:
Power BI can deliver value in a variety of ways. With its ease of use, high levels of adoption, and growing market share, Power BI is being integrated into Analytics Solutions all over the world. In this session, attendees will see the power in leveraging Workspaces and Apps within Power BI to create a packaged, custom solution tailored to meet the needs of the consumer. With the end user experience in mind, this session will discuss the development process, design considerations, and the Power BI Service deployment of a collection of customized dashboards in a single App.
Discussion Points Include:
• Power BI Desktop
• Power BI Service
• Workspaces
• Apps
• Visualizations
• Interactions
• Formatting
• Mobile View
• Row level security
• Publishing
• Consuming
Speaker:
Scott Fairbanks is a consultant that has been involved in Data and Analytics for 12+ years. Scott has always been interested in computing technology, and fell naturally into the role of helping others get value out of their analytics investment as a consultant with CCG. Over the course of his career, Scott has worked with many of the various BI product suites, including IBM’s Cognos, SAP’s Webi, and Tableau. In recent years, he has been swept up in the demands of the changing analytics environment and has been diving into the Microsoft Azure and Power BI space along with so many companies making the move to the cloud.
Sponsor:
CCG is an award-winning consulting firm with a passion for helping clients solve their operational and strategic challenges through innovative Business Intelligence (BI) services. We believe business intelligence is more than a technical solution; it’s an opportunity to create lasting cultural change across an organization. Our experts focus on quickly gaining a big-picture understanding of your business to develop optimized, tailored BI solutions that empower you to drive greater decision-making at the speed of your data.
Prototypes with Pizza
Power BI killer features in the July 2018 release.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-07-22 11:13:222021-02-17 01:01:56Atlanta MS BI and Power BI Group Meeting on July 30
Problem: A long standing limitation in Analysis Services Tabular and Power BI is the lack of default members, such as to default a Date dimension to the last date with data. Users find this annoying, especially for time calculations which require a date context and won’t produce results until you add a date-related field to the report one way or other. To aggravate things even more, Tabular switched to a JSON schema in SQL Server 2016. The new schema is great for expressing the metadata in clear and more compact way. However, because it’s not extensiible, it precludes community tools, such as BIDS Helper (now called BI Developer Extensions) and DAX Editor, to extend Tabular features and fill in the gaps left by Microsoft.
Workaround: Currently, there is no way to default a field in Tabular and Power BI. For the most common requirement to default a date filter, consider adding a field to the Date table that flags the desired item. You can implement this in different ways. For example, in Excel you can create a named set, but this requires MDX knowledge that end users won’t have. And it won’t work in other report clients, such as Power BI Desktop. Here is an approach that is simple to implement and works everywhere.
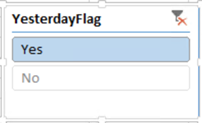
Flag the desired item using whatever way you’re comfortable with: SQL view, Power Query, or DAX. For example, if users prefer the date filter to default to yesterday and the Date table is based on a SQL view, add the following column to the view: CASE WHEN [Date] <= DATEADD(DAY,-1, CAST(GETDATE() AS DATE)) THEN ‘Yes’ ELSE ‘No’ END YesterdayFlag Notice that the flag qualifies all rows prior to and including yesterday. In your first attempt, you might try only an equal condition. This will work when the YesterdayFlag field is added as a filter to an Excel pivot table. However, if you attempt to configure it as an Excel slicer, it will result in the following error: Calculation error in measure ‘<your measure name>’: Function ‘SAMEPERIODLASTYEAR’ only works with contiguous date selections.
Reimport the Date table in Tabular or Power BI.
Set up a report filter. For example, in Excel define a slicer using the YesterdayFlag field and default it to Yes, if you want to filter all reports on the same sheet.
The net effect is that as time progresses, the YesterdayFlag field will filter the Date table and measures will show the yesterday’s data by default. Time calculations will also work as of yesterday. For example, YTD calculations will aggregate from the beginning of the year until yesterday. And end users don’t need to bother about resetting date filters if viewing data as yesterday is the prevailing preference.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-07-18 21:20:292018-07-20 14:01:57Implementing a Default Date Filter in Tabular and Power BI
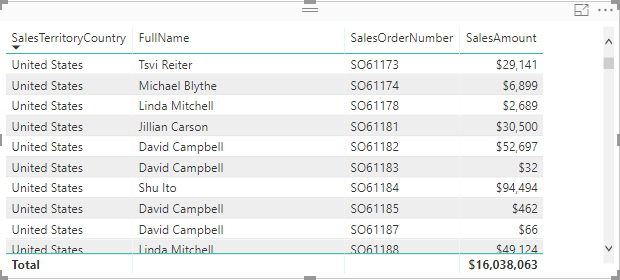
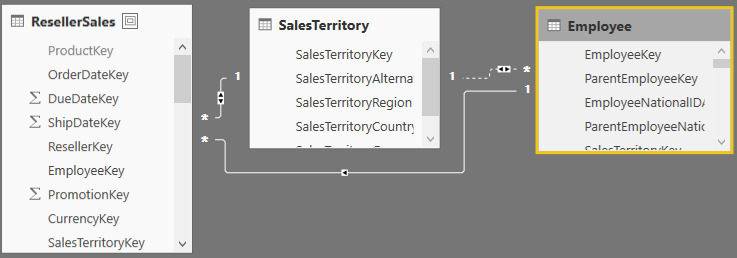
Problem: Consider the following Power BI report that shows the sum of ResellerSales[SalesAmount] by SalesTerritory[SalesTerritoryCountry], Employee[FullName], and ResellerSales[SalesOrderNumber].
This report is based on the following schema consisting of three tables.
However, If there isn’t a direct relationship between ResellerSales and Employee, the moment you add an unsummarized field from the second table on the many side, such as Employee[FullName] after adding SalesTerritoryCountry and ResellerSales[SalesOrderNumber), you’ll get the error “Error: Can’t determine relationships between the fields”.
Solution: Interestingly, the report works fine if a summarized field, such as COUNT(Employee[EmployeeKey]) is used. In this case, the SalesTerritory dimension acts as a conformed dimension joined to two fact tables. The reason why it doesn’t work when Employee[FullName] is added is because there is no aggregation on the Employee table and the relationship between ResellerSales[SalesOrderNumber] and Employee[FullName] becomes Many:Many over SalesTerritory which is now a bridge table. One employee may be associated with multiple sales and a sale can be associated with multiple employees. How do we solve this horrible problem? There are at least two ways:
If possible, create a direct relationship between ResellerSales and Employee. Now you have two dimensions joining a fact table and there is no ambiguity.
If the only join option is to relate Employee to SalesTerritory, set the relationship’s cross filter direction to Both. This will indirectly filter the ResellerSales table and might achieve the same result. For each employee on the report, Power BI travels the relationship to find the related territories at the lowest granularity. In Adventure Works, the lowest granularity of the SalesTerritory table is the territory region, such as South East, so the cross filter set to Both will select all regions that are associated to the current employee. From there, it will get the sales orders and sales associated with these regions.
Where the report using the second option differs from the first is if there are multiple employees associated with the same region causing the sales order numbers to repeat although the report total is the same.
Power BI supports flexible schemas but how you construct relationships may impact the report results. You should always start with a simple schema and grow in complexity if needed.
Got awarded for Microsoft Most Valuable Professional (MVP) – Data Platform again. This will make my 15th consecutive year to be recognized by Microsoft for my expertise and contributions to the community! Learn more about the MVP program at https://mvp.microsoft.com/en-us/Overview.
A large company uses the SAP HANA ERP system. Users requires real-time access to transactional data. To avoid performance degradation, SLT replication (trigger-based change data capture) replicates data to another SAP HANA system that is used solely for reporting. The problem is that the more detailed the report gets and the more columns it has, the slower it gets and SAP HANA throws out of memory exceptions.
SAP HANA is an in-memory columnar database like Tabular. So, it stores data in columns, not rows. Columnar databases are primarily designed for analytical reports which typically have a few columns (sales by customer, product, date), but can potentially aggregate large datasets. As the reporting grain lowers and more columns are added (order number, order line item, customer name, phone number, etc.), a columnar database has to cross-join more and more columns. This is not efficient and performance quickly degrades irrespective that storage is fast. SSAS Tabular and Power BI are no different. SAP HANA complicates the issue further by preventing direct access to tables and requiring “analytical” views that join tables and potentially nest other views.
So, what’s the solution? Use the right tool for the job. A relational database is designed to transactional reports and it’s very efficient for joining tables together on indexed columns. In this case, performance and user satisfaction would probably be much better if SAP HANA replicates to an SQL Server database instead to a columnar database. Use columnar databases for analytical reports. Every technology has limits and “super-fast” in-memory columnar databases are no exception. Resist the vendor propaganda.
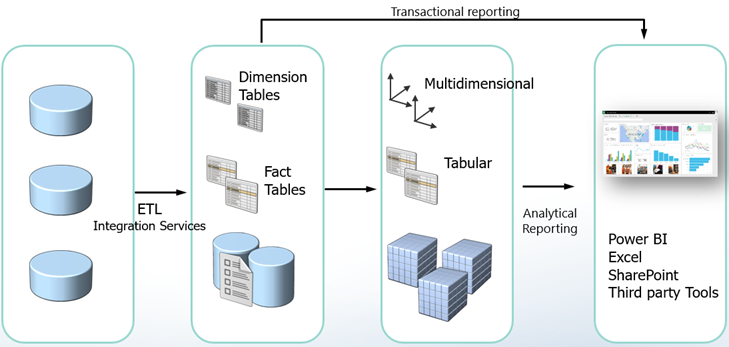
BI and data integration projects often benefit from an operational data source (ODS), whose benefits and design I discussed in my “Designing an Operational Data Store (ODS)” newsletter. A corporate ODS typically fall into the organizational BI area, which means that it’s implemented and sanctioned by IT. Wouldn’t be nice to let Business stage the data needed for business applications and analytics? Of course, it would! Think of the Microsoft Common Data Services as a cloud staging database or ODS by Business and for Business. But before I discuss the details, makes sure to review our Terms of Use, which has been updated as part of our commitment to transparency and to address the requirements set forth by the new European privacy law (General Data Protection Regulation). By continuing to use the Prologika website and its online services, you consent that you have read, understand and accept the terms of the Prologika Privacy Policy. If you have any questions regarding our updated Privacy Policy, please contact us by writing to info@prologika.com.
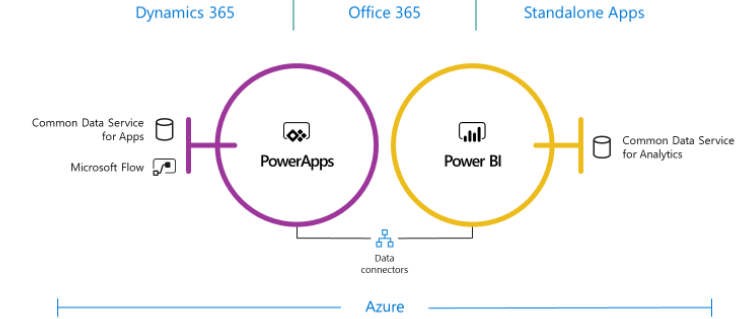
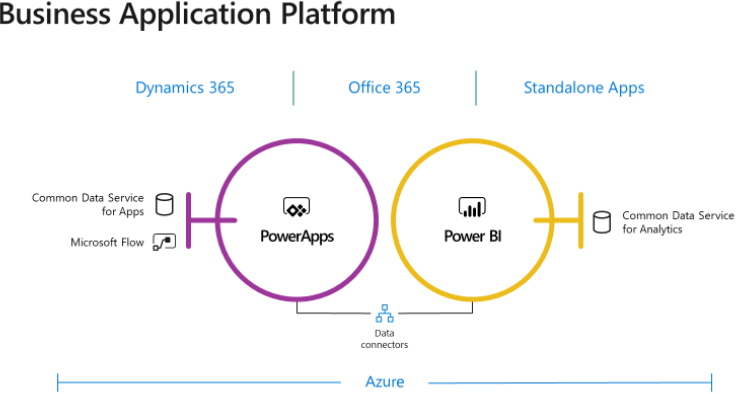
What’s Common Data Services?
Microsoft introduced Common Data Services were introduced as a part of the reimagined Business Application Platform as a “one connected platform that empowers everyone to innovate” and to put all the data you need into a standardized data model. Common Data Services consists of two offerings: Common Data Service for Apps (CDS for Apps) and Common Data Service for Analytics (CDS for Analytics).
Why two flavors? Think of the Microsoft Common Data Service for Apps (CDS for Apps) as a cloud OLTP-like repository by Business and for Business. Officially introduced in 2016 and running on Azure SQL Database, CDS for Apps is now the entity and data model behind Dynamics 365. This is where Dynamics 365 stores its data. Because it’s transaction-oriented, it’s layered on top of SQL Server. By contrast, Common Data Service for Analytics (CDS for Analytics) is oriented towards supporting analytical requirements.
How Do They Compare?
The following table compares the two CDS types.
CDS for Apps
CDS for Analytics
Primary usage
OLTP
OLAP
Primary tool for loading data
PowerApps/Power Query
Power Query
Primary tool for reading data
PowerApps/Power BI
Power BI
Data storage
Azure SQL Database
Azure Blob Storage (a CSV text file per entity and a JSON file for the schema)
Both CDS types support standardized entities, whose definitions are documented in the GitHub repository of the Common Data Model. Currently, the schema of these entities is designed and controlled by Microsoft and it’s limited to Dynamics entities, such as Account, Opportunity, and so on. However, Microsoft hopes that other vendors will provide solutions and extend the CDS schema. Of course, because CDS is your database, you can extend it with your own custom entities. Note that both CDS types target business users willing to store and analyze data in a business-friendly staging database. Over time Microsoft hopes that partners will deliver more value to CDS by implementing apps (CDS apps are like the prepacked apps that already exist in Power BI, such as for Salesforce and Dynamics). Let’s now highlight some of the differences of the two CDS flavors.
Common Data Service for Apps
The main usage scenario for CDS for Apps is to jumpstart the development of PowerApps applications with a standardized data model that you can extend to your own needs.
The Good
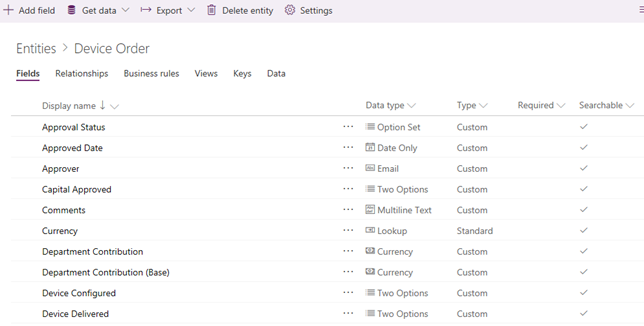
There is a lot to like about CDS for Apps. Let’s start with pricing. Other vendors, such as Oracle and Teradata, have similar visions and products but their offerings are very expensive. The CDS for Apps pricing is included in the PowerApps licensing model because PowerApps is the primary client for creating CDS for Apps-centered solutions. Using CDS outside selected Dynamics 365 plans (that include it already) will cost you at least $7 per user and per month. CDS for Apps is more than just a data repository. It’s a business application platform with a collection of data, business rules, processes, plugins and more. In this regard, it resembles SQL Server Master Data Services (MDS). The modeler can:
Define and change entities, fields, relationships, and constraints. For example, the screenshot shows a custom Device Order entity that I’ve created.
Business rules, such as to prepopulate Ship Date based on Order Date.
Secure data to ensure that users can see it only if you grant them access. Role-based security allows you to control access to entities for different users within your organization
Besides the original PowerApps canvas apps (like InfoPath forms), CDS for Apps also opens the possibility to create model-driven PowerApps applications (require PowerApps P2 plan). Model-driven apps are somewhat like creating Access data forms but more versatile. Because PowerApps knows CDS for Apps, you can create the app bottom-up, i.e. start with CDS for Apps and then generate the app based on the actual schema and data. For example, you can use PowerApps to build a model-driven app for implementing the workflow for approving a certain process. Model-driven apps are a new style of a PowerApps application that makes it easy to build entity forms, entity views, and workflows. How do you get data into CDS for Apps custom entities? Your PowerApps app can write to it. Or, you can create and schedule a project that uses Power Query (yep, the same one as in Power BI) to load data from somewhere into CDS for Apps.
The Bad
How do you get data out from CDS for App, such as to import data from some entities into a Power BI model? Microsoft has released a preview build of the Common Data Service for Apps connector for Power BI. However, this connector is even slower that the Dynamics connector. It uses the OData v4 Web API. Based on my limited tests, it took the connector about a minute to download 40,000 rows from Dynamics, clocking 10% slower than the Dynamics connector. To make things worse, the connector doesn’t support query folding, so Power BI must download the entire dataset before Power Query applies filters. Because the connector doesn’t support also REST filter and select predicates, so you can’t filter data or select a subset of columns at the source. Microsoft is actively working on improving the connector performance and it might get better in time.
Continuing down the list of limitations, CDS for Apps doesn’t support change tracking (to capture changes to a given row) and incremental loads, such as to load or refresh only the data that has changed yesterday or previous month. These are all essential features that could make ODS even more valuable.
The Ugly
For years people were complaining that after migrating from the on-premises Dynamics to the cloud, they lost the ability to connect to its database directly and they had to rely on the REST APIs (slow) or Data Export Service to export the data to an SQL Server Database (fast but requires additional effort and budget). Unfortunately, although CDS for Apps stores data in Azure SQL Database, Microsoft doesn’t expose its database directly to get data out fast and bypass the REST endpoint. When I raised this issue to Microsoft I got feedback that CDS for Apps is a business platform and there are layers on top of data to handle security, rules, calculations, and so on. However, the argument that CDS for Apps is more than just a database is nonsensical to me. Try to explain to a customer that cakes have layers and CDS for Apps has layers, and therefore getting something out of it is slow. As I mentioned, the “layered nature” of the CDS is conceptually like MDS. In fact, I see a lot of overlap. MDS also supports rules, security, etc. but it doesn’t force me to go through the web service interface if all I need is the raw data. Hence, my wish to support direct connectivity to the Azure SQL Database endpoint of CDS for Apps.
Common Data Service for Analytics
CDS for Analytics is a standard feature of Power BI so every Power BI Pro user can access it. CDS for Analytics is exposed to the end user in Power BI as datapools. A datapool is a collection of entities associated with a Power BI app workspace. An entity maps to a text file in Azure Storage. Business users will rely on Power Query to populate (manually or via a scheduled refresh) entities in CDS for Analytics. You can access the workspace datapool in the workspace content page
The Good
I can think of three primary scenarios where CDS for Apps can deliver value as it stands today:
Offline data staging – Let’s say IT doesn’t allow direct connectivity to LOB applications but you need to create some reports on top of this data. You can stage the data as text files into CDS for Analytics. I don’t think CDS for Analtyics would bring much value if you could connect directly to it in Power BI Desktop if direct connectivity is an option. The more you move the data, the more problems you may run into. At least for now, having apps on top of text files doesn’t look like a good reason to me but I guess we have to see what apps will become available in time.
Prepackaged third-party solutions – Sometime ago, a software vendor asked me how they can deploy a solution to Power BI for their customers but still retain ownership. Back then I didn’t have a good answer but CDS for Apps might be a good option now. In fact, besides the Power Query as a primary tool for loading entities, any service that can write to Azure Storage can bring data to CDS for Analytics. The ISV can write the entities as CSV files and tell CDS Analytics to “mount” the storage container. CDS Analytics can now see these mounted entities and treat them as part of the whole. Worried about protecting intellectual property? Currently only the Insight App installer would have access to the installed workspace and artifacts (other users in the organization would just see the published reports which are shared with them).
Prepackaged insights – Like CDS for Apps, CDS for Analytics understands the Common Data Model. Over time, Microsoft and partners can contribute prepackaged “insights” that are built on top of popular LOB apps, such as Dynamics or Salesforce.
Pricing is also right. CDS for Analytics is included in Power BI although it storage counts towards the workspace quota. Another thing I like about CDS for Analytics is that the Power BI connector is very fast unlike the CDS for Apps connector.
The Bad
As of now datapools support only a small subset of the Power Query connectors. This is probably just a temporary limitation for the preview cycle. I’d imagine that all Power BI connectors for cloud and on-premises data sources will be eventually available. Continuing on the list of limitations, like CDS for Apps, CDS for Analytics doesn’t support incremental refreshes so be careful downloading millions for rows every night.
The Ugly
CDS for Analytics promises to break silos but a datapool is associated with a Power BI workspace. This architecture fragments CDS for Analytics into Power BI workspaces. However, most users would probably require access to common entities, such as Customer, Product. Not only this is not possible but the datapool storage is also limited by the workspace quota. So, if you are a Power BI Pro user who has access to an app workspace, you’re currently limited to 10 GB storage quota which includes not only Power BI datasets but also CDS entities. I wish that CDS has no association to workspaces and it was designed a global staging area, just like Azure Storage. Microsoft has promised at some point in future to allow you to reference entities between datapools in different workspaces and create calculated entities on top of them.
The success of Common Data Services for Apps will depend largely on adoption and contributions by Microsoft partners. Although it lacks typical ODS features and fast connectivity, CDS for Apps gains in “business platform” features. CDS for Analytics and Power BI Insights are new additions to Power BI. CDS for Analytics delivers Operational Data Store (ODS) to business users that is populated and maintained by business users. Microsoft and partners can augment CDS for Analytics with Power BI Insights apps.
Teo Lachev Prologika, LLC | Making Sense of Data Microsoft Partner | Gold Data Analytics
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on Monday, June 25th at 6:30 PM. Your humble correspondentwill share 10 ways Power BI can help augment your existing or envisioned Power BI strategy. DevScopewill sponsor the meeting and demo their PowerBI Robots offering. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the main page) if you’re planning to attend.
Presentation:
10 Ways to Empower Your BI Strategy with Power BI
Level: Intermediate
Date:
June 25, 2018
Time
6:30 – 8:30 PM ET
Place:
South Terraces Building (Auditorium Room)
115 Perimeter Center Place
Atlanta, GA 30346
Overview:
Not sure what value Power BI can bring to your BI infrastructure? Join me to discuss 10 ways Power BI can help augment your existing or envisioned Power BI strategy. If you’re interested in the Power BI but you’re not sure how it fits within your organizational data strategy, this event is for you. Discussion points include:
• Organizational BI
• Self-service BI
• Cloud vs. on-premises deployments
• Predictive analytics
• External reporting
• Integrated solutions
Get your Power BI questions answered and see demos along the way.
Speaker:
Teo Lachev is a consultant, author, and mentor, with a focus on Microsoft Business Intelligence. Through his Atlanta-based company “Prologika” (a Microsoft Gold Partner in Data Analytics) he designs and implements innovative BI solutions that bring tremendous value to his clients. Teo has authored and co-authored several SQL Server BI books, and he has been leading the Atlanta Microsoft BI and Power BI group since he founded it in 2010. Microsoft has recognized Teo’s expertise and contributions to the technical community by awarding him the prestigious Microsoft Most Valuable Professional (MVP) status since 2004.
Sponsor:
DevScope is a young, dynamic and experienced company, specialized in mentoring and development services in Web environments, and a pioneer in the region, integrating Microsoft technology, products and solutions. DevScope implements business and technology solutions with established and emerging technologies every day. DevScope projects are usually based on the latest technologies available from Microsoft, and many times, those same technologies are not yet available in the market.
Prototypes with Pizza
DevScope Power BI Robots by Rui Romano, DevScope
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-06-19 14:12:462021-02-17 01:01:55Atlanta MS BI and Power BI Group Meeting on June 25
UPDATE 11/15/2018: Common Data Service for Analytics is superseded by Power BI dataflows. Find the updated review here.
In a previous blog I discussed the Common Data Service for Apps (CDS for Apps). I explained that CDS for Apps is more suitable for OLTP-type applications, which is why its main client is PowerApps apps saving data in normalized tables. Since good things shouldn’t come alone, Microsoft is readying another CDS flavor, Common Data Service for Analytics (CDS for Analytics), which is oriented towards supporting analytical requirements. Microsoft provided a good introduction to CDS for Analytics in the “Common Data Service for Analytics (CDS-A) and Power BI – an Introduction” video and “Introduction to Common Data Service For Analytics” video. Without rehashing what has been already announced and said, I’d like to share a few notes from what I’ve learned so far.
The following table compares the two CDS types.
CDS for Apps
CDS for Analytics
Primary usage
OLTP
OLAP
Primary tool for loading data
PowerApps/Power Query
Power Query
Primary tool for reading data
PowerApps/Power BI
Power BI
Data storage
Azure SQL Database
Azure Blob Storage (a CSV text file per entity and a JSON file for the schema)
Note that both CDS types target business users willing to store and analyze data in a business-friendly staging database. Over time Microsoft hopes that partners will deliver more value to CDS by implementing apps (CDS apps are like the prepacked apps that already exist in Power BI, such as for Salesforce and Dynamics).
In fact, apps are so important for the success of CDS that Microsoft listed the CDS for Analytics-powered apps, dubbed Power BI Insights, as another product in the Power BI portfolio.
CDS for Analytics is a standard feature of Power BI so every Power BI Pro user can access it. CDS for Analytics is exposed to the end user in Power BI as datapools. A datapool is a collection of entities associated with a Power BI app workspace. An entity maps to a text file in Azure Storage. Business users will rely on Power Query to populate (manually or via a scheduled refresh) entities in CDS for Analytics. You can access the workspace datapool in the workspace content page.
The Good
I can think of three primary scenarios where CDS for Apps can deliver value as it stands today:
Offline data staging – Let’s say IT doesn’t allow direct connectivity to LOB applications but you need to create some reports on top of this data. You can stage the data as text files into CDS for Analytics. I don’t think CDS for Analtyics would bring much value if you could connect directly to it in Power BI Desktop if direct connectivity is an option. The more you move the data, the more problems you may run into. At least for now, having apps on top of text files doesn’t look like a good reason to me but I guess we have to see what apps will become available in time.
Prepackaged third-party solutions – Sometime ago, a software vendor asked me how they can deploy a solution to Power BI for their customers but still retain ownership. Back then I didn’t have a good answer but CDS for Apps might be a good option now. In fact, besides the Power Query as a primary tool for loading entities, any service that can write to Azure Storage can bring data to CDS for Analytics. The ISV can write the entities as CSV files and tell CDS Analytics to “mount” the storage container. CDS Analytics can now see these mounted entities and treat them as part of the whole. Worried about protecting intellectual property? Currently only the Insight App installer would have access to the installed workspace and artifacts (other users in the organization would just see the published reports which are shared with them).
Prepackaged insights – Like CDS for Apps, CDS for Analytics understands the Common Data Model. Over time, Microsoft and partners can contribute prepackaged “insights” that are built on top of popular LOB apps, such as Dynamics or Salesforce.
Pricing is also right. CDS for Analytics is included in Power BI although it storage counts towards the workspace quota. Another thing I like about CDS for Analytics is that the Power BI connector is very fast unlike the CDS for Apps connector.
The Bad
As of now datapools support only a small subset of the Power Query connectors. This is probably just a temporary limitation for the preview cycle. I’d imagine that all Power BI connectors for cloud and on-premises data sources will be eventually available. Continuing on the list of limitations, like CDS for Apps, CDS for Analytics doesn’t support incremental refreshes so be careful downloading millions for rows every night.
The Ugly
CDS for Analytics promises to break silos but a datapool is associated with a Power BI workspace. This architecture fragments CDS for Analytics into Power BI workspaces. However, most users would probably require access to common entities, such as Customer, Product. Not only this is not possible but the datapool storage is also limited by the workspace quota. So, if you are a Power BI Pro user who has access to an app workspace, you’re currently limited to 10 GB storage quota which includes not only Power BI datasets but also CDS entities. I wish that CDS has no association to workspaces and it was designed a global staging area, just like Azure Storage. Microsoft has promised at some point in future to allow you to reference entities between datapools in different workspaces and create calculated entities on top of them.
CDS for Analytics and Power BI Insights are new additions to Power BI. CDS for Analytics delivers Operational Data Store (ODS) to business users that is populated and maintained by business users. Microsoft and partners can augment CDS for Analytics with Power BI Insights apps.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-06-14 08:00:412018-11-16 21:47:11Common Data Service for Analytics: The Good, the Bad, the Ugly


 BI and data integration projects often benefit from an operational data source (ODS), whose benefits and design I discussed in my “
BI and data integration projects often benefit from an operational data source (ODS), whose benefits and design I discussed in my “