Understanding AAS Synchronization
None of the Multidimensional and Tabular semantic models I’ve implemented required scaling out, but I understand that some scenarios might benefit from it, such as B2B or B2C reporting. Depends on the implementation approach, another benefit could be implementing a highly available farm. Implementing a scaled-out, on-premises SSAS farm is not easy. There are different techniques but all of them involve a compromise between availability and latency. Azure Analysis Services sought to make this easier. It’s as easy as changing a slider and AAS synchronizes everything somehow, right? Wrong. Here are the high-level notes of how AAS synchronization works:
- As a part of configuring synchronization, you can specify a designated processing node. If you do specify a processing node, processing takes place on that node only and the updated cache is distributed to the query nodes. If you don’t specify a processing node, one of the query nodes handles both processing and querying. The node that handles processing is referred to as a primary node.
- AAS synchronization is not automatic. You’re responsible to initiate the synchronization step, either manually from the Azure portal or automated by using Sync-AzureAnalysisServicesInstance from PowerShell, or using the REST API for Azure AS. This means that every time you process the model, you’d need to use one of these mechanisms to sync the model with the query nodes.
- When the sync command is initiated, AAS copies the entire AS database from the primary node to blob storage. That’s because the primary (read/write) node is on a different copy than the query nodes so that it can be updated without effecting end-user queries. The file copy happens inside the blob storage (no network traffic is involved). Additional details about the file copy process:
- Multi-threaded (unlike the SSAS sync wizard)
- Hydrates multiple replicas from a single data folder
- The data folder is striped for better I/O
- Once the updated database (all files) are copied to the blob storage, the query nodes detach the old copy and attach to the new one.
- AAS waits until the model is fully loaded into memory and available for queries before making the copy (replica) online.
How fast is the sync process? We measured with a 50 GB database and it took 20 minutes for the sync process to complete. I guess most time was spent in the last step. So, as it stands, AAS synchronization is more suitable for predictable processing windows, such as in the “classic” case where ETL processes and synchronizes the model once per day, outside working hours. It might not work well for real-time solutions, where new data might arrive throughout the day and business requirements call for minimum latency because you might not have enough time for the file copy to complete.
Another gotcha that we ran into was that there seems to be an issue with the metrics reporting and a scale-out farm. During load testing we saw that the average QPU of a two-node farm (S4 performance tier with max QPU of 400) showed saturation at 200 average QPU. It looks like the Azure portal collects 400 from each node and then divides by the number of nodes. We raised the issue to Microsoft and probably it will addressed soon.
Scaling out is not about reducing query times. It’s about handling more load when scaling up doesn’t go enough. When you scale out to a two-node farm, you’re still limited by the resource constraints (memory, CPU) of each node. Unless you are after a highly available BI solution, scaling out should be your last option. Time spent in optimizing your model design, data storage, and queries is usually much more productive than taking the easy way out and throwing more hardware (and money).
This blog explained how AAS synchronization works. I hope Microsoft will offer more options in future to make it more useful. A welcome enhancement would be the ability to configure an automatic and less granular synchronization, such as to copy only the files that have changed.






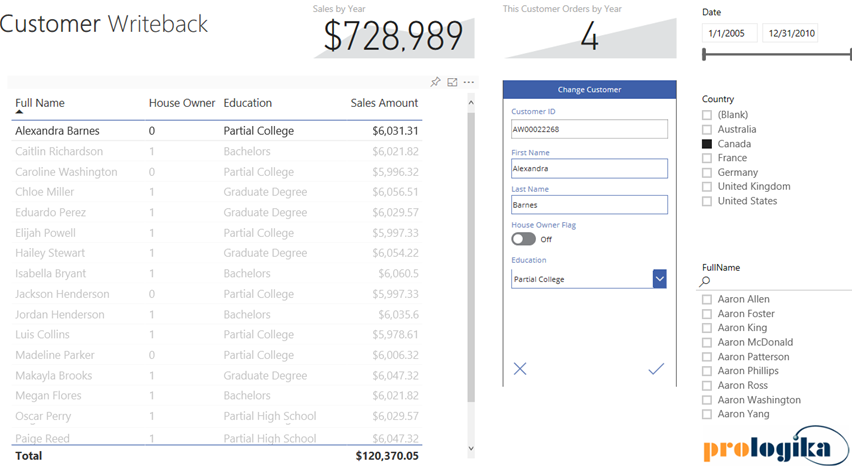
 With hundreds of vendors out there, choosing a BI tool isn’t easy. If you’ve been following me for a while, you know that I love Power BI. One of the Power BI most prominent strengths is that it’s a part of the much broader Microsoft Data Platform that spans various on-premises and cloud offerings for data storage, processing, and analysis. Thanks to this integration, you can implement real-time dashboards, extend your Power BI reports with predictive capabilities, integrate with Big Data, and much more. In this newsletter, I’ll talk about an exciting integration option: extending Power BI with business applications, thanks to its integration with PowerApps and Flow. And if you happen to be in the Microsoft office in Alpharetta, feel free to ask for a demo of the Power BI Writeback that Prologika prepared and deployed to the Microsoft environment. You’ll be directed to one of the big screens when you can test the report that I mention in this newsletter.
With hundreds of vendors out there, choosing a BI tool isn’t easy. If you’ve been following me for a while, you know that I love Power BI. One of the Power BI most prominent strengths is that it’s a part of the much broader Microsoft Data Platform that spans various on-premises and cloud offerings for data storage, processing, and analysis. Thanks to this integration, you can implement real-time dashboards, extend your Power BI reports with predictive capabilities, integrate with Big Data, and much more. In this newsletter, I’ll talk about an exciting integration option: extending Power BI with business applications, thanks to its integration with PowerApps and Flow. And if you happen to be in the Microsoft office in Alpharetta, feel free to ask for a demo of the Power BI Writeback that Prologika prepared and deployed to the Microsoft environment. You’ll be directed to one of the big screens when you can test the report that I mention in this newsletter.