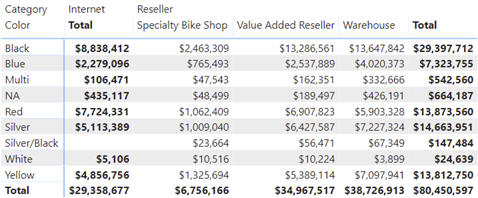
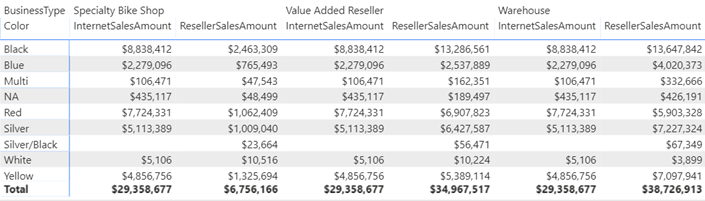
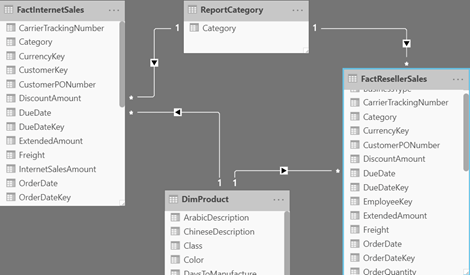
Filtering Power BI Visuals by Measure
Power BI lets you filter the visual data by a measure, such as by a measure that dynamically calculates the customer’s rank. This is convenient but there are performance implications related to the way Power BI autogenerates the DAX query. If a visual has a visual-level filter on a measure, Power BI Desktop defines a variable table filter that includes all measures in the visual. In the following example, the visual filters on the IncludedInRank measure, but the filter table includes all measures in the visual:
VAR __ValueFilterDM1 =
FILTER (
KEEPFILTERS (
SUMMARIZECOLUMNS (
‘Customer'[PARENT_NAME],
‘Customer'[Label_DM],
‘Customer'[VP_NAME],
__DS0FilterTable,
__DS0FilterTable2,
__DS0FilterTable3,
__DS0FilterTable4,
“Vol_Gr_WKND”, ‘NRT_PRR_Parent'[Vol_Gr_WKND],
“Vol_Gr_WE_Mon”, ‘NRT_PRR_Parent'[Vol_Gr_WE-Mon],
“Vol_Gr_WE_Tue”, ‘NRT_PRR_Parent'[Vol_Gr_WE-Tue],
“Vol_Gr_WE_Wed”, ‘NRT_PRR_Parent'[Vol_Gr_WE-Wed],
“Vol_Gr_WE_Thu”, ‘NRT_PRR_Parent'[Vol_Gr_WE-Thu],
“Vol_Gr_WE_Fri”, ‘NRT_PRR_Parent'[Vol_Gr_WE-Fri],
“WTD_Gr_ptc”, ‘NRT_PRR_Parent'[WTD_Gr_ptc],
“IncludedInRank”, IGNORE ( ‘NRT_PRR_Parent'[IncludedInRank] )
)
),
[IncludedInRank] = 1
)
As a result, these measures are evaluated twice: once in the filter table and twice in the main query (EVALUATE clause). This could definitely impact performance if the measures are slow to begin with. While waiting on Microsoft to provide more control over the autogenerated query, one approach to mitigate the performance impact is to use the Power BI-provided TOPN filter. In this example, instead of sorting and filtering on IncludedInRank to find the top N customers, you would apply a TOPN filter on Customer[Parent Name] based on the IncludedInRank measure. When TOPN is used, the autogenerated filter table will filter only on the measure used for TOPN, thus avoiding evaluating the rest of the measures.



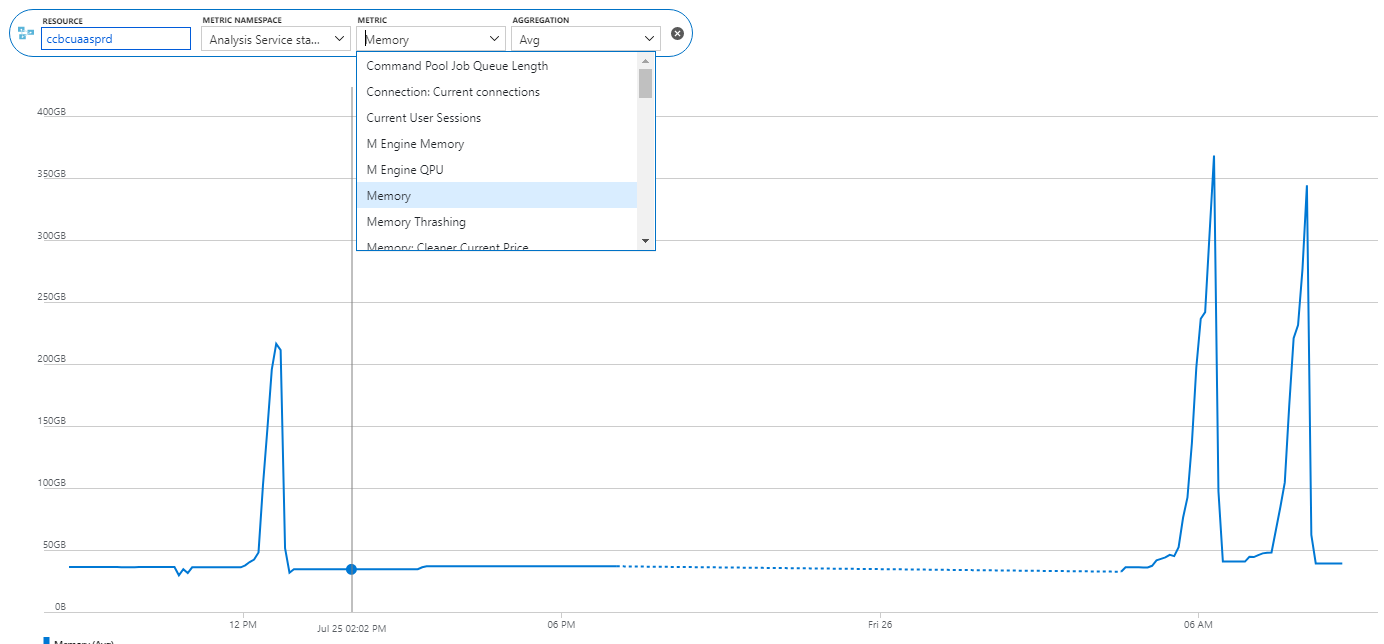
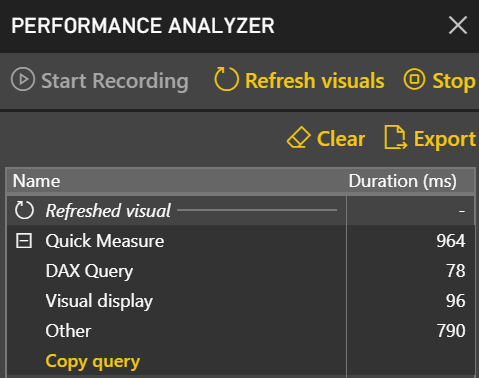
 After learning how to model the data properly (the most important skill), DAX would be the next hurdle in your self-service or organizational BI journey. You won’t get far in Microsoft BI without DAX. This letter shares a tip on how to identify DAX performance bottlenecks by using a recent feature in Power BI called Performance Analyzer.
After learning how to model the data properly (the most important skill), DAX would be the next hurdle in your self-service or organizational BI journey. You won’t get far in Microsoft BI without DAX. This letter shares a tip on how to identify DAX performance bottlenecks by using a recent feature in Power BI called Performance Analyzer. Before I get to Performance Analyzer, I’m excited to announce my latest book:
Before I get to Performance Analyzer, I’m excited to announce my latest book: