2019 Gartner Magic Quadrant for Analytics and Business Intelligence Platforms
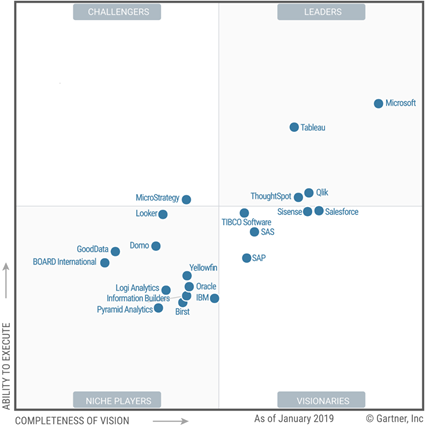
The 2019 Gartner Quadrant for Analytics and BI Platforms is out and Microsoft BI aficionados like your humble correspondent have all the reasons to rejoice. Say whatever you want about Gartner but the quadrant is a great testimonial for Power BI and I think the highest score was overdue. Microsoft still has tons of work on the visualization side of things but I’m glad that Gartner recognized the business value of Power BI which exceeds by far any other BI tool on the market. A few comments on the cautions in the report:
- Differences in on-premises and cloud service with Azure cloud only – This is about the discrepancies between Power BI and Power BI Report Server which I discussed last year. Revisiting this, I’d like to know how many customers have complained. In my practice, I don’t see much interest in Power BI Report Server for deploying Power BI reports as everyone wants to be in the cloud.
- Integration of Mode 1 and Mode 2 – This is the same “caution” as last year which is already covered by the first caution so I’m not sure why it’s reiterated. “With Power BI, Microsoft has mainly focused on requirements for Mode 2 (agile, self-service) analytics. On-premises SQL Server Reporting Services meets the needs of Mode 1”. I think Gartner will be happy once the SSRS integration is fully baked in Power BI Premium.
- Multiple products – Kind of repeated from last year by phrased somewhat differently “Although the core of Power BI is a self-contained product, Microsoft’s roadmap spans multiple products.” So, the same comment. I don’t see a problem with having multiple products if they can integrate. Especially given that some are free, such as PowerApps and Flow with O365. The reason why they are separate products is that they don’t apply to BI only. And which BI vendor has flow, business apps, predictive models, in the same product? Not to mention that other vendors don’t have anything more than just a reporting tool.
Perhaps, the next most difficult thing after getting to the top is remaining on the top. Will Microsoft sustain the Power BI leader position or gradual attrition and shifting priorities will let smaller and more agile vendors dethrone it?