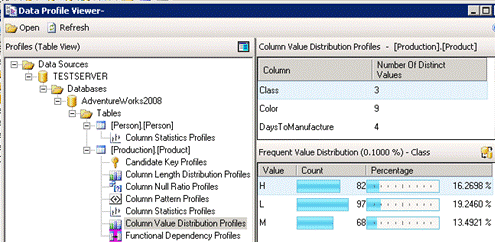
You know it and I know it. Data quality is a BIG problem that reduces the business value of BI. ETL practitioners will probably recall that SSIS includes a comprehensive Data Profiling Task but it is somewhat difficult to set up, especially if you wanted to profile multiple tables. It saves the results in an xml file and then you could use the Data Profile Viewer to visualize the results.
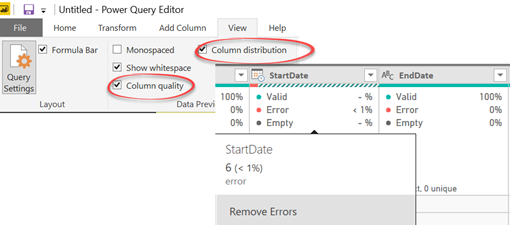
Can we do something like this in Power BI? Starting with Power BI Desktop (October 2018) release you can. Well, sort of. Once you enable the column profiling preview feature, open the query behind any table and enable these options in the View ribbon.
You’ll get basic statistics showing the percentages of Valid, Error, and Empty values out of the sample size (the first 1,000 values). Here are definitions of these categories:
Valid – Non-Error and Non-Empty values out of the sample size
Error – Values with errors
Empty – Empty values
Below you get a column chart (not shown in the screenshot) that shows the distribution of the sample size, but unfortunately it doesn’t show the actual values. That’s all data profiling you get for now. Here is what it will take to make Power BI data profiling a killer feature:
Allow data profiling over all the values (understandably there will be performance impact).
Add more aggregates, such as Min/Max/Std/Median.
The ability to dynamically filter the preview data for the selected bar in the profile.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-10-15 22:12:442018-10-15 22:14:45Power BI Data Profiling
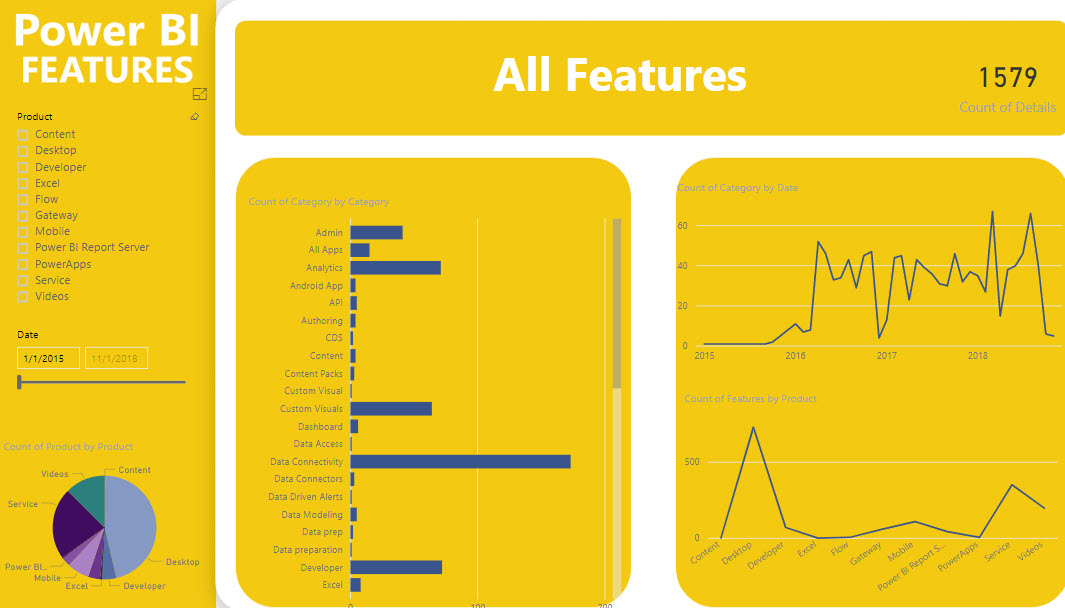
Want to know what Power BI features were released in a certain time period? Check out the Power BI Features report. After some delay, you should see the report embedded on the page but please be patient. If no patience, you can also download the pbix file from the same page. Then, use the slicer on the first page to filter your date range. In the “Count of Category” bar chart, right-click the category and then click See Records to see to the actual features. Once you drill through the category, there is a link next to each feature that redirects you to the corresponding blog to learn more.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-09-26 13:42:192018-09-26 13:52:42Power BI Features Report
Semantics relates to discovering the meaning of the message behind the words. In the context of data and BI, semantics represents the user’s perspective of data: how the end user views the data to derive knowledge from it. A modeler translates the machine-friendly database structures and terminology into a user-friendly semantic model that describes the business problems to be solved. To address this need, you create a semantic model. In my “Why Semantic Layer?” newsletter I explained the advantages of an organizational semantic model. In this newsletter, I’ll discuss how Power BI extends semantic modeling and converges it on a single platform. But before I go into details and speaking of semantic models, I’m excited to announce the availability of my new “Applied DAX with Power BI” workshop and its first in-person and public enrollment class on Oct 15-16 in Atlanta! Space is limited so RSVP today.
Semantic Model Flavors
In Microsoft BI, you can implement a semantic model using Power BI Desktop, Excel (Power Pivot) and Analysis Services (Multidimensional and Tabular). The first two are typically used by data analysts, while Analysis Services is considered a professional technology. Thus, we can classify semantic models into two broad categories: personal (self-service) and organizational. Behind the scenes, Power BI Desktop, Power Pivot and Analysis Services Tabular use the same foundation and storage engine. Nevertheless, up to now there have been feature differences and a strict division between these two types.
Personal
Organizational
Author
Data analyst
BI Pro
Tool
Power BI Desktop, Excel (Power Pivot)
SSDT and Analysis Services
Scope
Narrow (usually to solve specific need)
Wide (multiple subject areas)
Implementation effort
Short
Longer (data warehouse, ETL, model, testing)
Data capacity
Limited (up to a few million rows)
Larger (millions or billions of rows)
Data quality
Trust author
Trust modeler and testers
Data centralization
May lead to data duplication
Single version of truth
Deployment
Power BI Service, Power BI Report Server
SSAS (on premises)
Azure Analysis Services (cloud)
Consumers
Department, project
Potentially entire organization
How Power BI Changes Semantic Modeling
Power BI will blur the boundary between the personal and organizational aspects of semantic modeling. First, we’ve already seen how Microsoft introduced the following “pro” features in Power BI that don’t even exist or more difficult to implement with Analysis Services:
Incremental refresh – Delivers the ability to refresh portions of a larger dataset, such as the last 7 days. Currently, the largest dataset size supported by Power BI Premium is 10 GB, but Microsoft has already announced that soon Power BI will support larger datasets. What this means for you is that you’d be able to deploy organizational semantic models to Power BI Premium and schedule them for incremental refresh. My blog “Notes on Power BI Incremental Refresh” provides the details on this feature.
Composite semantic models – A composite model has heterogenous storage, such as some tables are imported and some are DirectQuery, as I discussed in my blog “Power BI Composite Models: The Good, The Bad, The Ugly“. This brings a lot of flexibility to how you connect to data.
Aggregations – Aggregations are predefined data summaries to speed up queries with very large models. My blog “A First Look at Power BI Aggregations” covers Power BI aggregations.
On the tooling side of things, Power BI Desktop will also pick “pro” features, such as perspectives and displays folders. Microsoft hopes that in time Power BI Desktop will serve the needs of both data analysts and BI pros. However, the lack of extensibility and source control, as well as performance issues caused by committing every model change to the background Analysis Services instance, makes me skeptical that pros will embrace Power BI Desktop. But because Microsoft announced plans to open the Power BI Tabular management endpoint (recall that published Power BI datasets are hosted in a “hidden” Tabular server), pros can still use SSDT and community tools, such as Tabular Editor, to design and deploy their models to Power BI Premium.
In time Power BI Premium will become a single cloud platform for hosting Microsoft BI artifacts (semantic models and reports) and facilitating the continuum from personal to organizational BI. This is a great news for BI practitioners frustrated by tooling and deployment differences. At the end, the personal and organizational paths will converge without feature discrepancies. The only difference would be the scope of your organizational model and how for you want it to become “organizational”.
Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
As Microsoft announced in the “Distribute insights across the organization with Microsoft Power BI” presentation (forward to the Nikhil Gaekwad part starting at the 32 min), they’ve been releasing the following set of features to improve the end user experience in Power BI Service:
Home (not yet available) – Personalized landing page
Personal bookmarks (not yet available) – End users can create their own bookmarks
Persistent filters (already available) – Remembers filters and slicers set by end users
Conversations (dashboards conversations are available) – Dashboard and report discussions
Sharing with filters (not yet available) – Propagates the current filters when sharing individual reports and dashboards
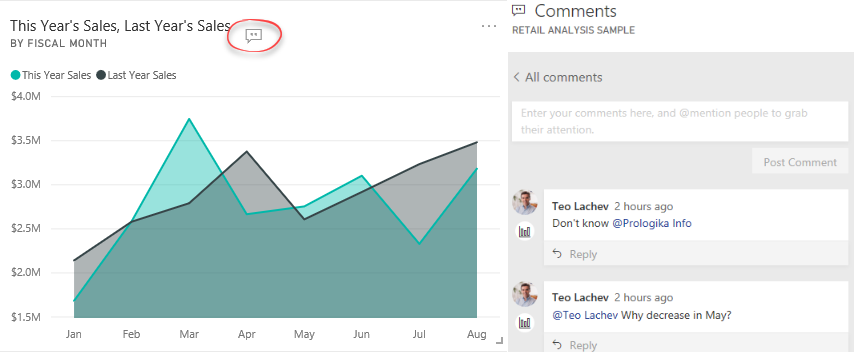
I’ve noticed that the dashboard conversations are now available. Just open a Power BI dashboard and click the Comments menu. This will open a Comments pane when you can post comments related to the entire dashboard. You can also post comments for a specific tile by clicking the tile ellipsis menu and then choosing “Add a comment”. You know that a tile has comments when you see the “Show tile conversations” button that floats on the tile. Clicking this button brings to the Comments pane to see and participate in the discussion.
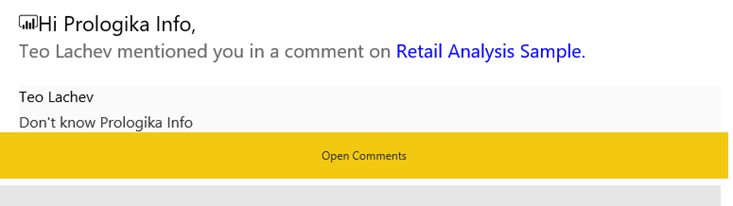
For tile-related comments, you can click the icon below the person in the Comments pane, to navigate to the specific visual that comments are associated with. Conversations are available in Power BI Service and Power BI Mobile. To avoid posting a comment and waiting someone to see it to act on it, you can @mention people as you can do on Twitter. For example, in my first comment I referenced @Prologika Info. Then that user will get an email that looks like this:
Collaboration features are not new to Power BI. Workspaces backed by O365 groups (the old-style workspaces) have supported email-based conversations. Power BI Mobile lets users annotate reports or tiles with text and emotions, and then send a screenshot to another user. Dashboard and report conversations bring collaboration a step further by allowing end users to collaborate in the context of a specific report, dashboard, or even a visual.
Usage scenario
Limitations
Workspace conversations
Workspace-level email-based collaboration
The workspace needs to be backed by O365 group.
Power BI Mobile annotations
Send annotated screenshots to other users
Power BI Mobile only; no discussion thread
Dashboard and report conversations
Discussion thread on dashboard/report/tile
Comments don’t save the state of the visual or include a screenshot of the visual if it changes after data refresh
Question: What’s the maximum dataset size Power BI can support?
Answer: As of now (Sep 1, 2018), the maximum dataset size that Power BI Pro can support is 1 GB. The maximum dataset size with Power BI Premium and Power BI Embedded is 10 GB but it depends on the SKU purchased.
Power BI Premium Plan
Power BI Embedded Plan
Max Dataset Size and Memory
P1
A1
3 GB
P2
A2
5 GB
P3 and higher
A3 or higher
10 GB
The important point is “as of now”, as with everything cloud these limits will probably get higher soon. Also, recall that Power BI compresses data well so don’t jump to conclusions of how many rows a dataset can pack if you base the estimate solely on the dataset original size. For example, a 100 MB Excel file might compress to 10 megabytes.
The limits apply to datasets after compression. So, if the file size fits the limit, Power BI will let you upload it. But what happens if the dataset size increases after the dataset memory footprint expands or if it continues to expand on refresh? For example, a 10 GB pbix file might translate to a much larger memory footprint once loaded up (due to abf compression, dictionary expansion, assorted data structures, etc.). So, even if the dataset is loaded is loaded up, there will not be enough memory to do anything useful with it like run queries, do refresh, etc. because all the physical memory is used up. So there are also limits based on the actual memory used. The documentation refers to some extra memory that Power BI grants the dataset to allow future expansion to a point, such as up to 12 GB for a 10 GB dataset.
A Power BI training or assessment won’t be complete unless I get hammered on the Power BI sharing limitations. So far, I could only mumble something to the extent of “I agree that Power BI sharing sucks big time”, look for the exit and suggest an unplanned break. Fortunately, it looks like quantitative accumulations from unhappy corporate customers have resulted in qualitative changes as Microsoft is getting serious about addressing these limitations. To me, as it stands today, the Power BI sharing is a classic example of overengineering. Something that could have been easily solved with the conventional and simple folders a la SSRS, morphed into some farfetched “cool” vision of workspaces and apps without much practical value. Let’s revisit the current Power BI sharing limitations to understand why change was due:
Workspace dependency on Office 365 groups – This results in explosion of workspaces as Power BI is not the only app that creates groups.
Any Power BI Pro user can create a workspace – IT can’t put boundaries. I know of an organization that resorted to an automated script that nukes workspaces which aren’t on the approved list.
You can’t add security groups as members – As I discussed in my blog “Power BI Group Security“, different Power BI features have a different degree of support for groups. For example, workspaces didn’t support AD security groups.
Coarse content access level – A workspace could be configured for “edit” or “view only” at the workspace level only. Consequently, it wasn’t possible to grant some members view access while others edit permissions.
(UPDATE 6/9/2019: A dataset can now be shared across workspaces) Content sharing limitations – Content can’t be copied from one workspace to another. Worse yet, content can’t be reused among workspaces. For example, if Teo deploys a self-service semantic model to the Sales workspace, reports must be saved in the same workspace.
No nesting support – Workspace can’t be nested, such as to have a global Sales workspace that breaks down in to Sales North America, Sales Europe, etc. Again, this is a fundamental requirement that any server-side reporting tool supports but not Power BI. You can’t organize content hierarchically and there is no security inheritance. Consequently, you must resort to a flattened list of workspaces.
(UPDATE 6/9/2019: A dataset can now be promoted and certified). No IT oversight – There is no mechanism for IT to certify workspace content, such as a dataset. There is no mechanism for users to discover workspace content.
UPDATE 6/27: The new Viewer role supports sharing with viewers. Sharing with “viewers” – You can’t just add Power BI Free users to share content in a premium workspace. This would have been too simple. Instead, you must share content out either using individual report/dashboard sharing or apps.
One-to-one relationship with apps – Since broader sharing requires apps (why?), an app needs to be created (yet another sharing layer) to share out workspace content. But you can’t publish multiple apps from a workspace, such as to share some reports with one group of users and another set with a different group.
Enough limitations? Fortunately, the new workspace experience immediately solves the first four (highlighted) issues!
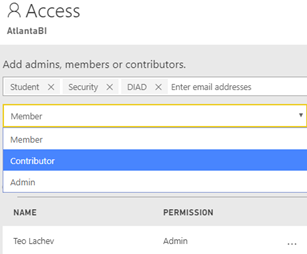
For example, the screenshot below shows how I can add all the O365 group types as members of a workspace (Student is individual member, Security is a security group, and DIAD is a O365 group). Moreover, two new roles, Contributor and Viewer (the Viewer role is not yet available), would further limit the member permissions. So, we finally have member-level security instead of workspace-level security.
What about the other limitations? Microsoft promises to fix them all, but it will take a few more months. Meanwhile, watch the “Distribute insights across the organization with Microsoft Power BI” presentation. So, hopefully by the end of the year I’ll have a much better sharing story to tell after all.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-08-26 16:06:582021-02-17 01:02:04Power BI Sharing Is Getting Better
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on Monday, August 28th, Tuesday at 6:30 PM at the Microsoft office in Alpharetta (our regular venue room is being renovated). If you haven’t been at the new MS office, prepare to be impressed! Mark Tabladillo, Ph.D, from Microsoft will show you how to advanced analytics with Power BI. Accelebrate will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (use the RSVP survey on the main page) if you’re planning to attend.
Presentation:
Advanced Analytics with Power BI
Date:
August 28, 2018, Tuesday
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
Power BI has become an increasingly important data analytics tool. This presentation focuses on the advanced analytics options currently available in Power BI. Attendees to this talk will see:
· Microsoft’s perspective on advanced analytics development: the Team Data Science Process
· What the general options are for advanced analytics on Azure
· What the specific native advanced analytics capabilities are in Power BI
· Some ideas on pairing Power BI with other technologies in advanced analytics architectures
Mark Tabladillo Ph.D. is a data scientist at Microsoft. His career has focused on industry application of advanced analytics, using a variety of analytics tools including SAS, SQL Server Analysis Services, Cortana Intelligence (including Microsoft R Server and Microsoft Machine Learning Services), R, and Python. He was a founding member of the Atlanta Microsoft BI User’s Group eight years ago, and this group’s second presenter.
Sponsor:
Don’t settle for “one size fits all” training. Choose Accelebrate, and receive hands-on, engaging training precisely tailored to your goals and audience! Our on-site training offerings range from ASP.NET training and SharePoint training to courses on ColdFusion, Java™, C#, VB.NET, SQL Server, and more.
Prototypes with Pizza
Featured Power BI enhancements
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-08-23 08:12:502021-02-17 01:01:56Atlanta MS BI and Power BI Group Meeting on August 28
During the “Building a data model to support 1 trillion rows of data and more with Microsoft Power BI Premium” presentation at the Business Applications Summit, Microsoft discussed the technical details of how the forthcoming “Aggregations” feature can help you implement fast summarized queries on top of huge datasets. Following incremental refresh and composite models, aggregations are the next “pro” feature that debuts in Power BI and it aims to make it a more attractive option for deploying organizational semantic models. In this blog, I summarize my initial observations of this feature which should be available for preview in the September release of Power BI.
Aggregations are not a new concept to BI practitioners tackling large datasets. Ask a DBA what’s the next course of action after all tricks are exhausted to speed up massive queries and his answer would be summarized tables. That’s what aggregations are: predefined summaries of data, aimed to speed queries at the expense of more storage. BI pros would recall that Analysis Services Multidimensional (MD) has supported aggregations for a long time. Once you define an aggregation, MD maintains it automatically. When you process the partition, MD rebuilds the partition aggregations. An MD aggregation is tied to the source partition and it summarizes all measures in the partition. You might also recall that designing proper aggregations in MD isn’t easy and that the MD intra-dependencies could cause some grief, such as processing a dimension could invalidate the aggregations in the related partitions, requiring you to reprocess their indexes to restore aggregations. On the other hand, as it stands today, Analysis Services Tabular (Azure AS and SSAS Tabular) doesn’t support aggregations. Power BI takes the middle road. Like MD, Power BI would search for suitable aggregations to answer summarized queries, but it requires more work on your part to set them up.
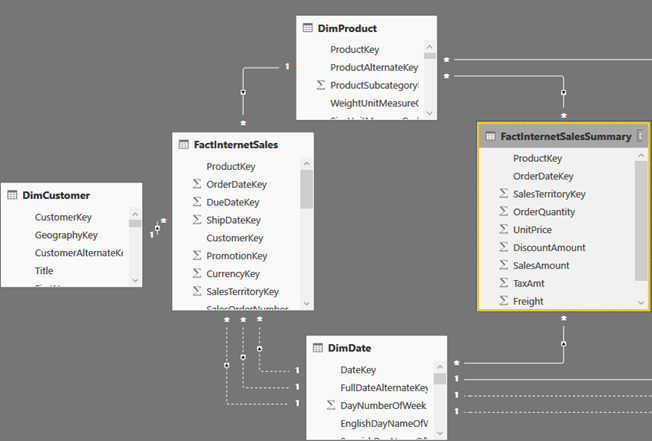
Consider the following model which has a FactInternetSales fact table and three dimensions: DimCustomer, DimProduct, and DimDate. Suppose that most queries would request data at the Product and Date levels (not Customer) but such queries don’t give you the desired performance. This could be perhaps because FactinternetSales is imported (cached) but it’s huge. Or, FactInternetSales could be configured for DirectQuery but the underlying data source is not efficient for massive queries. This is where aggregations might help (contrary reasons for using aggregations is to compensate for bad design or inefficient DAX).
As a first step for setting up aggregations, you need to add a summarized table. Unlike MD, you are responsible for designing, populating and maintaining this table. Why not the MD way? The short answer is flexibility. It’s up to you how you want to design and populate the summarized table: ETL or DAX. It’s also up to you which measures you want to aggregate. And, the summarized table doesn’t have to be imported (it could be left in DirectQuery). You can also have multiple aggregations tables (more on this in a moment). In my case, I’ve decided to base the FactInternetSalesSummary table on a SQL view that aggregates the FactInternetSales data, but I could have chosen to use a DAX calculated table or load it during ETL. In my case, FactInternetSalesSummary aggregates sales at the Product and Date level, assuming I want to speed up queries at that grain. In real life, FactInternetSalesSummary would be hidden to end users so they are not confused which table to use.
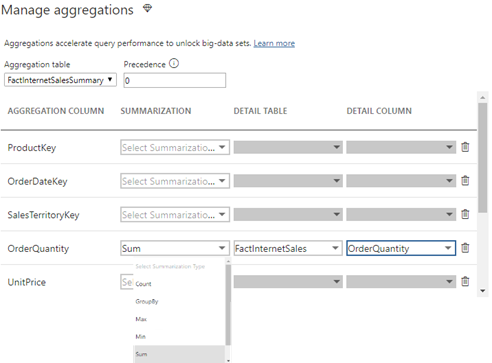
Note that a composite model has specific requirements for configuring dimension tables, which I discussed in my blog “Understanding Power BI Dual Storage“. For example, if FactInternetSalesSummary is imported but FactInternetSales is DirectQuery, DimProduct and DimDate must be configured in Dual storage mode. Once the aggregation table is defined, the next step is to define the actual aggregations. Note that this must be done for the aggregation table (not the detail table) so in my case this would be FactInternetSalesSummary. Configuring aggregations involves specifying the following configuration details in the “Manage aggregations” window:
Aggregation table – the aggregation table that you want to use for the aggregation design.
Precedence – in the case of multiple aggregation tables, you can define which aggregation table will take precedence (the server will probe the aggregation table that has a highest level first). Another feature that opens interesting scenarios.
Summarization function – Supported are Count, GroupBy, Max, Min, Sum, Count. If the aggregation table has relationships to dimension tables, there is no need to specify GroupBy. However, if the aggregation table can’t be joined to the dimension tables in a Many:1 relationship, GroupBy is required. For example, you might have a huge DirectQuery table where all dimension attributes are denormalized and another summarized table. Because currently aggregations don’t support M:M relationships, you must use GroupBy. Another usage scenario for GroupBy is for speeding up DistinctCount measures. If the column that the distinct count is performed is defined as GroupBy, then the query should result in an aggregation hit. Finally, note that derivative DAX calculations that directly or indirectly reference the aggregate measure would also benefit from the aggregation.
Detail table – which table should answer the query for aggregation misses. Note that Power BI can redirect to a different detail table for each measure. Even more flexibility!
Detail column – what is the underlying detail column.
The next step is to deploy the model and schedule the aggregation table for refresh if it imports data. Larger aggregate tables would probably require incremental refresh. Once the manual part is done, the server takes over. In the presence of one or more aggregation tables, the server would try to find a suitable table for aggregation hits. You can’t discover aggregation hits in the SQL Server Profiler by monitoring the existing MD “Getting Data from Aggregation” event. Instead, a new ” Query Processing\Aggregate Table Rewrite Query” event was introduced:
{
“table”: “FactInternetSales”,
“mapping”: {
“table”: “FactInternetSalesSummary”
},
“matchingResult”: “matchFound“,
“dataRequest”: [
}
To get an aggregation hit at the joined dimensions granularity, the query must involve one or more of the actual dimensions. For example, this query would result in an aggregation hit because it involves the DimDate dimension which joins FactInternetSalesSummary.
EVALUATE SUMMARIZECOLUMNS ( ‘DimDate'[CalendarYear], “Sales”, SUM ( FactInternetSales[SalesAmount] )
)
However, this query won’t result in an aggregation hit because it aggregates using a column from the InternetSales table, even though this column is used for the relationship to DimDate and the aggregation is at the OrderDateKey grain.
EVALUATE SUMMARIZECOLUMNS ( FactInternetSales[OrderDateKey], “Sales”, SUM ( FactInternetSales[SalesAmount] )
)
Aggregations are a new feature in Power BI to speed up summarized queries over large or slow datasets. Microsoft has designed aggregations with flexibility in mind allowing the modeler to support different scenarios.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-08-13 13:58:222021-02-17 01:02:03A First Look at Power BI Aggregations
The July release of Power BI Desktop introduced composite models, which I wrote about in my blog “Power BI Composite Models: The Good, The Bad, The Ugly” Composite models make data acquisition much more flexible but also more complex. A Power BI table can now be configured in one of these storage modes:
Import – The table caches the data. All Power BI features work.
DirectQuery – The table has only the metadata while the data is left at the data source. When users interact with the report, Power BI generates DAX queries to the Analysis Services server hosting the model, which in turn generates native queries to the data source. DirectQuery supports limited Power Query transformations and DAX functions in calculated columns, as described in more details here. Besides Power Query and DAX limitations, DirectQuery and Live Connections have feature limitations, as I discussed in my blog “Power BI Feature Discrepancies for Data Acquisition“.
Live Connection – This is a special case when Power BI connects directly to multidimensional data sources, such as Analysis Services, published Power BI Datasets and SAP Hana. The fact that Power BI doesn’t support DirectQuery against these data sources is the reason why composite models are not supported as well.
Dual – This is a new storage mode that deserves more attention.
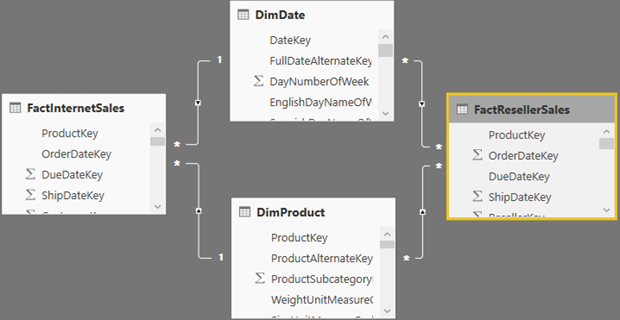
As the name implies, the dual storage mode is a hybrid between Import and DirectQuery. Like importing data, the dual storage mode caches the data in the table. However, it leaves it up to Power BI to determine the best way to query the table depending on the query context. Consider the following schema where all tables come from the same data source. Let’s assume the following configuration:
FactInternetSales is imported
FactResellerSales is DirectQuery
DimDate and DimProduct are Dual
Power BI will attempt the most efficient was to resolve the table joins. For example, if a query involves FactInternetSales and one or more of the dual dimensional tables, such as DimDate, the query would involve the DimDate cache. However, if the query involves FactResellerSales, Power BI will pass through the join. That’s because it would much more efficient to let the data source join the two tables in DirectQuery as opposed to bringing all the FactResellerSales table at the join granularity and then joining to the DimDate cache. In fact, Power BI will force you to change related dimension tables to Dual when it discovers hybrid joins among tables in the same data source. The following storage mode configurations are allowed between any two tables participating in M:1 join from a single data source:
Table on Many Side Is In
Table on One Side Must Be In
Dual
Dual
Import
Import or Dual
DirectQuery
DirectQuery or Dual
Therefore, a conformed dimension table must be configured for a Dual mode to join a fact table in Import mode and a fact table in DirectQuery mode.
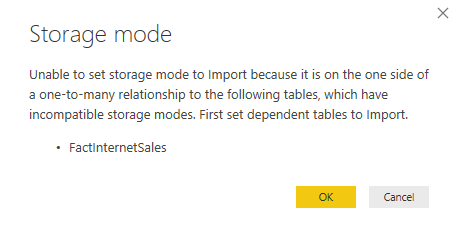
When Power BI Desktop detects an incompatible configuration, it may disallow the change. It may disallow the configuration because currently Power BI can’t switch from Import to any other storage mode.
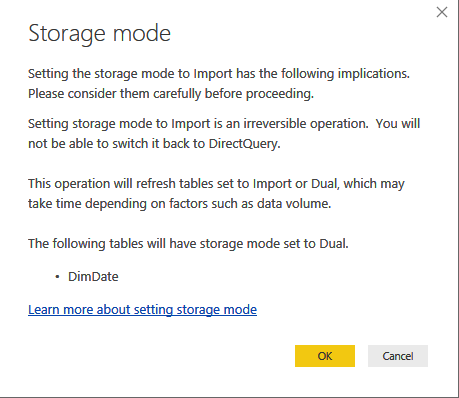
Or, it may ask you to switch storage modes it if finds a way to perform the change on its own.
Dual mode is important for tables coming from a single data source. Heterogeneous joins spanning two data sources would always result in a M:M relationship where the Power BI Mashup Engine will resolve the join. Specifically, when the joined table cardinality exceeds an undisclosed by Microsoft threshold, Power BI would perform the join on its own. For example, if DimDate is imported from Data Source A but FactResellerSales is DirectQuery in Data Source B, Power BI would send a direct query to group FactResellerSales to B at the join cardinality (e.g. DateKey), get the data, and then join the tables internally.
On my question why Power BI doesn’t handle the dual storage mode on its own by selecting the most efficient join, Microsoft replied that there are two reasons to delegate this task to the modeler and to make the Dual storage configuration explicit:
Like Import, Dual requires refresh, whereas DirectQuery doesn’t.
Apart from being able to revert to DirectQuery mode, Dual is subject to the same restrictions as DirectQuery.
Therefore, the modeler needs to be aware that the “switch” may result in requiring a data refresh or may result in a data a loss.
The Power BI dual storage mode is important when creating 1:M joins between tables in different storage modes from the same data model and for the forthcoming “Aggregations” feature, which I’ll cover in another blog. Although you need to know how Dual works, you don’t need to remember rules as Power BI Desktop will detect incompatible configurations. Composite models, heterogeneous M:M relationships, dual storage mode, and aggregations are Power BI-only features. At this point, Microsoft hasn’t announced when they will be available in Azure Analysis Services or SSAS Tabular.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-08-05 19:06:362018-08-05 19:25:48Understanding Power BI Dual Storage
If you haven’t done so, watch the “Power BI and the Future for Modern and Enterprise BI” presentation from the Business Applications Summit (July 22-24) to find where Microsoft is bringing Power BI in the next few months.
Power BI Service Scale and Adoption
19M data models hosted
58M monthly publish to web views
8M+ report and dashboard queries/hour
Power BI a top 10 fastest growing skill according to Upwork
Microsoft will extend Power BI by investing in three main areas:
Unified platform for both self-service and enterprise BI
Intuitive experience that drive a data culture
Pervasive Artificial Intelligence for BI
Here are most important forthcoming near-future features across these three areas:
Unified platform for both self-service and enterprise BI
Make Power BI Desktop a better tool for larger models — new diagram view with perspectives, multi-select fields to set common properties (it’s about time to have this feature), display folders as in SSAS
Aggregations – Ability to define aggregations as we can do in SSAS MD. The demo showed an impressive response time for summarized views on top of a 1 trillion row dataset.
Dataflows – dataflows refer to what was announced as “datapools” and Common Data Model for Analytics (review my comments here).
Modernized Visualizations pane (delivered in July 2018 release)
Report wallpaper (delivered in July 2018 release)
Out of box themes
Visual headers (delivered in July 2018 release)
Snap visual with other visuals
Expression-based formatting for every property in the Visualizations pane – This is huge and my users would rejoice to have more control over report properties!
Excel-like pivot tables
Export to PDF – most voted feature will finally be delivered
Pervasive Artificial Intelligence for BI
Quick Insights on right-click
Natural questions with suggestions
Quick insights inside natural questions results
Integration with Python – Connector and custom visuals like R
Sentiment analysis
Integration with Microsoft Cognitive Services – The demo showed the model deducing that the images of air conditioners in a hotel are broken
Better integration with Azure Machine Learning Studio
An impressive list of features indeed!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2018-07-28 14:05:362021-02-17 01:02:03Power BI News from the Microsoft Business Applications Summit
 Semantics relates to discovering the meaning of the message behind the words. In the context of data and BI, semantics represents the user’s perspective of data: how the end user views the data to derive knowledge from it. A modeler translates the machine-friendly database structures and terminology into a user-friendly semantic model that describes the business problems to be solved. To address this need, you create a semantic model. In my “
Semantics relates to discovering the meaning of the message behind the words. In the context of data and BI, semantics represents the user’s perspective of data: how the end user views the data to derive knowledge from it. A modeler translates the machine-friendly database structures and terminology into a user-friendly semantic model that describes the business problems to be solved. To address this need, you create a semantic model. In my “