Take advantage of this exclusive opportunity to increase your data IQ from the comfort of your home wherever you are! Register today for my instructor-led digital training events and learn the Microsoft Power Platform consisting of Power BI, Power Apps, and Power Automate.
The workshops will be conducted online. Login instructions will be sent to registered attendees before the event.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-04-05 18:02:372020-04-05 18:02:37Two Virtual Workshops to Learn the Power BI Platform
MS BI fans, the time has come for a virtual meeting. Please join us online for the next Atlanta MS BI and Power BI Group meeting on Monday, April 6th, at 6:30 PM. I’ll show you how business analysts can apply AutoML in Power BI Premium to create predictive models. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Bringing Predictive Analytics to the Business User with Power BI AutoML (Virtual Meeting)
Conference bridge number 1 605 475 4300, Access Code: 208547
Overview:
With the growing demand for predictive analytics, Automated Machine Learning (AutoML) aims to simplify this process and democratize Machine Learning so business users can create their own basic predictive models. Join this presentation to learn how to apply AutoML in Power BI Premium to predict the customer probability to purchase a product. I’ll show you the end-to-end AutoML process, including:
· Create a dataflow
· Choose a field to predict
· Choose a model type
· Select input variables (features)
· Train the model
· Apply the model to new data
· Bonus: Integrate Power BI with AzureML
Speaker:
Through his Atlanta-based company Prologika (https://prologika.com), a Microsoft Gold Partner in Data Analytics, Teo Lachev helps organizations make sense of their most valuable asset: their data. His strategy formulation, trusted advisory and mentoring, design and implementation services empower clients to apply effectively data analytics in order to understand, improve, and transform their business processes. Teo has authored and co-authored several books on organizational and self-service data analytics, and he has been leading the Atlanta Microsoft BI and Power BI group since he founded it in 2010. Teo has been a Microsoft Most Valued Professional (MVP) Data Platform since 2004.
Prototypes without pizza:
Power BI latest features
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-04-02 21:19:322021-02-17 01:01:40Atlanta MS BI and Power BI Group Meeting on April 6th
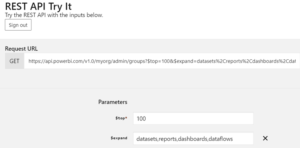
Power BI Service (powerbi.com) packs a graphical lineage view with the caveat that it only works within a workspace. As a Power BI admin, you may need a utility to inventory all Power BI artifacts published to all workspaces (including My Workspaces) in your Power BI tenant. Fortunately, the Admin – Groups GetGroupsAsAdmin can do the job in one call without any coding! Don’t be misled by “groups” in the API name as groups are equivalent to workspaces (the original V1 workspaces were joined by the hip with O365 groups so Microsoft got carried away here, which I’m sure they regret by now given than V2 workspaces decoupled from groups :-).
Go to the API page and click the “Try it” button (isn’t great that you can test any Power BI API without writing a single line of code?). Sign in with your Power BI credentials when prompted.
Enter a value for the $top parameter to limit the number of workspaces returned. It must be withing the 1-5000 range.
Add a $expand parameter and specify what artifacts you’re interested in. Make sure to click the plus next to the parameter to add it to the API call. In the example below, I request all Power BI artifacts: datasets, reports, dashboards, and dataflows
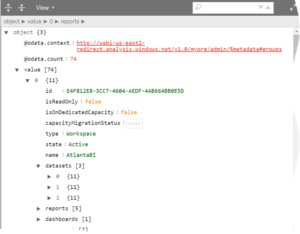
Next run the API and get the results as JSON. You can use one of the online JSON viewers, such as the Code Beautify JSON Viewer, to get a user-friendly view of the data. The Tree Viewer is particularly useful to drill down a workspace to items.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-03-22 15:28:182020-03-22 15:28:18Getting Lineage Across Power BI Tenant
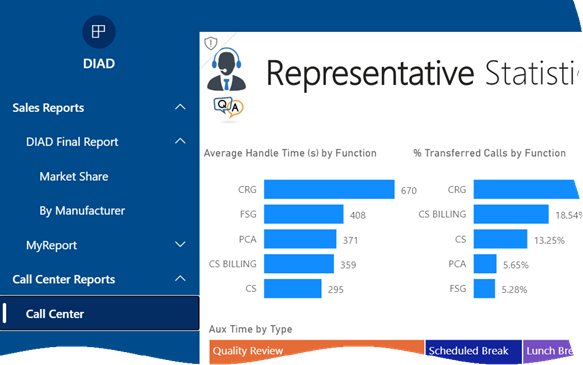
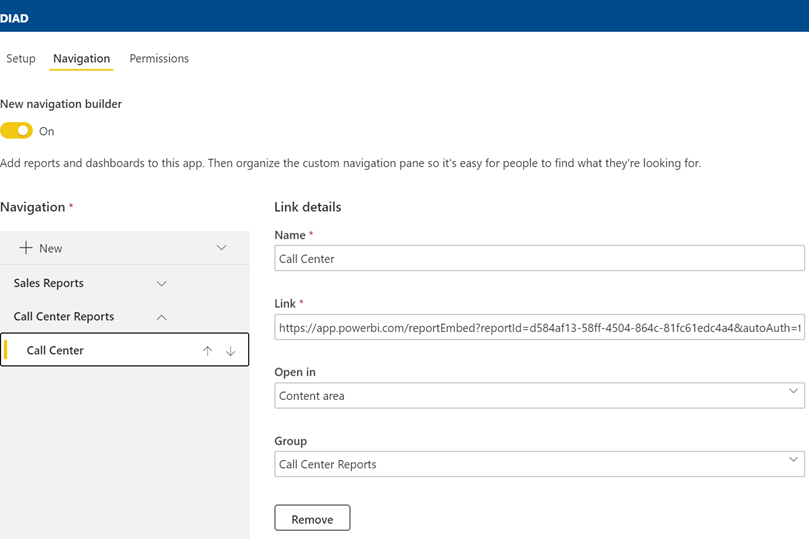
Scenario: Management has requested an easy way to view a subset of strategic reports located in different Power BI workspaces. You can ask the users to mark reports and dashboards as favorites so they can access pertinent content in the Favorites menu, but you’re looking for an easier configuration, such as to create a book of reports with a built-in navigation that organizes reports in groups (like a table of contents), such as the screenshot below demonstrates.
Workaround: Creating a Power BI app might be your best option. However, a long-standing limitation of apps is that there is 1:1 relationship between an app and a workspace. Therefore, by default all included content must come from the same workspace and you can’t create multiple apps in a workspace, such as to distribute content to different audiences.
But thanks to the upgraded navigation experience, an app can include links to reports in other workspaces if consumers have at least Viewer permission to these workspaces.
Start by deploying the core set of reports that you want to distribute to a workspace, such as an Executive Reports workspace. This workspace will serve as a base for the app.
Create an app. In the Navigation tab, the app will already include sections for each distributed report. Add links to reports in other workspaces and organize them in group.
To prevent external reports “losing” the navigation experience, specify the report embed URL which you can obtain by opening the report in Power BI Service, and clicking the Embed , “Website or portal” menu. Then, copy the URL (not the iframe element) and use it as the link.
Grant permission to the appropriate users or groups.
(Optional) Upload an image for the app logo so end users can tell the app apart from other apps.
Here is a configuration for a report residing in a different workspace. Notice that to preserve the navigation experience, the report is configured to open in the page content.
There are two main caveats of this approach:
Users must have permissions to the workspaces (except the app workspace) where the distributed reports reside. The app permissions you set up don’t propagate to content outside the app workspace.
App consumers are not isolated from changes to the external reports. By default, an app propagates content changes to included content only when the app is updated. End users will see changes to external content even if the app is not updated.
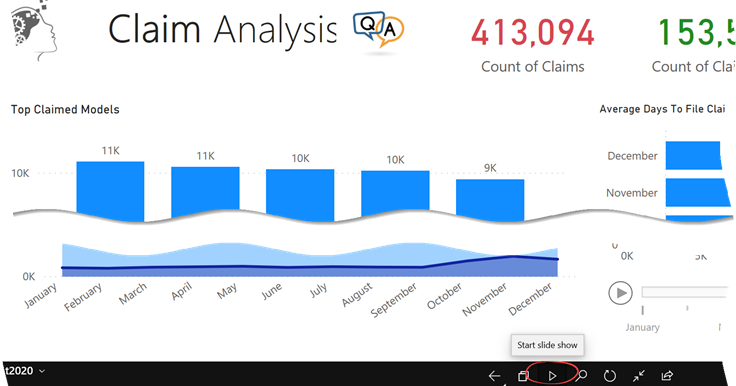
Scenario: You plan to display a Power BI report on a monitor. You want the report to automatically cycle through report pages, showing each after a configurable time delay, like a photo slide show.
Solution: There are at least two solutions to accomplish this:
The Microsoft-supported way is to install the Power BI Mobile for Windows and use its presentation mode feature, which is shown in the screenshot below.
Besides the built-in cross-filtering and cross-highlighting among visuals, Power BI supports two explicit filtering options: slicers and filters. Which one to use? Traditionally, you would use a slicer when you want the user to easily see what’s filtered on the report page. But with the introduction of the new filter pane and slicer enhancements, the choice becomes more difficult. Let’s compare the two options:
Criteria
Slicer
Filter
Placement
Report page (requires space on the page as other visuals)
Report pane
Filter target
Visual, page, report
Visual, page, report
Configuration
Drop-down, list, slider (numbers and dates), “buttons”
Passing a filter via JavaScript APIs to set default values cross-filters the slicer but doesn’t pre-select the slicer default value
Sets the filter as expected
A glaring gap for both filters and slicers is that you can’t currently set the default value programmatically, such as to default a date filter to the last date with data. As a workaround, you can add a field to the Date table, such as IsToday, that is set to Yes for the last date and prefilter on this field, but users must be educated to know how to remove the filter if they want to select another date. This is especially cumbersome with slicers, which don’t even support a single date selection, unless configured as a drop-down or Before/After.
Based on experience, people tend to rely mostly on slicers. But because it’s not uncommon to create reports that must be visually appealing on desktops and mobile devices, here are some recommendations to accommodate both large and small displays.
Use slicers judiciously because they take space on the report page. This could be an issue with mobile devices. Besides taking space, mobile users find it difficult to select values in slicers. I typically use slicers only for common filters, such as Date. Another scenario where slicers could be useful is when you need to visualize the items in a special way, such as a slider or to show a hierarchy of items.
Use filters for the rest of the filtering needs, especially if you plan to optimize reports for mobile viewing in portrait mode and/or use Power BI Embedded to embed reports.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-02-09 16:31:362020-02-15 14:27:18Power BI Slicers and Filters
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on February 3rd, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Shabnan Watson will discuss how to apply aggregations to Power BI DirectQuery datasets to improve report performance. Melissa will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Aggregations in Power BI
Date:
February 3rd, 2020
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
Aggregations are one of the most important optimization methods for managing big datasets in Power BI. Combined with Direct Query storage mode, they allow big datasets to be analyzed efficiently by answering high level analytical queries quickly from memory while sending more detailed queries back to the source database. In this session, you will learn about the concept of aggregations, different table storage modes in Power BI, different kinds of aggregation tables, how to configure aggregation tables so that they can answer high level user queries, and finally how to use tools such as DAX Studio or Extended Events to determine if the aggregations are actually being used.
Speaker:
Shabnam Watson is a Business Intelligence consultant with 18 years of experience developing data warehouse and BI solutions. Her work focus within the Microsoft BI Stack has been on Analysis Services and Power BI. She is an active member of PASS community and has spoken at PASS Summit, PASS SQL Saturdays, PASS Women In Technology Virtual Chapter, and other Local user groups. She is one of the organizers of SQL Saturday Atlanta and SQL Saturday Atlanta BI Edition. She holds a master’s degree in computer science, a bachelor’s degree in Computer Engineering, and a Certified Business Intelligence Professional (CBIP) certification by The Data Warehouse Institute (TDWI).
Sponsor:
Bad data is bad business. Melissa helps organizations profile, cleanse and verify, dedupe and enrich all their people data (name, address, email and phone number) and more. With clean, accurate and up-to-date customer information, organizations can monetize Big Data, improve sales and marketing, reduce costs and drive business insight. https://www.melissa.com/
Prototypes with Pizza
TBD
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-01-27 09:29:522021-02-17 01:02:03Atlanta MS BI and Power BI Group Meeting on February 3rd
Register for my full-day academy training at #PowerPlatformWT in Atlanta on Feb 10th for only $599 and learn how Power BI can bring your data to life!
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-01-15 15:21:512020-01-15 15:21:51Get Power BI Training at Power Platform World Tour
Although Power BI has been evolving for almost five years now, basic concepts are sometimes worth revisiting. Recently, I had a discussion regarding the Power BI Pro storage quota on the Power BI MVP list and I want to share the conclusions confirmed by Microsoft.
For workspaces in shared capacity licensed with Power BI Pro (not a workspace in a Premium capacity):
There is a per-workspace storage limit of 10 GB. So, My Workspace gets 10 GB and so does any org workspace.
There is also an unofficial cross-workspace aggregate quota of 10 GB * the number of Pro User Licenses intended as a backstop to prevent abuse so that a Pro user doesn’t keep on indefinitely creating workspaces to get new chunks of 10 GB. So, if you have 50 Power BI Pro users, the aggregate cross-workspace storage quota would be 500 GB irrespective if only one or multiple Pro users contribute. You won’t see the cross-workspace quota in the Power BI Service UI and it’s not exposed through service code.
BTW, you should ignore the “Manage data storage in Power BI workspaces” document until it’s been updated (the current timestamp is 12/20/2018). As it stands, this document contains wrong and incomplete information. For example, sharing datasets, reports, dashboards should have no effect on the workspace storage quota for consumers.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-01-07 09:52:232020-01-07 09:52:23Power BI Pro Storage Quota
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on January 6th, Monday, at 6:30 PM at the Microsoft office in Alpharetta. I’ll introduce to Power BI Premium Automated Machine Learning (AutoML). Prologika will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Power BI Automated Machine Learning (AutoML)
Date:
January 6th, 2020
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
With the growing demand for predictive analytics, Automated Machine Learning (AutoML) aims to simplify this process and democratize Machine Learning so business users can create their own basic predictive models. Join this presentation to learn how to apply AutoML in Power BI Premium to predict the customer probability to purchase a product. I’ll show you the end-to-end AutoML process, including:
· Create a dataflow
· Choose a field to predict
· Choose a model type
· Select input variables (features)
· Train the model
· Apply the model to new data
· Bonus: Integrate Power BI with AzureML
Speaker:
Through his Atlanta-based company Prologika (https://prologika.com), a Microsoft Gold Partner in Data Analytics, Teo Lachev helps organizations make sense of their most valuable asset: their data. His strategy formulation, trusted advisory and mentoring, design and implementation services empower clients to apply effectively data analytics in order to understand, improve, and transform their business processes. Teo has authored and co-authored several books on organizational and self-service data analytics, and he has been leading the Atlanta Microsoft BI and Power BI group since he founded it in 2010. Teo has been a Microsoft Most Valued Professional (MVP) Data Platform since 2004.
Sponsor:
Prologika is one of the most trusted names in Data Analytics. Our clients, from small businesses to Fortune 100 enterprises, derive tremendous value from our services. Our mission is to help organizations make sense of data by applying the latest technologies for descriptive and predictive analytics and get actionable insights. Your organization will spend less time mining for information and be better equipped to make sound business decisions. https://prologika.com
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2020-01-03 10:30:282021-02-17 01:02:03Atlanta MS BI and Power BI Group Meeting on January 6th