Organized by Microsoft and Dynamic Communities, the Power Platform World Tour will take a place in Atlanta from 2/10-2/12, 2020. I’m teaching Power BI Dashboard in a Day (DIAD) on Feb 10 for a full day. Although this is a paid event ($599), you should get a great business value as the audience will probably be smaller and I’ll be able to provide more personal attention. Then, I’ll present “Bridge Analytics and Developer Worlds with Power Platform” on Feb 12 and show how Power BI can integrate with Power Apps to allow you to change the data behind a report.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-12-18 16:34:102019-12-18 16:34:10Power Platform World Tour
Power BI incremental refresh (a Power BI Premium feature) refreshes a subset of a table with imported data. The main goal is to reduce the refresh time so that new data becomes available online faster. Patrick LeBlanc has a great video about how to make the incremental refresh even more incremental by using the “Detect data changes” feature and he explains in detail how it works.
What if you want to fully refresh the dataset set up for incremental refresh? For example, you configure a table for incremental refresh periodically, but you want to fully process the dataset nightly, such as to pick the latest changes to dimensions. Currently, the only option to fully refresh the dataset with an incremental refresh policy is to republish the dataset and refresh it (this works because the first refresh is always full). When the XMLA endpoint becomes writeable, you’ll have the option to do so in an XMLA script. For example, the following script fully refreshes the InternetSales table without applying the refresh policy settings. Notice also the effectiveDate setting that allows you to overwrite the current date for testing purposes.
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on November 4, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Stacey Jones will present Power BI options with Python. Accelebrate will sponsor the meeting. And I will share some tips demoing the latest Power BI Desktop features, such as the new ribbon, decomposition tree and AI integration. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Integrating Power BI with Python
Date:
December 2nd, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
Python is well suited for Data Science and big data professionals. It has been voted as the most popular programming language in 2019. Microsoft made big investments in open-source R and Python, especially to extend Power BI. Join this session to learn how you can integrate Python with Power BI. Learn how to use Python in these ways:
· Use Python as a data source
· Transform data
· Produce beautiful visualizations
Speaker:
Stacey Jones specializes in mentoring and guiding firms in their efforts to build a modern Data, AI & BI governance programs that empower their business with Self-Service BI and Data Science capabilities. He currently serves as the Principal Data Solutions Architect at the Atlanta Microsoft Technology Center (MTC).
Sponsor:
Don’t settle for “one size fits all” training. Choose Accelebrate, and receive hands-on, engaging training precisely tailored to your goals and audience! Our on-site training offerings range from ASP.NET training and SharePoint training to courses on ColdFusion, Java™, C#, VB.NET, SQL Server, and more. Accelebrate.com
Prototypes with Pizza
“New ribbon, decomposition tree, and AI integration in Power BI Desktop” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-11-28 08:49:492021-02-17 01:02:02Atlanta MS BI and Power BI Group Meeting on December 2nd
At Ignite 2019 Microsoft announced the public preview of large datasets in Power BI Premium. This is a significant milestone as now datasets can grow up to the capacity’s maximum memory (previously, the max size was 10 GB with P3 plan), thus opening the possibility of deploying organizational semantic models to Power BI. I consider this feature mostly suitable for organizational BI as I don’t imagine business users dealing with such large data volumes. I tested large datasets during its private preview, and I’d like to share some notes.
The Good
Today, BI developers can deploy organizational semantic models to three Analysis Services Tabular SKUs: SQL Server Analysis Services, Azure Analysis Services, and now Power BI Premium. SQL Server Analysis Services is the Microsoft on-prem offering and it aligns with the SQL Server release schedule. Traditionally, Azure Analysis Services has been the choice for cloud (PaaS) deployments. However, caught in the middle between SQL Server and Power BI, the AAS future is now uncertain given that Microsoft wants to make Power BI as your one-stop destination for all your BI needs. From a strategic perspective, it makes sense to consider Power BI Premium for deploying organizational semantic models because of the following main benefits:
Always on the latest – Both AAS and SQL Server lag in features compared to Power BI Premium. For example, composite models and aggregations are not in SQL Server 2019 and Azure Analysis Services. By deploying to Power BI, which is also powered by Analysis Services Tabular, your models will always be on the latest and greatest.
Feature parity – As I explain in my “Power BI Feature Discrepancies for Data Acquisition” blog, some Power BI features, such as Quick Insights, Explain Increase/Decrease, Power Query, are not supported with live connections to Analysis Services. By hosting your models in Power BI Premiums, these features are now supported because Power BI owns the data, just like you import data in Power BI Desktop and then publish the model.
The Bad
As a Power BI Premium feature, large datasets will require planning and purchasing a premium capacity. Given that you need at least twice the memory to fully process a model (less memory should be required if you process incrementally), you must size accordingly. For example, a 15 GB model would require at least 30 GB of memory to fully process, bringing you into the P2 plan territory. Memory is the most important constraint for Tabular. Unlike SQL Server, which doesn’t license by memory (you can add as much memory you like without paying a dime more in licensing fees), Power BI Power BI Premium plans cap the capacity memory. So, you’ll end up having a dedicated P1 or P2 plan for hosting your organizational semantic model, and another P plan(s) for self-service BI.
I’d like to see elastic scaling happening to Power BI Premium at some point in future. Instead of boxing me into a specific plan, which more than likely will be underutilized, I’d like to see Power BI Premium scaling up and down on demand. This should help lowering the cost.
The Ugly
The lack of DevOps in Power BI Premium will put another hole into your budget. Unlike SQL Server, where you pay only for production use, no special DEV or QA environments and licensing options exist in Power BI Premium. So, you must plan for additional premium capacities, such as for three separate capacities: PROD, DEV, and QA (I know of organizations that need many more DevOps environments). At this price point, even large organizations will reconsider the licensing cost of hosting their models in Power BI. How about leaving QA and DEV on prem? This would require coding for the least common denominator which defeats the benefit of deploying to Power BI Premium. You can get innovative and attempt to reduce licensing cost by purchasing Azure A plans for DEV and QA and stopping the A capacities when they are not in use, but I wonder how many organizations will be willing to go through the pain of doing this. The Cloud should make things easier, right?
Large datasets will open another deployment option for hosting organizational semantic models. This might be an attractive option for some organizations and ISVs. Others will find that staying on-prem could lower their licensing cost. Once the Power BI Premium XMLA endpoint supports write operations (promised for December 2019 in the roadmap), BI developers can use a tool of their choice, such as Tabular Editor or Visual Studio (I personally find Power BI Desktop not suitable for organizational model development, mainly because of its slow performance, lack of source control and extensibility) to develop and deploy semantic models that are always on the latest features and unifying BI on a single platform: Power BI.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-11-10 10:24:122019-11-10 10:24:12Power BI Large Datasets: The Good, the Bad, and the Ugly
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on November 4, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Andy Lawrence will share best practices for impactful Power BI Dashboards. CCG Analytics will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Best Practices for Impactful Power BI Dashboards
Date:
November 4, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
Power BI is gaining momentum as a preferred tool for dashboards and interactive reports. Let’s revisit some best practices for dashboard development, such as:
· The importance of form and function
· Facilitating user adoption
· Mistakes that everyone makes
· Fast shortcuts for clean reports
· Hidden settings that are lifesavers
· Best Power BI updates of 2019
· Live demo of a fast dashboard build
· Questions
Speaker:
Andy Lawrence is a senior Power BI consultant at CCG Analytics and the leader of the Tampa Power BI user group. He’s a Florida native and a proud UF Gator (MBA) and USF Bull (MIS). At CCG he provides guidance on data modeling, tabular environments, azure administration, DAX writing, T-SQL and data visualization best practices. All of which he can expand upon if you have questions during his presentation.
Sponsor:
CCG specializes in deploying solutions that not only provide value to the business but are adopted by users ensuring accountability of the IT driven system. Moving beyond reporting, our Business Intelligence solutions support data governance, quality and standardization across the organization and enable stakeholders with tools like predictive analytics, user-defined alerts, data mining, what-if analysis and visually appealing dashboards.
Prototypes with Pizza
“Lineage view” by Teo Lachev
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-10-31 08:11:272021-02-17 01:02:02Atlanta MS BI and Power BI Group Meeting on November 4th
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on October 7, Monday, at 6:30 PM at the Microsoft office in Alpharetta. Qubole will show us how Presto, Azure Data Lake, and Power BI can be used to analyze Big Data. Qubole will sponsor the meeting. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Leveraging Power BI on Presto for the Azure Data Lake
Date:
October 7, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
Presto is a distributed ANSI SQL engine designed for running interactive analytics queries. Presto outshines other data processing engines when used for business intelligence (BI) or data discovery because of its ability to join terabytes of unstructured and structured data in seconds, or cache queries intermittently for a rapid response upon later runs. Presto can also be used in place of other well-known interactive open-source query engine such as Impala, Hive or traditional SQL data warehouses. Attend this event to learn:
· Why Presto is better suited for ad-hoc queries than other engines like Apache Spark
· How to jumpstart analysts across your organization to harness the power of your big data
· How to generate interactive or ad hoc queries or scheduled reports using Presto
· Real-world examples of companies using Presto
Speaker:
Man Zhang is a Solutions Architect at Qubole. He has 20+ years in software systems architecture, development, and integration and 4+ years in Big Data architecture. https://www.linkedin.com/in/man-zhang-34a887/
Sponsor:
Qubole delivers a Self-Service Platform for Big Data Analytics built on Amazon Web Services, Microsoft and Google Clouds. We were started by the team that built and ran Facebook’s Data Service when they founded and authored Apache Hive. With Qubole, a data scientist can now spin up hundreds of clusters on their public cloud of choice and begin creating ad hoc and/or batch queries in under five minutes and have the system autoscale to the optimal compute levels as needed. Please feel free to test Qubole Data Services for yourself by clicking “Free Trial” on the website.
Prototypes with Pizza
TBD
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-10-01 14:24:072021-02-17 01:02:02Atlanta MS BI and Power BI Group Meeting on October 7th
We all need to share. But until a couple of months ago, a Power BI training or assessment wouldn’t be complete unless I got hammered on the Power BI sharing limitations. Fortunately, Microsoft has addressed most of these and I have now a much better story to tell. And this is the subject of this newsletter.
You can now control who can create workspaces in the Power BI Admin center
Group membership limitations
V2 workspaces support all O365 group types
Coarse content access level
Contributor and Viewer roles
No cross workspace sharing
A dataset can be shared across workspaces
No data governance
A dataset can be promoted and certified
Power BI Premium sharing with viewers require report sharing or apps
The Viewer role supports sharing with viewers
Only one app supported per workspace
The Viewer role deemphasizes apps
No nesting support (subfolders)
Sharing Best Practices
Given the current state of Power BI, I’d like to share some best practices for organizing and sharing content:
Don’t use report and dashboard sharing as it can quickly turn into a maintenance nightmare.
Create workspaces to reflect your organizational functional areas, e.g. Sales, HR, Finance. Unfortunately, workspaces still don’t support subfolders (Microsoft hinted that they are working on such a feature), so for now you must resort to a flattened list.
Instead of individual user assignments, add users to security groups and then add these groups as members to the workspace. This way, when the user leaves and company or moves to another department, you only need to change the user’s group membership without making changes to the workspace security policy.
Come up with data governance policy. The Power BI data governance story is work in progress, but you can set up some ground rules. For example, once a contributor believes that a dataset is ready for a broader consumption, he can promote the dataset. Then, IT can verify the dataset and certify it. Currently, Power BI supports certifying only datasets (reports and dashboards aren’t certifiable yet).
This one is hard. Teach data analysts best data modeling practices. Instead of creating a dataset per report, they should create a data model that correctly represents their subject area. A data analyst should create the model once so it can support multiple reports. Once the dataset is published and certified, users can create their own reports.
Although Microsoft is pushing apps very hard and adding some nice features, such as navigation, a standing limitation is that you can create only one app per workspace. So, you can’t publish multiple apps from a workspace, such as to share some reports with one group of users and another set with a different group. Instead, grant access directly to workspaces by using the Contributor and Viewer roles. The Viewer role lifts a significant limitation that forced you to use report/dashboard sharing or apps to share content out of a premium workspace with viewers. If you want to share the entire content of the workspace, you don’t have to use apps. Instead, you can simply add users or groups as viewers to the workspace.
Despite some long standing limitations, Power BI sharing is coming out of age. Follow the above practices and you’ll have now a much better way to organize and share content.
Teo Lachev
Prologika, LLC | Making Sense of Data
Microsoft Partner | Gold Data Analytics
MS BI fans, join us for the next Atlanta MS BI and Power BI Group meeting on September 10, Tuesday, at 6:30 PM at the Microsoft office in Alpharetta. This is a meeting not to miss. A DAX founder, Jeffrey Wang (Principal Software Engineer Manager at the Power BI product group) is coming all the way from Seattle to share DAX best practices with our group! Captech Consulting will sponsor the event. For more details, visit our group page and don’t forget to RSVP (fill in the RSVP survey if you’re planning to attend).
Presentation:
Common DAX Patterns
Date:
September 10, 2019
Time
6:30 – 8:30 PM ET
Place:
Microsoft Office (Alpharetta)
8000 Avalon Boulevard Suite 900
Alpharetta, GA 30009
Overview:
We will learn common DAX patterns by examining several issues frequently reported by DAX users through PowerBI customer support tickets. Users will be able to:
1. Learn from mistakes made by other DAX users so you can avoid them in your own work.
2. Learn the common techniques to debug DAX problems.
3. Learn the best DAX patterns to solve common problems.
4. Gain deeper understanding of DAX by learning relevant history and underlying design of the programming language.
5. Ask me their own DAX questions
Speaker:
Currently working as Principal Software Engineer Manager at Microsoft, Jeffrey Wang stumbled upon BI after the Y2K bubble burst, fell in love with the field, and stayed in the industry ever since. After I joined Microsoft Analysis Services engine team in 2004, I quickly discovered that working on the programming language is the best way to stay close to the end users, so I joined the MDX formula engine team. After shipping a couple of releases of SQL Server Analysis Services, I joined the committee that created DAX. Today I lead the development effort of the DAX engine and the modeling engine inside the Power BI product group.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-09-03 20:36:472021-02-17 01:02:01Atlanta MS BI and Power BI Group Meeting on September 10th
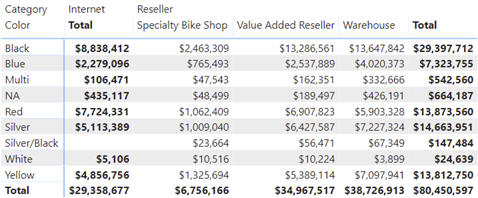
A recent requirement called for an asymmetric crosstab report in Power BI. Transitioned to Adventure Works, the final report looks like this.
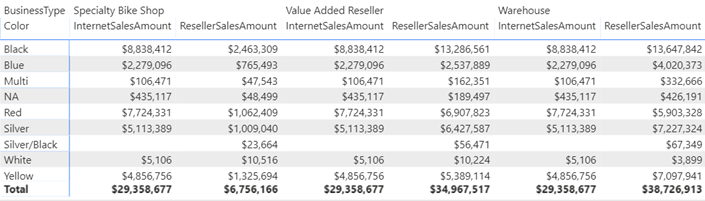
The Internet column shows the sales amount from FactInternetSales. Then, the matrix pivots on the BusinessType column in the FactResellerSales. Because, Internet sales don’t relate to BusinessType, it doesn’t make sense to pivot it. Instead, we want to show Internet sales in a single static column before the crosstab portion starts.
Implementing such a report in SSRS is easy thanks to its support of adjacent groups and static columns but not so much in Power BI. The issue is that Matrix would happily pivot both measures and the InternetSalesAmount would be repeated for each business type.
Fortunately, with some blackbelt modeling and DAX, we can achieve the desired effect. I attached the pbix file and here are the high-level implementation steps:
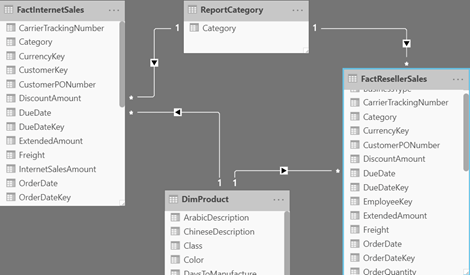
Add a ReportCategory table (you can use the Enter Data feature), with a single column Category and two values: Internet and Reseller. Add a Category calculated column to FactInternetSales with a value of “Internet”. Add a Category calculated column to FactResellerSales with a value of “Reseller”. Create relationships FactInternetSales[Category]->ReportCategory and FactResellerSales[Category]->ReportCategory. These relationships are required because Matrix doesn’t support unrelated tables. Your model schema should look like this:
Create a SalesAmount measure with the following formula:
SalesAmount = IF(SELECTEDVALUE('ReportCategory'[Category]) = "Internet" && NOT ISINSCOPE('FactResellerSales'[BusinessType]),
SUM(FactInternetSales[InternetSalesAmount]),
SUM(FactResellerSales[ResellerSalesAmount]))
The IF condition checks if the measure is under the Internet category. NOT ISINSCOPE(‘FactResellerSales'[BusinessType]) will return TRUE only for the total column in the Internet section. Otherwise, it will return the reseller sales. Because there are no reseller sales in the Internet category, only Internet sales will be shown. Note that SELECTEDVALUE will return FALSE for empty cells which is why I had to create the ReportCategory table.
Add Matrix viz and bind Product[Color] to rows, ReportCategory[Category] and ResellerSales[BusinessType] on columns, and SalesAmount in Values. Expand the columns to the next level (to show the BusinessType level).
In the Matrix format properties, go Subtotals, enable the “Per column” setting, and turn off the Category subtotal to avoid showing the reseller sales total twice.
Although Power BI has made great progress on the visualization side of things, it still lacks in flexibility. The two features that miss the most from SSRS are nesting visuals (to create repeat sections) and the flexible Matrix layout. However, with some black belt modeling and DAX, workarounds are possible.
https://prologika.com/wp-content/uploads/2016/01/logo.png00Prologika - Teo Lachevhttps://prologika.com/wp-content/uploads/2016/01/logo.pngPrologika - Teo Lachev2019-08-24 18:14:202019-08-24 18:14:20Implementing Asymmetric Crosstab in Power BI
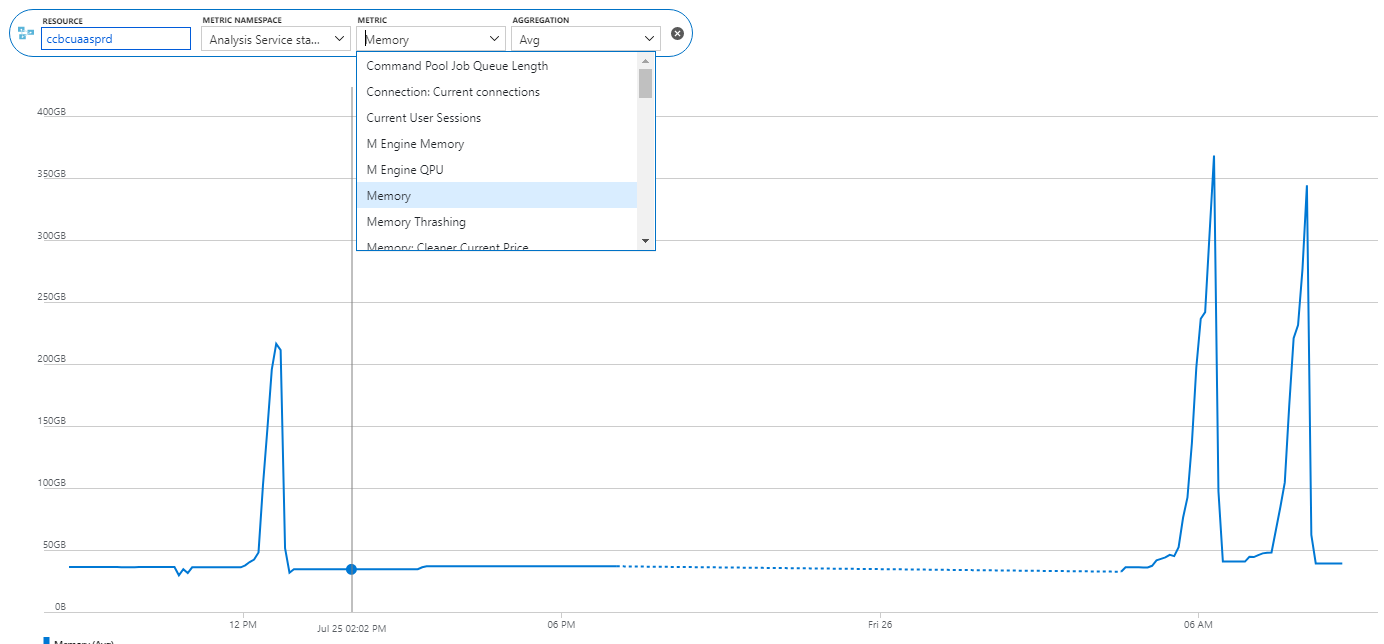
Scenario: A client reports a memory spike during processing. They have a Tabular semantic model deployed to Azure Analysis Services. They fully process the model daily. The model normally takes less than 50 GB RAM but during processing, it spikes five times and Azure Analysis Services terminates the processing task complaining that it “reached the maximum allowable memory in our pricing tier”. Normally, fully processing the model should take about twice the memory but five times?
Solution: Upon expecting the model design, I discovered that the client has decided to add (many) calculated columns to the two fact tables in the model. Most of these columns are used to calculated variances to prior year. The formulas contain DATESYTD and other DAX date-related functions. After data is read, Tabular processes calculated columns, relationships and hierarchies. In this case, the spike was due to calculations involving large time ranges and ineffective DAX expressions. Converting these columns to measures resolved the issue.
As a best practice, abstain from using calculated columns (especially in fact tables). Make sure you understand the difference between measures and calculated columns (I cover this extensively in my latest book “Applied DAX with Power BI“). If you do need expression-based columns, such to materialize expensive calculations, consider defining them upstream, such as in SQL views or Power Query.




 We all need to share. But until a couple of months ago, a Power BI training or assessment wouldn’t be complete unless I got hammered on the Power BI sharing limitations. Fortunately, Microsoft has addressed most of these and I have now a much better story to tell. And this is the subject of this newsletter.
We all need to share. But until a couple of months ago, a Power BI training or assessment wouldn’t be complete unless I got hammered on the Power BI sharing limitations. Fortunately, Microsoft has addressed most of these and I have now a much better story to tell. And this is the subject of this newsletter.