Know Thyself: Power BI Source Control
Last year my wife and I did a tour of Greece, and we had a blast. Greece, of course, is the place to go if you are interested in ancient history and the origin of democracy. One of the places we visited was Delphi. The ancient Greeks believed it to be the center of the universe. Now not much was left of it except lots of ruins and imagination. But back then it was magnificent. People from all over the world would come to consult with the Oracle of Delphi. She delivered her prophecies from the temple of Apollo, which had three inscriptions, with one of them being “Know thyself”. The practical benefit for the oracle was that if you believed her cryptic prophecy wasn’t fulfilled then your interpretation was wrong. Therefore, the problem was in you because you didn’t know yourself.
How does this translate into BI? I see clients overly excited about Microsoft Fabric/Power BI Premium, believing that bundling features will solve all their issues. But knowing your organization, ask yourself if your users would use all these features to justify the premium price. A case in point: Power BI source control via workspace Git integration: a feature that appear to be created from developers for developers. Kristyna Hughes did a great presentation for our Atlanta BI Group on Monday covering how developers can take the most of this feature.
Given the self-service focus of Power BI, however, I doubt that data analysts would subject themselves to learning Azure DevOps, Visual Studio Code, and Git CI/CD. Yet, Power BI source control has been in demand since the beginning with the most common ask – the ability to roll back changes.
Here is my take to simplify Power BI source control for regular users:
Power BI Premium/PPU/Fabric clients
- If you are on Power BI Premium, set up a branch for each workspace that you want to put under source control, and configure the workspaces for Git integration.
- Let business users publish changes as usual.
- Periodically and as a part of the change management process, the workspace admin approves the changes and commits them to source control. I hope one day Power BI would transparently commit changes to Git as Azure Data Factory does it, without requiring explicit synchronization. Meanwhile, the admin must manually commit.
- Someone privileged to Azure DevOps would need to roll back changes if needed. Again, I hope one day history review, compare, and roll back will be baked in Power BI.
Power BI Pro clients
- Once this feature is generally available, embrace Power BI Desktop projects.
- When significant changes are made, back up report and model.bim json files to some location, such as OneDrive which has built-in version control.
- Replace the project files when you need to roll back changes. Again, this “poor man” source control emphasizes simplicity and saves premium licenses.


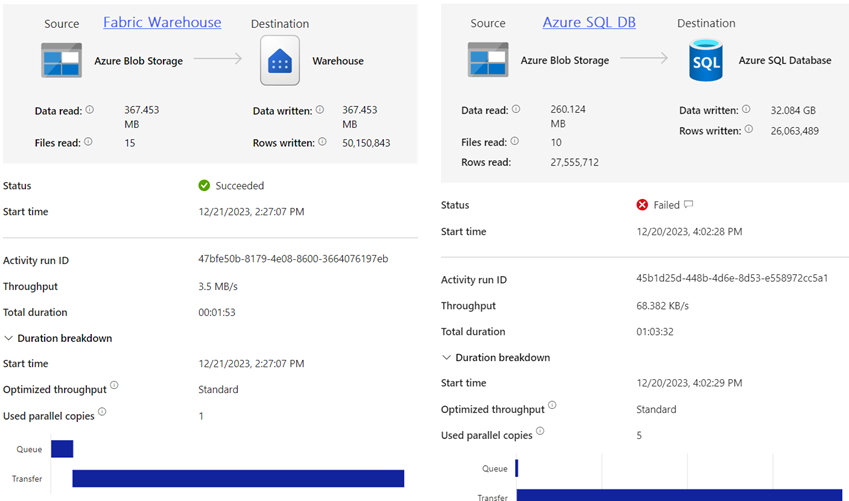
 I’ve covered my first impression about Microsoft Fabric in a
I’ve covered my first impression about Microsoft Fabric in a