Testing RLS with Power BI Shared Datasets
In a typical engagement, I create an organizational semantic model(s) and “report packs”, such as Sales Report Pack, Inventory Report Pack, etc. These report packs are typically implemented as Power BI reports connected to the semantic model as a shared dataset using the Power BI Datasets connector. Reports sanctioned by IT are published to a dedicated workspace, such as Corporate BI. Departmental reports are deployed to their respective workspace, such as Sales, to enforce content-level security. Usually, the semantic model has row-level security (RLS) roles defined to enforce restricted access to data depending on the identity of the interactive user.
Although not immediately obvious, here is how you can test RLS to ensure that connected reports produce expected results under someone else’s identity directly in Power BI Service:
- In powerbi.com, go to the workspace where the shared dataset is published.
- In the dataset page, click the Datasets tab, and then click the ellipsis button (…) next to the shared dataset. In the dataset Settings, click Security.
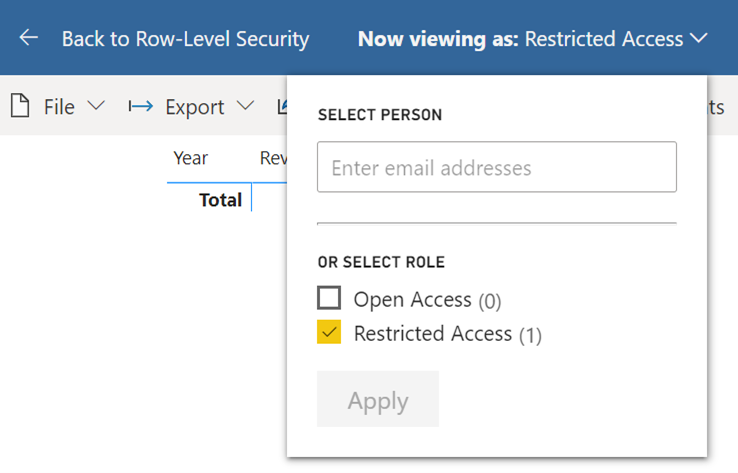
- Expand the … button next to the Restricted Access role, and then click “Test as role”. This will open whatever report is included in the shared dataset pbix file (I typically have some reports there for testing).
- You can expand the Restricted Access dropdown and enter the user email of the user whose RLS permissions you want to test or the role you want to apply. In the screenshot below, I’m testing under my identity applying the rules in the Restricted Access role. If I wanted to test what a specific user would see, I’d type in that user’s email.

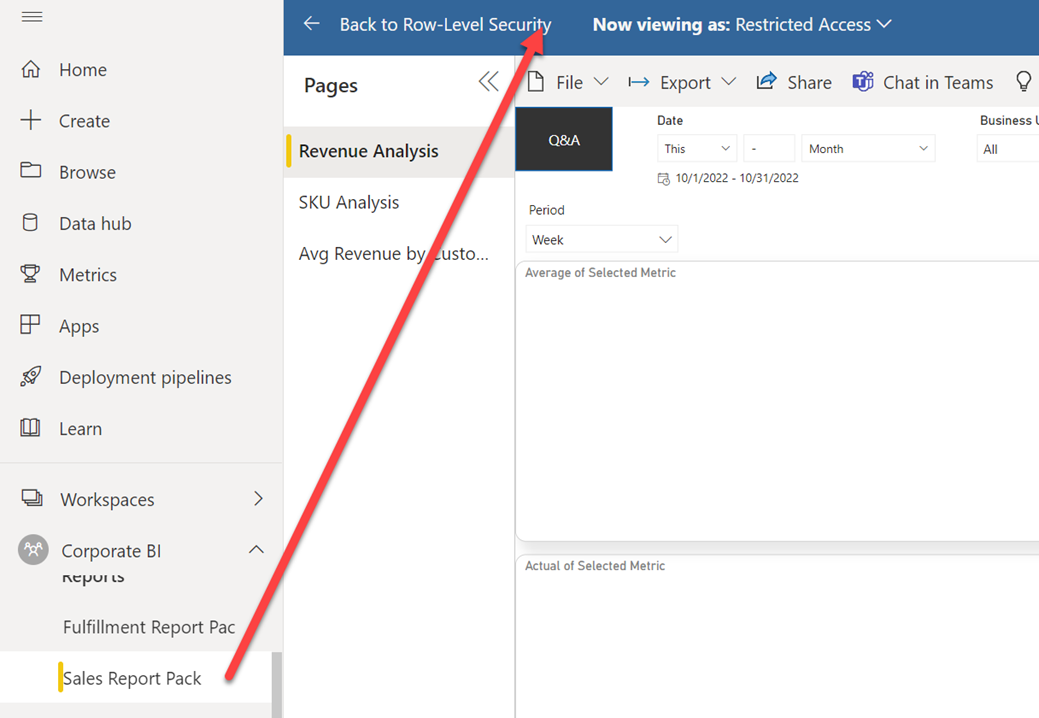
- To test other reports for this user, expand the powerbi.com left-navigation pane and then click the desired report. Power BI will navigate you to that report, but it will honor RLS.